LG AI연구원이 이미지와 텍스트를 동시에 이해하고 추론하는 멀티모달 인공지능(AI) 모델을 내놨다.
LG AI연구원은 '엑사원(EXAONE) 4.5'를 9일 공개했다. 엑사원 4.5는 LG AI연구원이 2021년 12월 국내 첫 멀티모달 AI 모델 '엑사원 1.0'을 개발하며 축적한 기술력으로 개발됐다. 비전 인코더와 거대언어모델(LLM)을 하나의 구조로 통합한 비전 언어 모델(VLM)이다.
이번 모델은 정부 주도의 '독자 AI 파운데이션 모델 프로젝트'에서 개발 중인 'K-엑사원'의 모달리티 확장을 위한 준비 단계다. LG AI연구원은 오는 8월 프로젝트 2차수 종료 이후 3차수 진출이 확정되면 모달리티로 영역을 확장할 계획이다. 엑사원이 가상 환경을 넘어 물리적 세계를 이해하고 판단하는 피지컬 인텔리전스로 거듭나는 것을 목표하고 있다.
엑사원 4.5는 계약서, 기술 도면, 재무제표, 스캔 문서 등 산업 현장에서 실제로 다루는 복합 문서를 정확하게 읽고 추론하는 능력에 강점이 있다.
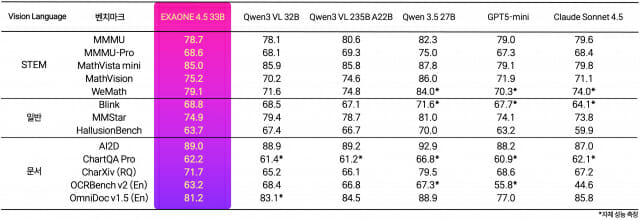
LG AI연구원이 공개한 벤치마크 점수 결과에 따르면 엑사원 4.5는 STEM(과학·기술·공학·수학) 성능을 측정하는 5개 지표 평균 77.3점을 기록했다. 이는 미국 오픈AI GPT5-미니(73.5점), 앤트로픽 클로드 소넷4.5(74.6점), 중국 알리바바 큐원3 235B(77.0점)를 모두 앞선 점수다.
일반 시각 이해를 측정하는 3개 지표와 이미지와 텍스트가 결합된 인포그래픽, 전문 문헌 속 복합 정보를 읽어내는 문서 이해 및 추론 성능 평가 지표 5개를 포함한 13개 지표 평균 점수에서도 GPT5-미니와 클로드 소넷4.5, 큐원3-VL을 상회하는 성능을 보였다.
특히 코딩 성능 대표 지표인 라이브코드벤치v6에선 81.4점으로 구글의 최신 모델 젬마4(80.0점)를 넘었으며, 복잡한 차트를 분석하고 추론하는 능력을 평가하는 차트QA 프로에선 62.2점을 받았다.
LG AI연구원 관계자는 "시각 능력 평가 지표에서 높은 평균 점수를 기록했다는 것은 AI가 문서 속 글자나 비정형 데이터를 인식하는 수준을 넘어, 맥락을 파악하고 질문에 답할 수 있는 이해력을 갖췄다는 의미"라고 설명했다.
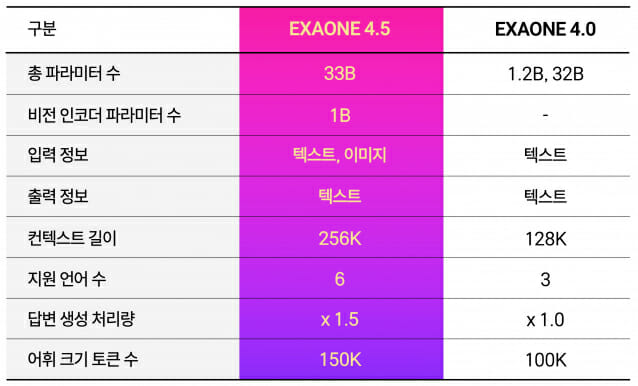
엑사원 4.5는 효율성도 대폭 향상됐다. 330억 개 파라미터 규모(33B)로 K-엑사원의 약 7분의 1 크기이지만 텍스트 이해·추론 영역에서 동등한 성능을 달성했다. 자체 개발한 하이브리드 어텐션 구조와 멀티 토큰 예측 기반 고속 추론 기술을 적용한 결과로, 지원 언어도 한국어·영어에서 스페인어·독일어·일본어·베트남어까지 확장해 글로벌 활용도를 높였다.
관련기사
- LG 멀티모달 ‘엑사원 4.5’ 공개 초읽기...휴머노이드 두뇌 노린다2026.03.02
- LG AI연구원, 'K-엑사원' 경쟁력 입증…'독파모' 첫 평가 1위2026.01.11
- [신년 인터뷰] 임우형 LG AI 연구원장 "AI, 이제 실행의 시대…신뢰가 성패 가른다"2026.01.07
- "美·中 모델 능가"…LG AI연구원, 'K-엑사원' 성능 공개2025.12.30
LG AI연구원은 이번 모델을 글로벌 오픈소스 플랫폼인 허깅페이스에 오픈 웨이트로 공개했다. 2024년 8월 엑사원 3.0을 국내 최초 오픈 웨이트 모델로 선보인 이후 생태계 확장 행보를 이어가는 것으로, 연구·학술·교육 목적 활용이 가능하다.
이진식 LG AI연구원 엑사원랩장은 "엑사원 4.5는 LG AI가 텍스트를 넘어 시각 정보까지 이해하는 멀티모달 시대로 진입했음을 보여주는 모델"이라며 "음성과 영상, 물리 환경까지 AI의 이해 범위를 확장해 산업 현장에서 실질적으로 판단하고 행동하는 AI를 만들겠다"고 강조했다.