







인공지능(AI)이 뉴스 기사의 인터넷 주소(URL)만 보고도 정치 관련 내용인지 아닌지를 높은 정확도로 구분할 수 있다는 연구 결과가 나왔다. 스페인 바르셀로나 슈퍼컴퓨팅 센터와 바르셀로나대학교, 카탈루냐 개방대학교 공동 연구팀은 최신 AI 모델들이 URL만으로도 정치 뉴스를 효과적으로 분류하며, 일부 모델과 조건에서는 기사 본문을 활용한 것보다 더 나은 성능을 보인다는 사실을 확인했다. 이번 연구는 프랑스, 독일, 스페인, 영국, 미국 5개국의 실제 인터넷 사용 기록을 분석해 진행됐으며, 언어와 나라가 달라도 URL 기반 분류 방식이 효과적으로 작동한다는 것을 입증했다.
URL만 봐도 정치 뉴스 구분 가능... 일부 모델, 기사 본문보다 높은 성능
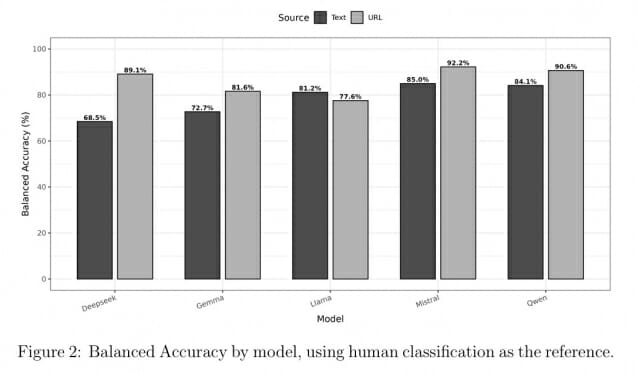
해당 논문에 따르면, 연구팀은 딥시크(DeepSeek R1 7B), 젬마(Gemma 3 27B), 라마(Llama 3.1 8B), 미스트랄(Mistral Small 2IB), 큐웬(QwQ 32B) 등 5개의 AI 모델로 정치 뉴스 분류 성능을 실험했다. 이 모델들은 모두 2023년 12월부터 2025년 4월 사이에 학습이 끝난 최신 버전으로, 일반 컴퓨터에서도 실행할 수 있는 오픈소스 방식이다. 실험 결과, 대부분의 최신 AI 모델이 뉴스 URL만으로 정치 기사 분류에서 높은 정확도를 기록했으며, 미스트랄의 92.2%, 큐웬의 90.6% 등 일부 모델은 기사 본문을 활용한 결과(85.0%, 84.1%)보다 더 뛰어난 성능을 보였다.
딥시크 모델은 가장 큰 차이를 보였는데, 기사 전문을 읽었을 때는 68.5%에 그쳤지만 URL만 봤을 때는 89.1%까지 올라갔다. 이는 이 모델이 웹사이트 주소 정보에 크게 의존한다는 것을 보여준다. 젬마는 본문으로 72.7%, URL로 81.6%를, 라마는 본문으로 81.2%, URL로 77.6%의 정확도를 기록했다.
실험에 사용된 데이터는 2022년 2월 22일부터 6월 5일까지 5개국에서 수집한 실제 인터넷 사용 기록이었다. 각 나라에서 인기 있는 뉴스 매체 50~100곳을 대상으로 1,140건의 방문 기록을 무작위로 뽑았고, 나라마다 약 200개의 정치 기사와 200개의 비정치 기사를 사람이 직접 분류해 기준으로 삼았다. 두 명의 전문가가 독립적으로 분류한 결과 96.6%가 일치했고, 통계적 신뢰도를 나타내는 카파 값은 0.93으로 거의 완벽한 수준이었다.
틀린 건 줄었지만 놓치는 것도 생겨... URL 방식의 장단점 공존
정치 뉴스 분류에서는 두 가지 지표가 중요하다. 하나는 '정밀도'로, AI가 정치 기사라고 판단한 것 중 실제로 정치 기사인 비율이다. 다른 하나는 '재현율'로, 실제 정치 기사 중에서 AI가 찾아낸 비율이다. 연구 결과, 기사 전문을 읽은 모델들은 재현율이 매우 높았다(97~99%). 거의 모든 정치 기사를 찾아냈다는 뜻이다. 하지만 정밀도는 71~83%에 머물러, 정치 기사가 아닌데 정치 기사라고 잘못 판단하는 경우가 많았다.
반면 URL만 본 모델들은 재현율이 92~94%로 약간 낮았다. 일부 정치 기사를 놓쳤다는 의미다. 하지만 정밀도는 90~95%로 크게 높아졌다. 쉽게 말해, URL 방식은 조금 더 신중하게 판단한다. 정치 기사라고 판단하는 횟수는 줄었지만, 판단했을 때 맞을 확률은 훨씬 높다는 뜻이다. 전체적으로 보면 URL 방식이 정밀도와 재현율의 균형을 더 잘 맞췄고, 종합 점수인 F1 점수는 93%까지 올라갔다.
통계적 신뢰도를 나타내는 카파 값도 이를 뒷받침한다. 미스트랄-URL은 0.84, 큐웬-URL은 0.82로 매우 높은 일치도를 보인 반면, 본문 읽기 방식은 일관되게 낮았다. 미스트랄-본문은 0.72, 큐웬-본문은 0.71이었고, 딥시크-본문은 0.44, 젬마-본문은 0.49에 그쳤다. 이는 본문 전체에만 의존하면 사람과의 의견 차이가 더 커진다는 것을 보여준다.
중도 성향 기사에서 오판 집중... 명확한 진보·보수 기사는 높은 일치율
연구팀은 AI가 특정한 패턴으로 실수한다는 사실도 발견했다. AI별로 어떤 경우에 사람과 의견이 갈리는지 분석한 결과, 실제 정치 기사인 경우엔 AI도 91.8~99.5%를 정확히 찾아냈지만, 정치 기사가 아닌 경우엔 40.6~92.4%만 맞췄다. 이는 AI들이 '아닌데 맞다'고 판단하는 오류, 즉 비정치 기사를 정치 기사로 잘못 분류하는 경향이 있다는 뜻이다.
연구팀은 이 오류가 왜 생기는지 알아보기 위해 AI에게 각 기사의 정치 성향을 1~10점으로 평가하게 했다(1점은 진보, 10점은 보수). 연구팀은 이 점수가 정확한지 따로 검증하지는 않았지만, AI가 어디서 실수하는지 찾는 도구로 활용했다. 분석 결과, 정치 성향이 중도인 기사(4~6점)에서는 모델과 사람 판단의 일치율이 평균 65%대로 뚜렷이 낮아졌으며, 명확한 진보·보수 기사(1~3점, 7~10점)는 일치율이 대체로 높았다.
실제로 4~6점 기사들을 빼고 계산하자 모든 모델의 정확도가 크게 올랐다. 딥시크는 본문 읽기 방식으로 74.3%에서 89.7%로 올랐고, URL 방식도 추가로 개선됐다. 젬마, 라마, 미스트랄, 큐웬 모두 91~95% 범위의 정확도를 보였다. 중도 성향 기사를 제외한 조건에서는 일부 모델(젬마, 라마)의 경우 본문 분류 점수가 URL 방식보다 오히려 높아지기도 했다.
5개국 모두 비슷한 결과... 언어·미디어 환경 차이 영향 미미
연구 결과, 국가별·언어별로 정치 기사 분류 성능에 유의미한 차이가 발견되지 않았다. 다만 논문에서는 환경 및 구조에 따라 부분적 영향 가능성은 언급하고 있다. 프랑스, 독일, 스페인, 영국, 미국 모두에서 사람이 판단한 결과와 높은 일치율을 유지했다. 다만 연구팀은 URL 방식의 성공 여부가 언론사가 URL을 어떻게 만드는지에도 영향을 받는다고 지적했다. 일부 언론사는 기사 제목이나 내용을 URL에 잘 담지 않아 AI가 활용할 단서가 거의 없다. 예를 들어 '/world-europe-60547473' 같은 형식은 숫자만 있어서 내용을 전혀 짐작할 수 없다. 이런 문제를 줄이기 위해 연구팀은 URL이 단서를 주지 못할 때 판단을 보류하는 'SKIP' 옵션을 만들었다.
연구팀은 이 방법이 누구나 쉽게 사용할 수 있다는 점도 강조했다. 라마 8B나 딥시크 R1 7B 같은 작은 모델은 정확도가 상대적으로 낮았지만, 미스트랄이나 젬마 같은 중간 크기의 오픈소스 모델들은 뛰어난 성능을 보였다. 이는 비싼 컴퓨터나 유료 서비스 없이도 충분히 좋은 결과를 얻을 수 있다는 의미다.
FAQ( ※ 이 FAQ는 본지가 리포트를 참고해 자체 작성한 내용입니다.)
Q1: URL만 보고도 정치 뉴스를 구분할 수 있는 이유가 뭔가요?
A: 많은 뉴스 사이트는 URL에 기사 제목의 주요 단어를 포함시킵니다. 연구팀에 따르면 URL에는 관련 정보가 담겨 있어서 고급 AI가 이런 단서를 활용할 수 있습니다. 다만 일부 언론사는 숫자나 코드만 쓰는 URL을 만들어 분류를 어렵게 만들기도 합니다.
Q2: 이 연구의 핵심 발견은 무엇인가요?
A: AI가 URL만으로도 높은 정확도로 정치 뉴스를 구분할 수 있으며, 종종 기사 전문을 읽는 것보다 더 정확하다는 점입니다. 미스트랄과 큐웬 모델은 URL로 92~93%의 종합 점수를 달성했습니다. 다만 중도 성향 뉴스를 정치적으로 과하게 분류하는 문제점도 발견됐습니다.
Q3: 이 방법의 한계는 무엇인가요?
관련기사
- 연세대, ‘챗GPT’ 집단 커닝 파문… 600명 중 190명 "컨닝했다"2025.11.10
- AI 언어 이해력, 1위는 폴란드어…한국어 22위, 왜?2025.11.07
- 깐부치킨, 'AI 깐부' 세트 출시…물 들어올 때 노 젓는다2025.11.05
- 美, 앤트로픽 '미토스5' 빗장 풀어…"100여 곳에 허용"2026.06.27
A: 정치 성향이 중간인 기사들(4~6점)에서 잘못된 판단이 집중되어, 정치 뉴스 노출을 실제보다 많게 평가하거나 사회 양극화를 낮게 평가할 위험이 있습니다. 또한 URL 구조가 언론사마다 달라서 일부는 유용한 정보를 주지 않습니다. 연구자들은 항상 사람의 판단과 비교해 확인하고 어디서 오류가 생기는지 점검해야 합니다.
■ 이 기사는 AI 전문 매체 ‘AI 매터스’와 제휴를 통해 제공됩니다. 기사는 클로드 3.5 소네트와 챗GPT를 활용해 작성되었습니다. (☞ 기사 원문 바로가기)





