






사진이나 만화 속 장면을 왜곡없이 손쉽게 3D로 변형할 수 있는 AI(인공지능) 기술이 개발됐다.
UNIST는 인공지능대학원 주경돈 교수 연구팀이 3D 가우시안 모델이 생성한 3D 캐릭터의 자세를 형태 왜곡없이 바꿔주는 AI 기술인 '디폼스플랫'을 개발했다고 25일 밝혔다.
기존에는 사진과 같은 2D 데이터를 입력받아 화면에 3D 객체를 재구성해 주는 AI 모델, '3D 가우시안 스플래팅'을 이용했다.
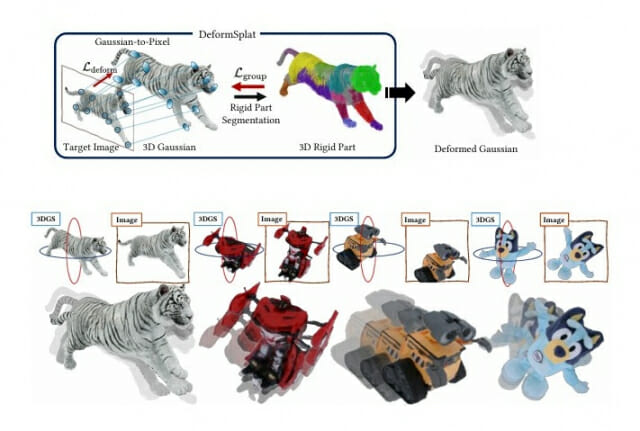
그러나 가우시안 스플래팅이 재구성한 3D 캐릭터를 만화나 게임에서 처럼 움직이게 하려면, 여전히 여러 각도에서 촬영한 영상 데이터나 연속 촬영된 비디오 데이터가 필요하다.
데이터가 부족하면 팔, 다리 등이 움직일 때 엿가락처럼 휘어지는 형태 왜곡이 생기기 쉽기 때문이다.
연구진이 개발한 '디폼스플랫'은 사진 한 장 입력으로 형태 왜곡 없이 3D 캐릭터의 자세를 사진 속 자세와 똑같이 움직이게 바꿔준다.
실제 실험 결과, 이 모델이 제작한 3D 캐릭터는 각도를 바꿔 옆이나 뒤에서 보아도 형태 왜곡이 적고 자연스러운 자세를 유지한다.
예를 들어 팔을 드는 동작을 입력하면, 정면뿐 아니라 측면이나 뒤쪽 시점에서도 팔과 몸통의 비율이 흐트러지지 않는다. 관절이 고무처럼 늘어나는 현상도 거의 나타나지 않는다.
연구팀은 가우시안–픽셀 매칭과 강체 부위 분할 기술을 이용해 이 같은 모델을 개발했다. 가우시안–픽셀 매칭은 3D 캐릭터를 구성하는 가우시안 점들과 2D 사진 속 픽셀을 연결해, 사진에 담긴 자세 정보를 3D 캐릭터로 전달하는 기술이다.
또 자세 변형 시 함께 움직여야 하는 단단한 부위를 스스로 찾아 그룹으로 묶어내는 강체 부위 분할 기술 덕분에 로봇이나 인형의 형태가 찌그러지지 않고 자연스럽게 움직일 수 있다.

주경돈 교수는 “기존 기술은 사진 한 장만을 입력 데이터로 활용해 3D 물체를 움직이려 하면 형태가 심각하게 훼손되는 한계가 있었다”며 “개발된 AI는 물체의 구조적 특성을 고려해 스스로 뼈대 역할을 하는 영역을 구분하고 움직임을 생성하는 기술로, 전문 인력과 고가의 장비에 의존하던 메타버스·게임·애니메이션 등 3D 콘텐츠 제작 분야의 진입 장벽을 낮출 수 있을 것으로 기대된다”라고 말했다.
관련기사
- 헥사곤, 레드불레이싱에 3D 솔루션 공급…18년 협력 강화2025.03.06
- ‘폴더블 아이폰’ 3D 모형 등장…이렇게 생겼다고?2025.12.24
- SOOP, 3D 아바타 제작 ‘버추얼 메이크오버 시즌2’ 진행2025.12.10
- 텐센트, 텍스트·이미지·스케치 등 상업용 3D 에셋 몇 분 만에 생성2025.11.26
연구 결과는 최근 홍콩서 열린 시그그래프 아시아(SIGGRAPH ASIA) 2025에 공개됐다. 시그그래프 아시아는 컴퓨터과학 분야 세계 최대 국제 학회 단체인 ACM이 주관하는 학회다.
연구는 정보통신기획평가원과 UNIST 인공지능대학원이 지원했다.





