







CLAUDE.md를 깔아두면 클로드 코드(Claude Code)가 더 똑똑해진다는 말은 사실일까. 같은 시기에 발표된 두 편의 논문은 같은 질문을 검증한 끝에 서로를 부정하는 답을 내놓았다. 한쪽은 같은 종류의 파일을 깔았더니 작업 시간이 28% 짧아졌다고 했고, 다른 쪽은 정답률이 오히려 떨어지고 비용은 20% 이상 늘었다고 했다.
이 글은 싱가포르경영대(Singapore Management University) 룰라(Lulla) 연구팀과 취리히연방공대(ETH Zurich) 글로아강(Gloaguen) 연구팀이 발표한 두 편의 컨텍스트 파일 효과 분석 보고서를 따라, 클로드 코드 사용자가 이미 한 번쯤 깔아둔 그 파일이 정말 도움이 되는지, 어떻게 써야 하는지를 짚는다.
같은 파일을 두고 정반대로 갈린 두 보고서
CLAUDE.md는 클로드 코드가 저장소를 분석하기 전에 먼저 읽는 마크다운 파일이다. 코덱스(Codex)에서는 같은 역할을 AGENTS.md가 맡고, 깃랩 듀오(GitLab Duo)와 큐원 코드(Qwen Code)도 AGENTS.md를 표준 형식으로 받아들였다. 이름만 다를 뿐 같은 종류의 'AI용 README'다. 2026년 1월 기준 6만 개가 넘는 공개 깃허브(GitHub) 저장소가 이 두 파일 중 하나를 포함하고 있다. 그런데 ICSE JAWs 2026 워크숍에 발표된 룰라 등의 논문은 이 파일이 있을 때 코덱스 작업 완료 시간이 평균 20.27%, 중간값으로 28.64% 줄었다고 보고했다.
비슷한 시기 ETH 취리히와 로직스타AI(LogicStar.ai)가 공개한 글로아강 등의 논문은 정반대 신호를 보냈다. 같은 종류의 파일을 깔았더니 추론 비용이 20% 이상 늘었고, AI가 자동으로 만든 컨텍스트 파일을 사용한 8개 실험 환경 중 5개에서 정답률이 도리어 떨어졌다는 결과다. 같은 파일을 두고 한쪽은 "쓰면 효율적이다", 다른 쪽은 "쓰면 손해다"라고 말한 셈이다. CLAUDE.md를 둘러싼 질문은 곧 두 결과 중 어디에 무게를 둘 것인지로 바뀐다.
찬성 측 근거, 작업 시간 28.64% 단축과 토큰 1,153개 절감
"쓰는 게 맞다"라는 쪽의 근거는 시간과 토큰 소비다. 룰라 등 연구진은 깃허브 풀 리퀘스트(Pull Request) 124건을 추려, 같은 작업을 AGENTS.md가 있을 때와 없을 때로 짝지어 코덱스에 돌렸다. AGENTS.md가 없을 때 평균 작업 시간은 162.94초였지만, 있을 때는 129.91초로 33초가량 줄었다. 중간값으로는 98.57초에서 70.34초로 떨어졌다. 출력 토큰도 평균 5,744개에서 4,591개로 약 1,153개가 빠졌다. 한 작업당 30초 짧아지는 차이가 사소해 보일 수 있지만, 깃허브 액션(GitHub Actions)처럼 하루 수천 건의 자동 작업을 돌리는 환경에서는 무시할 수 없는 누적 비용이 된다.
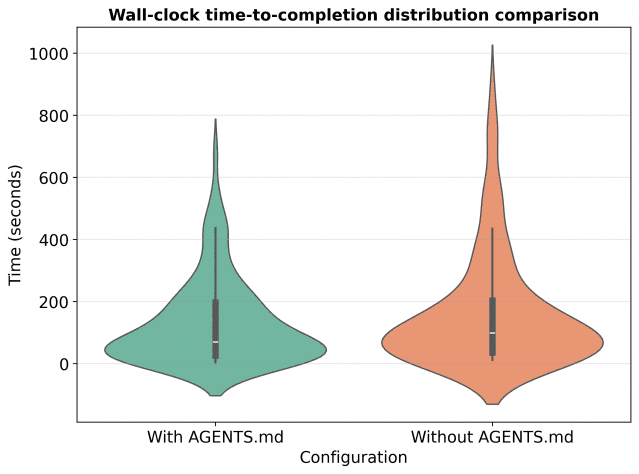
그림1. AGENTS.md 유무에 따른 코딩 에이전트의 작업 완료 시간 분포 비교
연구진은 "AGENTS.md가 저장소 구조와 컨벤션을 미리 알려주기 때문에 에이전트가 처음부터 파일 트리를 헤집고 다닐 필요가 줄어든다"라고 해석했다. 사전 안내서가 있으면 AI가 길을 헤매지 않고, 같은 결과물을 더 짧은 시간에 내놓는다는 이야기다. 클로드 코드 사용자가 CLAUDE.md를 두는 가장 큰 이유 역시 이 효율성 개선에 가깝다.
반대 측 근거, 정답률 하락과 비용 23% 증가
"쓰지 말라"는 쪽의 근거는 정답률과 비용이다. ETH 취리히 연구진은 AGENTBENCH라는 새 벤치마크를 만들고, 클로드 코드(Sonnet-4.5), 코덱스(GPT-5.2), 코덱스(GPT-5.1 Mini), 큐원 코드(Qwen3-30B-Coder) 등 4종 코딩 에이전트 구성을 138개 실제 깃허브 이슈에 풀게 했다. 클로드 코드에는 CLAUDE.md를, 나머지 세 에이전트에는 AGENTS.md를 그대로 넣고 같은 효과를 측정했기 때문에, 이 결과는 곧 CLAUDE.md 사용자가 마주하게 될 현실이기도 하다.
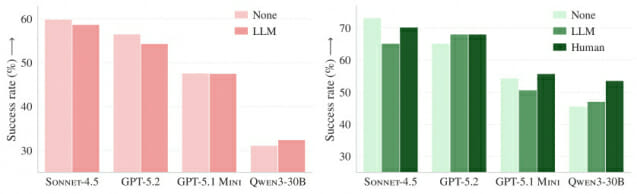
그림2. 컨텍스트 파일 유무에 따른 4종 코딩 에이전트 정답률 비교
결과는 차가웠다. AI가 자동 생성한 컨텍스트 파일을 넣었더니 SWE-bench Lite에서는 0.5%포인트, AGENTBENCH에서는 2%포인트씩 정답률이 떨어졌다. 사람이 직접 작성한 컨텍스트 파일을 넣어도 평균 4%포인트 정도의 미세한 개선에 그쳤다. 더 충격적인 부분은 비용이다. 작업당 평균 단계 수는 LLM 생성본이 있을 때 2.45~3.92단계 늘었고, 그 결과 비용은 SWE-bench Lite에서 20%, AGENTBENCH에서 23% 증가했다. GPT-5.2는 같은 조건에서 추론 토큰을 22% 더 썼다. 빨라지긴 했지만 결과물이 더 나아진 건 아니라는 신호다.
AI가 매뉴얼을 너무 충실히 따른다는 역설
두 논문이 엇갈린 답을 내놓은 이유는 측정 항목이 달랐기 때문이다. 룰라 등은 "얼마나 빨리 끝나느냐"만 들여다봤고, 글로아강 등은 "얼마나 옳게 끝나느냐"까지 확인했다. 두 결과를 겹쳐 읽으면 한 가지 그림이 떠오른다. CLAUDE.md는 에이전트가 저장소를 탐색하는 시간을 줄여주지만, 동시에 AI가 따라야 할 지시 사항을 늘린다. ETH 취리히 연구진은 "지시 사항이 많아지면 모델이 그것을 지키느라 더 많이 사고하고 더 많이 검사한다"라고 설명했다. 실제 측정에서도 이 가설이 그대로 드러났다.
CLAUDE.md나 AGENTS.md에 'uv'라는 패키지 매니저 사용법이 적혀 있으면 에이전트는 이 명령을 평균 1.6회 호출했지만, 적혀 있지 않을 때는 0.01회 미만으로 떨어졌다. AI가 매뉴얼을 너무 충실히 따르는 것이 문제다. 매뉴얼이 길고 까다로울수록 따라야 할 동작이 늘어나고, 추론 시간도 비용도 함께 부풀어 오른다.
흥미로운 예외도 있다. ETH 연구진이 저장소에서 README와 docs 폴더 등 모든 문서를 지우고 컨텍스트 파일만 남겼더니, AI가 자동 생성한 컨텍스트 파일조차 정답률을 평균 2.7%포인트 끌어올렸다(코덱스·큐원 코드 기준, 클로드 코드는 비용 문제로 이 실험에서 제외). CLAUDE.md를 비롯한 컨텍스트 파일이 빛을 발하는 순간은 다른 문서가 부실한 저장소, 곧 신생 프로젝트나 작은 라이브러리 쪽일 가능성이 크다.
실전 가이드, 짧고 단단하게 쓰는 게 답이다
그렇다면 "CLAUDE.md를 쓰는 게 맞습니까"에 대한 답은 "쓰지 말자"가 아니라 "어떻게 쓰느냐"로 바뀐다. 두 논문이 동시에 가리키는 방향은 의외로 좁다. 사람이 짧고 단단하게 쓴 CLAUDE.md는 정답률을 약간 끌어올리고, 길고 자동 생성된 CLAUDE.md는 비용만 키운 채 정답률을 거의 못 올린다. ETH 연구진은 논문 결론에서 "사람이 작성하는 컨텍스트 파일은 최소한의 요구사항만 담아야 한다"라고 못 박았고, 룰라 연구진도 효율 개선을 "에이전트가 저장소 구조를 추측하는 데 드는 시간을 줄였기 때문"이라고 분석했다. 이를 종합하면 CLAUDE.md를 쓰는 가장 안전한 방법은 빌드 명령어, 패키지 매니저, 핵심 디렉터리 구조처럼 'AI가 코드만 보고 알기 어려운 정보'를 중심으로 짧게 적어두는 것이다.
클로드 코드의 /init 명령으로 자동 생성한 두꺼운 CLAUDE.md를 그대로 두거나, 이미 코드에 적혀 있는 컨벤션을 다시 옮겨 적은 디렉터리 트리형 CLAUDE.md는 효과가 미미할 가능성이 있다. 한 줄로 줄이면, CLAUDE.md를 쓰는 게 맞느냐는 질문의 답은 '쓰되 짧게'다. 향후 모델이 컨텍스트 파일에 어떻게 반응하도록 학습되느냐에 따라 같은 파일이 도움이 될지 짐이 될지가 갈릴 것으로 보인다.
FAQ( ※ 이 FAQ는 본지가 리포트를 참고해 자체 작성한 내용입니다.)
Q1. 결국 CLAUDE.md를 깔지 말지 바로 답해주실 수 있나요?
"무조건 깔아라"도, "절대 깔지 마라"도 정답은 아닙니다. ICSE JAWs 2026의 한 논문은 CLAUDE.md와 같은 종류의 컨텍스트 파일이 작업 시간을 평균 20% 줄였다고 밝혔지만, ETH 취리히의 다른 논문은 같은 파일이 정답률을 0.5~2%포인트 떨어뜨리고 비용을 20% 이상 늘렸다고 보고했습니다. 결국 핵심은 깔지 말지가 아니라 어떻게 쓰느냐입니다.
Q2. CLAUDE.md와 AGENTS.md는 같은 파일인가요?
역할은 같지만 이름이 다릅니다. 클로드 코드(Claude Code)는 CLAUDE.md를, 코덱스(Codex)와 깃랩 듀오, 큐원 코드는 AGENTS.md를 표준으로 읽습니다. 두 파일 모두 AI 코딩 에이전트에게 프로젝트 구조와 컨벤션을 미리 알려주는 'AI용 README'이며, 2026년 1월 기준 6만 개가 넘는 공개 깃허브 저장소가 둘 중 하나를 사용하고 있습니다.
Q3. 실전에서 CLAUDE.md는 어떻게 써야 하나요?
연구 결과를 종합하면 사람이 직접 짧고 명확하게 작성한 컨텍스트 파일이 가장 안정적인 효과를 보였습니다. 빌드 명령어, 패키지 매니저, 프로젝트의 핵심 디렉터리처럼 AI가 코드만 보고 알기 어려운 정보를 중심으로 최소한의 요건만 적어두는 방식이 권장됩니다. 자동 생성 도구로 만든 길고 두꺼운 CLAUDE.md는 오히려 비용만 늘릴 수 있어 주의가 필요합니다.
▶ 기사에 인용된 리포트 원문은 arXiv와 arXiv에서 확인할 수 있다.
▶리포트명1: On the Impact of AGENTS.md Files on the Efficiency of AI Coding Agents (Lulla et al., ICSE JAWs 2026)
▶리포트명2: evaluating AGENTS.md: Are Repository-Level Context Files Helpful for Coding Agents? (Gloaguen et al., 2026)
▶ 이미지 출처: AI 생성 콘텐츠
▶ 해당 기사는 챗GPT와 클로드를 활용해 작성되었습니다.
■ 이 기사는 AI 전문 매체 ‘AI 매터스’와 제휴를 통해 제공됩니다. 기사는 클로드 3.5 소네트와 챗GPT를 활용해 작성되었습니다. (☞ 기사 원문 바로가기)





