AI 생성 이미지에서 조명을 바꾸려면 먼저 3D 장면 구조를 복원해야 한다는 것이 그동안의 상식이었다. 그러나 예일대학교(Yale University)와 어도비(Adobe)가 2026년 4월 공개한 연구는 정반대 방향으로 움직였다. 3D 재구성을 아예 건너뛰고, 빛의 속성을 '토큰(Token)' 단위로 잘게 쪼개 모델에 집어넣는 방식이다. 이렇게 훈련된 토큰라이트(TokenLight)는 호박 안쪽에 가상 조명을 넣거나 투명 유리 뒤에서 역광을 만들어내면서도 원본 피사체의 얼굴과 재질을 무너뜨리지 않는다. 생성형 AI가 어떻게 얼굴의 일관성을 지키면서 빛만 자유자재로 옮길 수 있는지 궁금했던 사용자에게 이 연구는 그 메커니즘의 뼈대를 처음으로 공개했다.

그림1. 즉각적이고 유연하게 이미지 조명 수정이 가능한 토큰라이트
3D 재구성 건너뛴 조명 편집, 기존 상식의 반전
토큰라이트는 3D 장면 재구성(3D scene reconstruction) 단계를 생략하고도 정확한 조명 편집이 가능함을 증명한 디퓨전 기반 모델이다. 기존 방식은 이미지 한 장에서 기하(geometry), 재질(material), 조명을 역(逆)으로 추정한 뒤 다시 그려내는 이른바 역렌더링(inverse rendering) 과정을 거쳤다.
이 접근은 오클루전(occlusion)이 심하거나 반투명한 재질이 섞인 장면에서 종종 무너졌다. 토큰라이트 팀은 이 경로를 버리고, 입력 이미지와 '바꾸고 싶은 빛의 속성'만 모델에 넣어 곧바로 결과 이미지를 생성하도록 설계했다. 3D 공간 복원이라는 무거운 중간 단계를 없앤 대신, 모델이 빛과 장면의 상호작용을 통째로 학습하도록 맡긴 것이다.
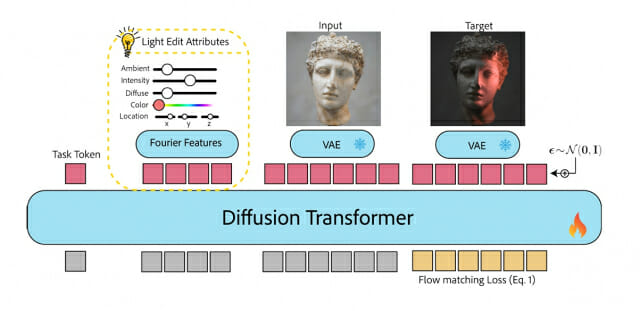
그림3. 3D 라이트 포지션 트레이닝을 위한 설계 개요
빛을 다섯 속성으로 나눈 어텐션 토큰 설계
조명 토큰(Attribute Token)이란 빛의 세기, 색상, 환경광 비율, 확산 정도, 3D 좌표 같은 개별 속성을 각각 별도의 토큰으로 분리해 디퓨전 트랜스포머(Diffusion Transformer)에 주입하는 구조를 말한다. 토큰라이트는 밝기(λ)나 환경광 계수(a) 같은 스칼라 값은 가우시안 푸리에 특성(Gaussian Fourier Features)으로 변환해 토큰 한 개로, 3D 위치(x, y, z)와 색상(R, G, B) 같은 벡터 값은 성분별로 잘라 성분당 토큰 한 개로 만들었다. 빛을 하나의 뭉뚱그린 명령어가 아니라 '다섯 갈래의 작은 메시지'로 쪼개서 전달하니, 모델은 각 속성을 독립적으로 조절할 수 있는 여유를 얻는다. 사용자가 마우스로 찍은 2D 화면 위의 점을 카메라 기준 3D 좌표로 환산한 뒤 이 토큰 시퀀스에 섞어 넣으면, 그것만으로 빛의 위치가 이동한다.
합성 데이터와 실사 600장이 만든 하이브리드 학습셋
토큰라이트의 핵심 재료는 블렌더(Blender)의 사이클스(Cycles) 경로 추적 렌더러로 만든 대규모 합성 데이터셋이다. 연구팀은 오브자버스(Objaverse)에서 걸러낸 3D 에셋과 절차 생성된 가상 인간을 배경에 배치하고, 장면마다 64개의 점광원(point light)을 무작위 위치에 찍어 렌더링했다.
여기에 폴리헤이븐(PolyHaven)이 제공하는 약 600장의 HDRI 환경 맵이 추가돼 환경광 변화를 학습시켰다. 실내 장면용으로는 아티스트가 직접 제작한 83개 장면에서 조명 기구별로 따로 렌더링한 약 10만 장의 이미지가 쓰였다.
수치 자체는 합성 데이터가 압도적이지만, 여기에 실내에서 실제 조명을 켜고 끄며 찍은 600장의 실사 사진이 더해졌다. 이 소량의 실사 데이터가 합성 데이터 특유의 '플라스틱 질감'을 털어내고 모델이 실제 사진에 일반화되도록 끌어주는 역할을 한다. 데이터 규모로 밀어붙이기보다, 합성과 실사의 비율을 정교하게 조합한 셈이다.
유리와 머리카락에서 재질을 구분하는 빛의 반응
토큰라이트는 재질이 까다로운 장면에서 경쟁 모델과의 차이가 벌어진다. 연구팀이 발표한 수치를 보면, 토큰라이트의 공간 조명 제어 성능은 PSNR 21.24를 기록해 기존 뉴럴 개퍼(Neural Gaffer)의 16.72, 디퓨전 렌더러(DiffusionRenderer)의 13.51을 크게 앞섰다. PSNR은 원본과의 픽셀 단위 유사도를 재는 지표로, 4점 이상의 격차는 육안으로도 차이가 뚜렷한 수준이다.
실제 결과 이미지에서 투명 유리를 통과한 빛은 자연스러운 그림자를 남기고, 테디베어의 털은 역광에서 한 올씩 반투명하게 빛난다. 도자기 조각상은 광택이 강한 재질 특유의 스페큘러(specular) 하이라이트가 정확한 위치에 나타난다.
흥미로운 점은 이 모델이 역렌더링 감독 없이도 '빛이 어떤 재질을 만나면 어떻게 튀어야 하는지'를 스스로 터득했다는 것이다. 논문은 이를 모델에 내재된 조명-장면 이해(light-scene understanding)라고 표현한다.
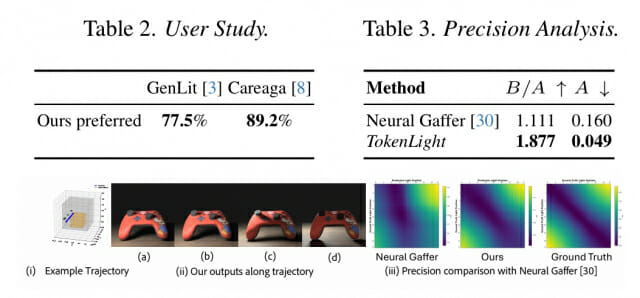
그림5. 실제 조명에 더 가까운 토큰라이트의 조명 이동과 뉴럴 개퍼의 위치 오차 비교
사용자 77.5%가 선택한 결과, 선호도로 벌어진 격차
정량 지표뿐 아니라 사람이 직접 고른 결과에서도 토큰라이트의 우위가 확인됐다. 토큰라이트를 경쟁 모델인 젠릿(GenLit), 카레아가(Careaga et al.)와 비교한 사용자 연구에서, 참가자들은 각각 77.5%와 89.2%의 비율로 토큰라이트의 결과를 선호했다. 숫자가 8:2 또는 9:1에 가깝다는 것은 취향의 편차를 넘어 결과 품질의 차이를 사람이 한눈에 구별한다는 의미다.
가시 조명 기구(visible fixture)를 켜고 끄는 실사 테스트셋(VisibleFixture-60)에서는 토큰라이트가 PSNR 20.07, SSIM 0.85를 기록해 스크리블라이트(ScribbleLight)의 14.64, 0.52를 크게 넘어섰다.
조명을 끄면 해당 위치에서 유래한 그림자가 깔끔하게 사라지고, 켜면 병이나 테이블 위에 맞는 반사광이 돌아온다. 단순히 밝기만 조절하는 수준이 아니라 빛-기하 상호작용까지 재현하고 있다는 뜻이다.
영상 후반 작업과 제품 촬영이 맞을 파급 효과
토큰라이트가 상용화 수준으로 다듬어지면 영상 후반 작업(post-production)과 제품 촬영의 워크플로우가 크게 달라질 가능성이 있다. 지금까지 조명은 촬영 시점에 거의 확정되는 요소였다. 잘못 켜진 램프나 아쉬운 그림자 방향을 뒤늦게 바꾸려면 재촬영이나 수작업 보정이 필요했다. 토큰라이트가 제시한 세 가지 제어 축(공간 가상 조명 추가, 환경광 편집, 실내 조명 기구 제어)은 이 작업을 '토큰 몇 개를 바꾸는 클릭 몇 번'으로 단축할 수 있다.
다만 논문은 한계도 분명히 적었다. 현재 모델은 단일 이미지 기준으로 최적화됐고, 영상으로 확장할 경우 프레임 간 조명 일관성 유지가 새로운 과제로 남는다. 또 합성 데이터로 훈련된 모델이 실제 카메라의 센서 특성이나 극단적인 노출 환경에서도 같은 품질을 유지할지는 추가 검증이 필요한 영역이다. 연구팀이 어도비 소속 연구원 다수를 포함하고 있다는 점을 감안하면, 이 기술이 상용 이미지·영상 편집 제품으로 어떤 방식으로 흡수될지는 앞으로 지켜볼 만한 대목이다.
FAQ( ※ 이 FAQ는 본지가 리포트를 참고해 자체 작성한 내용입니다.)
Q1. 토큰라이트가 기존 AI 조명 편집 도구와 가장 다른 점은 무엇인가요?
A. 기존 도구는 이미지에서 3D 구조를 먼저 복원한 뒤 조명을 새로 계산하는 방식이 많았습니다. 토큰라이트는 이 복원 단계를 생략하고, 빛의 속성을 작은 '토큰' 단위로 쪼개 모델에 직접 전달합니다. 그래서 유리나 머리카락처럼 3D 복원이 어려운 재질에서도 자연스러운 결과가 나옵니다.
Q2. 얼굴이나 피사체의 일관성을 어떻게 유지하나요?
A. 토큰라이트는 조명 편집을 '새 이미지를 처음부터 그리는 작업'이 아니라 '원본 이미지에 조명 변화만 더하는 조건부 생성 작업'으로 설계했습니다. 입력 이미지 자체가 모델의 조건으로 들어가기 때문에, 피사체의 얼굴·옷·배경 디테일은 그대로 유지된 채 빛만 바뀝니다.
Q3. 일반 사용자도 이 기술을 곧 쓸 수 있을까요?
A. 현재 토큰라이트는 연구 단계의 논문과 프로젝트 페이지로 공개된 상태입니다. 공동 연구를 진행한 어도비가 이를 자사 이미지·영상 편집 제품에 어떤 형태로 녹일지는 아직 공식 발표되지 않았습니다. 다만 연구가 제시한 세 가지 제어 축은 상용 앱에 바로 적용 가능한 구조여서, 중장기적으로 일반 편집 도구에서 유사한 기능을 만날 가능성이 있습니다.
기사에 인용된 리포트 원문은 arXiv에서 확인할 수 있다.
리포트명: TokenLight: Precise Lighting Control in Images using Attribute Tokens
관련기사
- AI에게 접시 가져다달라 했더니 냉장고부터 연 이유2026.04.23
- "나는 로봇이 아닙니다" 무너지다…AI가 캡차 83.9%까지 풀어냈다2026.04.22
- 챗GPT가 운전대를 잡으면…한 대는 겁쟁이, 한 대는 폭주족 됐다2026.04.21
- SK하이닉스, 또 쌓는다...온디바이스 AI용 '3D 적층 D램' 개발 시동2026.07.24
이미지 출처: AI 생성 콘텐츠
■ 이 기사는 AI 전문 매체 ‘AI 매터스’와 제휴를 통해 제공됩니다. 기사는 클로드 3.5 소네트와 챗GPT를 활용해 작성되었습니다. (☞ 기사 원문 바로가기)