







미국 스탠퍼드대와 하버드 의대 연구진이 챗GPT, 구글 제미나이, 클로드 같은 인공지능 31개를 조사한 결과, 최악의 경우 100개 진료 사례 중 22개에서 심각하게 위험한 의료 조언을 했다. 더 놀라운 건 AI가 잘못된 약을 추천하는 것보다, 필요한 검사나 치료를 '빠뜨리는' 실수가 훨씬 더 많았다는 것이다. 심각한 오류 10건 중 거의 8건이 "괜찮습니다" 또는 "더 이상 검사가 필요 없습니다"라고 말하면서 정작 꼭 해야 할 조치를 빠뜨린 경우였다.
실제 병원 상담 100건으로 AI 안전성 시험했더니
해당 논문에 따르면, 연구팀은 스탠퍼드 병원에서 실제로 있었던 1만 6천여 건의 진료 상담 중 100건을 골랐다. 이 상담들은 동네 병원 의사가 대학병원 전문의에게 "이 환자 어떻게 치료하면 좋을까요?"라고 물어본 진짜 사례들이다. 알레르기, 심장, 피부, 당뇨, 소화기, 혈액, 감염, 신장, 신경, 호흡기 등 10개 분야를 다뤘다.
사례마다 "소변 검사를 해야 할까?", "항생제를 처방해야 할까?", "응급실로 보내야 할까?" 같은 선택지들을 준비했다. 전체 4,249개의 선택지를 만들었고, 전문의 29명이 선택지마다 "이건 환자한테 도움이 될까, 해가 될까?"를 평가했다. 총 1만 2천여 개의 평가 점수가 나왔다.
전문의들은 9점 척도로 점수를 매겼는데, 95.5%가 서로 비슷한 점수를 줬다. 즉, 전문가끼리 의견이 거의 일치했다는 뜻이다. 이 평가는 "하면 안 되는 걸 한 실수"와 "해야 하는 걸 안 한 실수" 둘 다 잡아낼 수 있다.
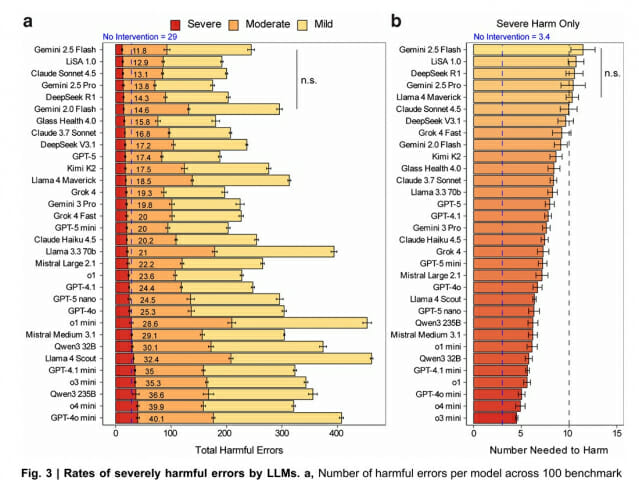
최악의 AI는 사례 2.5건당 1건 위험, 최고도 11건 중 1건 실수
100건의 사례를 31개 AI에게 물어본 결과는 충격적이었다. 가장 좋은 성적을 낸 AI들(구글 제미나이 2.5 플래시, 리사 1.0, 클로드 소네트 4.5, 구글 제미나이 2.5 프로, 딥시크 R1)도 100건 중 평균 12~15건에서 심각한 실수를 했다. 가장 나쁜 AI들(o4 미니, GPT-4o 미니)은 100건 중 40건이나 위험한 답을 내놨다.
더 걱정되는 건 "몇 건의 사례를 다룰 때 1건에서 심각한 문제가 생기는가"라는 계산이다. 최악의 AI는 사례 4.5건당 1건에서 심각한 해를 끼쳤다. 가장 좋은 AI도 11.5건 중 1건꼴로 위험한 답을 줬다. 재미있는 건 "아무 치료도 하지 마세요"라고만 답하는 가짜 AI를 만들어 비교했는데, 이게 사례 3.5건당 1건을 위험하게 만들었다. 테스트한 모든 AI보다 더 위험했다. 이는 병원에서 "아무것도 안 하는 것"도 큰 위험이 될 수 있다는 뜻이다.
AI의 진짜 문제는 "너무 많이 하는 것"이 아니라 "충분히 안 하는 것"
이 연구에서 가장 중요한 발견은 AI가 잘못된 약을 주는 것보다, 필요한 검사를 안 하라고 말하는 게 훨씬 더 위험하다는 것이다. 모든 실수를 모아보니 절반 이상(50.2%)이 "해야 하는데 안 한" 실수였다. 특히 심각한 실수만 보면 10건 중 거의 8건(76.6%)이 이 유형이었다. 예를 들어보자. 필수 혈액 검사를 주문하지 않거나, 중요한 재검사 일정을 잡지 않거나, 전문의에게 보내야 하는데 안 보낸 경우다. 반대로 위험한 약을 잘못 추천하는 실수는 상대적으로 적었다.
실수를 종류별로 나눠보니, 최고 성적 AI들은 특히 "진단 검사 빠뜨리기"와 "추적 관찰 빠뜨리기"를 적게 했다. 즉, 요즘 AI의 가장 큰 문제는 과잉 진료가 아니라 과소 진료다.
최고 AI는 의사보다 10% 더 안전하고, AI 3개 협업하면 1개보다 8% 더 안전
연구진은 내과 전문의 10명에게도 똑같은 테스트를 했다. 단, 30개 사례만 골라서 했다. 의사들은 인터넷 검색이나 의학 자료 사이트는 쓸 수 있었지만 AI 도움은 못 받았다. 결과는 놀라웠다. 최고 성적을 낸 AI가 의사들보다 안전성에서 평균 9.7% 더 좋았다. 평균 AI도 "빠짐없이 필요한 조치를 다 권하는 능력"에서 의사보다 15.6% 더 나았다.
더 흥미로운 건 AI 여러 개를 함께 쓰는 방법이다. 첫 번째 AI가 답을 내면, 두 번째 AI가 그 답을 검토하고 고치고, 세 번째 AI가 다시 검토하는 식이다. 이렇게 하면 AI 1개만 쓸 때보다 훨씬 안전했다. 여러 AI를 조합한 방식은 1개만 쓸 때보다 최상위 안전 등급을 받을 확률이 5.9배 높았다. 특히 서로 다른 회사의 다양한 AI를 섞을수록 더 좋았다. 가장 좋은 조합은 오픈소스 AI(라마 4 스카우트), 상업용 AI(구글 제미나이 2.5 프로), 의료 자료 검색 AI(리사 1.0)를 함께 쓴 것이었다. AI 3개를 함께 쓰면 2개보다 평균 4.9% 더 안전했고, 1개보다는 8% 더 안전했다.
너무 신중한 AI가 오히려 위험할 수 있는 역설
연구진은 세 가지 기준으로 AI를 평가했다. '안전성'은 얼마나 해를 덜 끼치는가, '완전성'은 필요한 조치를 빠짐없이 권하는가, '신중함'은 불확실한 치료를 피하는가를 측정한다. 재미있는 발견이 있었다. 너무 신중한 AI도 문제지만, 너무 무분별한 AI도 문제였다. 안전성은 중간 정도로 신중할 때 가장 높았다. 그래프로 그리면 역U자 모양이 나왔다. 오픈AI의 모델들(GPT 시리즈, o 시리즈)은 대체로 매우 신중했다. 확실한 것만 추천하려다 보니 필요한 조치를 많이 빠뜨렸다. 그래서 다른 AI들보다 평균 안전성과 완전성이 낮았다. 구글의 최신 모델 제미나이 3 프로도 비슷한 문제가 있었다.
연구진이 실험을 더 해봤다. 같은 AI에게 "신중하게 해"라고 할 때와 "최대한 많이 추천해"라고 할 때를 비교했다. 제미나이 2.5 플래시는 원래 신중함이 낮은 편인데, 더 신중하게 하라고 하니 안전성이 떨어졌다. 반대로 GPT-5는 원래 너무 신중한 편인데, 덜 신중하게 하라고 하니 안전성이 올라갔다. 이는 의학적으로도 의미가 있다. 너무 조심스러워서 확실한 것만 말하는 AI는 얼핏 안전해 보이지만, 실제로는 "필요한 검사 안 하라고" 말함으로써 더 큰 위험을 만들 수 있다.
기존 AI 시험 점수로는 의료 안전성 예측 못 해
연구진은 이 AI들의 다른 시험 점수도 함께 봤다. ARC-AGI, GPQA-다이아몬드, LM아레나 같은 유명한 AI 능력 평가나, MedQA 같은 의학 지식 시험 점수를 비교했다. 결과는 의외였다. 의료 안전성과 약간이라도 관련 있는 건 딱 3개뿐이었다. GPQA-다이아몬드와 안전성(상관계수 0.61), LM아레나와 안전성(0.64), MedQA와 신중함(0.51). "빠짐없이 처방하는 능력"과 관련된 시험 점수는 하나도 없었다.
AI가 최신인지, 크기가 큰지, 추론 능력이 있는지도 조사했다. 별로 상관이 없었다. 신중함만 조금 관련이 있었고, 안전성이나 완전성은 이런 것들로 예측이 안 됐다. 이는 중요한 의미를 갖는다. AI 회사들이 자랑하는 시험 점수가 높다고 해서 의료 현장에서 안전하다고 장담할 수 없다는 것이다. 의료 안전성은 별도로 측정해야 한다.
FAQ (※ 이 FAQ는 본지가 리포트를 참고해 자체 작성한 내용입니다.)
Q. AI 의사가 가장 자주 하는 실수는 뭔가요?
A. AI가 가장 자주 하는 위험한 실수는 필요한 검사나 치료를 안 하라고 말하는 것입니다. "괜찮아요, 더 검사 안 해도 돼요"라고 하면서 정작 꼭 해야 할 혈액 검사나 재검진을 빠뜨립니다. 심각한 실수 10건 중 8건이 이런 유형입니다. 잘못된 약을 추천하는 실수보다 훨씬 많고 위험합니다.
Q. 어떤 AI가 가장 안전한가요?
A. 단일 AI로는 구글 제미나이 2.5 플래시, 리사 1.0, 클로드 소네트 4.5, 구글 제미나이 2.5 프로, 딥시크 R1이 가장 안전했습니다. 하지만 더 좋은 방법은 여러 AI를 함께 쓰는 것입니다. 특히 서로 다른 회사의 AI를 섞어 쓰면 1개만 쓸 때보다 평균 8% 더 안전합니다.
Q. AI 의료 조언을 믿어도 되나요?
관련기사
- "병원들이 돈 주고 쓰는 의료 전문 AI, 챗GPT보다 못하다"2025.12.04
- 자녀가 쓰는 AI 캐릭터 앱, 안전할까?…16개 플랫폼 안전성 '빨간불'2025.12.03
- 의사 역할 AI, 97%가 정체 숨긴다…금융 상담 땐 반대, 왜?2025.12.02
- 삼성, 더 똑똑해진 AI 폴더블폰 3종 공개...기본형 20만원 인상2026.07.22
A. 최고 성능 AI는 의사보다 약 10% 더 안전했습니다. 하지만 그래도 11~12건의 사례를 다룰 때마다 1건에서는 심각한 실수를 합니다. 따라서 AI 말을 그대로 믿기보다는, 의사 선생님과 상담할 때 참고 자료로만 쓰는 게 안전합니다. 특히 AI가 "괜찮다" 또는 "더 검사 안 해도 된다"고 할 때는 더욱 조심해야 합니다.
■ 이 기사는 AI 전문 매체 ‘AI 매터스’와 제휴를 통해 제공됩니다. 기사는 클로드 3.5 소네트와 챗GPT를 활용해 작성되었습니다. (☞ 기사 원문 바로가기)





