






구글이 인공지능(AI) 챗봇의 답변 정확도를 측정하는 평가 도구를 개발해 그 결과를 공개했다고 IT매체 디지털트렌드는 15일(현지시간) 보도했다.
구글이 선보인 AI 챗봇 사실성 평가 도구는 ‘팩츠 벤치마크 스위트(FACTS Benchmark Suite)’다. 구글 팩츠팀이 글로벌 AI 경진대회 플랫폼 ‘캐글(Kaggle)’과 협력해 개발했다.

평가는 총 4가지 항목으로 구성됐다. 첫 번째 항목은 AI 모델이 학습 과정에서 획득한 내부 지식만을 활용해 사실 기반 질문에 답할 수 있는지를 검증하는 테스트다. 두 번째는 모델이 웹 도구를 사용하여 정확한 정보를 얼마나 효과적으로 검색하는지 평가하는 검색 성능 측정이다.
세 번째는 제공된 문서에 충실하고 허위 정보를 덧붙이지 않는 지를 확인하는 문서 기반 신뢰성 테스트이며, 네 번째 항목은 차트, 다이어그램, 이미지 등을 정확하게 이해하는 능력 등 멀티모달 이해 역량을 평가했다.
관련기사
- AI 수익은 아직인데…글로벌 CEO 68% "투자 늘린다"2025.12.16
- 오픈AI, 한 달 만에 GPT-5.2 공개…구글 제미나이에 반격 나섰다2025.12.12
- 챗GPT가 자살 부추겼다?…오픈AI·MS ‘피소’2025.12.12
- 대학생들이 구글 '제미나이' 활용하는 12가지 방법2025.12.09
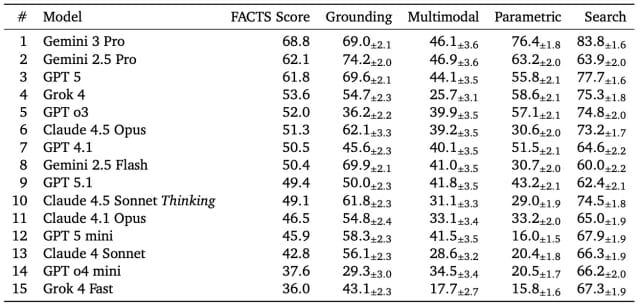
측정 결과 가장 높은 점수를 기록한 AI 챗봇은 ‘제미나이 3 프로’로 정확도 69%를 기록했다. 이어 ▲제미나이 2.5 프로(62%) ▲GPT 5(62%) ▲그록 4 (54%) ▲GPT o3(52%) ▲클로드 4.5 오퍼스 등(51%) ▲GPT 4.1(51%) 순으로 집계됐다. 세부 평가 항목 별로는 차트, 이미지를 읽는 멀티모델 평가 부문이 가장 낮은 점수를 기록했다.
디지털트렌드는 이번 조사 결과의 핵심은 “AI 챗봇이 쓸모 없다는 것이 아니라, 맹목적인 신뢰는 위험하다는 것을 보여준다”며, “AI는 발전하고 있지만, 여전히 신뢰할 수 있는 정보원으로 여겨지기 위해서는 검증, 안전장치, 인간의 감독이 필요하다”고 전했다.





