







중국 텐센트 유투랩 연구팀이 AI의 '그림 그리기 능력'을 테스트하는 새로운 평가 방법을 개발했다. 이름은 'LTD-Bench'다. 기존에는 AI 성능을 숫자로만 평가했지만, 이제는 AI가 직접 그린 그림을 보고 능력을 판단할 수 있게 됐다. 연구 논문에 따르면, 최신 AI들조차 간단한 그림 그리기에서 심각한 문제를 보였다.
숫자 점수가 아니라 실제 그림으로 평가한다
지금까지 AI 평가는 주로 점수로 이뤄졌다. '이 AI는 85점입니다'라는 식이다. 하지만 이 점수가 실제로 무엇을 의미하는지 알기 어렵다. 특히 로봇이나 자율주행차처럼 실제 공간을 이해해야 하는 분야에서는 더욱 그렇다. LTD-Bench는 이 문제를 해결하기 위해 AI에게 직접 그림을 그리게 한다. 텍스트로 지시를 주면 AI가 점으로 된 격자판이나 파이썬 코드로 그림을 그린다. 그러면 전문가가 아니어도 AI가 잘 그렸는지 눈으로 바로 확인할 수 있다.
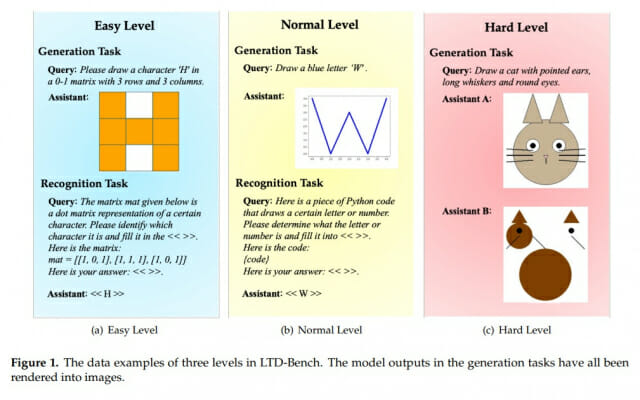
이 평가 방법은 총 183개의 문제로 구성되어 있다. 크게 두 가지 종류가 있다. 첫 번째는 '그리기 시험'이다. "H자를 그려라"처럼 말로 설명하면 AI가 그림을 그린다. 두 번째는 '알아맞히기 시험'이다. 그림을 보여주면 AI가 무슨 글자인지 맞춘다. 이렇게 양쪽 방향을 모두 테스트해서 AI가 언어와 그림을 제대로 연결하는지 확인한다.
최신 AI도 기초 문제에서 낙제점
연구팀은 DeepSeek-R1, GPT-4o, Llama 등 최신 AI 7개를 테스트했다. 난이도는 세 단계로 나뉜다. 쉬운 단계는 격자판에 간단한 글자 그리기, 중간 단계는 곡선으로 글자 그리기, 어려운 단계는 고양이나 비행기 같은 복잡한 사물 그리기다.
결과는 충격적이었다. 가장 성적이 좋은 DeepSeek-R1도 평균 70%밖에 맞히지 못했다. GPT-4.1-mini는 60%를 넘겼고, 나머지는 30% 안팎에 그쳤다. 반면 사람은 쉬운 문제와 중간 문제를 거의 완벽하게 풀었다. 이는 지금의 AI가 언어와 공간을 제대로 연결하지 못한다는 뜻이다.
구체적으로 어떤 실수를 했을까? AI들은 '>' 기호를 '<'로 거꾸로 그렸다. 'J'를 그리라고 했더니 'L'을 그렸다. 좌우나 위아래 방향을 헷갈린 것이다. 중간 단계에서는 더 심각했다. "파란색 W를 그려라"는 지시에 QwQ-32B는 거꾸로 된 글자를 그렸다. 다른 AI들은 아예 엉망진창인 선들만 그렸다. AI가 자기가 한 행동이 실제로 어떤 그림이 되는지 이해하지 못한다는 증거다.
똑똑한 AI일수록 오히려 더 못 그렸다
흥미로운 현상이 발견됐다. 깊게 생각하는 기능이 있는 AI들은 그림 알아맞히기는 잘했지만, 그림 그리기는 오히려 못했다. DeepSeek-R1은 알아맞히기에서 GPT-4.1-mini보다 25% 이상 높은 점수를 받았지만, 그리기에서는 뒤처졌다. QwQ-32B도 마찬가지였다.
더 놀라운 건 DeepSeek-R1 데이터로 학습시킨 Llama 모델이다. 알아맞히기 점수는 18% 올랐지만, 그리기 점수는 오히려 3% 떨어졌다. 연구팀은 이렇게 분석했다. 그림을 보고 무엇인지 알아내는 건 차근차근 생각하면 더 잘할 수 있다. 하지만 머릿속으로 그림을 상상해서 그리는 건 생각을 많이 한다고 더 잘되는 게 아니다. 오히려 기본 능력이 부족한데 너무 많이 생각하면 헷갈려서 성적이 떨어질 수 있다.
사진을 학습한 AI도 별 차이 없었다
사람은 눈으로 본 경험이 그림 그리기에 도움이 된다. 그렇다면 사진과 텍스트를 함께 학습한 AI가 더 잘 그릴까? 결과는 그렇지 않았다. GPT-4.1-mini나 GPT-4o 같은 멀티모달 AI(사진과 글을 모두 이해하는 AI)가 텍스트만 학습한 DeepSeek보다 항상 우수하지는 않았다.
GPT-4.1-mini가 그리기에서는 좋은 성적을 냈지만, 전체 점수는 여전히 DeepSeek-R1보다 낮았다. GPT-4o는 DeepSeek-V3보다도 못했다. 사진을 학습했다고 해서 자동으로 공간을 이해하는 능력이 생기는 건 아니라는 뜻이다. 사진 속 정보와 텍스트 정보를 어떻게 연결해야 하는지에 대한 추가 연구가 필요하다는 의미다.
한 가지 재미있는 발견도 있었다. 어려운 단계에서 같은 계열 AI들끼리 비슷한 스타일로 그림을 그렸다. Qwen 시리즈 AI들끼리 그린 그림은 50% 이상이 비슷했지만, GPT-4.1-mini와 비슷한 그림은 3개뿐이었다. 이는 AI끼리 얼마나 비슷한지 판단하는 새로운 방법이 될 수 있다.
AI가 세상을 이해하려면 아직 멀었다
이 연구가 보여주는 가장 중요한 사실은 지금의 AI가 진짜 세상을 이해하기엔 아직 부족하다는 점이다. 다른 평가에서 좋은 점수를 받은 AI들도 텍스트와 공간을 연결하는 데는 큰 문제가 있었다. 이는 로봇이나 자율주행차처럼 실제 공간에서 움직여야 하는 AI를 만들 때 반드시 개선해야 할 부분이다.
연구팀은 이 결과가 AI를 '진짜 세상을 이해하는 모델'로 발전시키는 데 중요한 단서를 제공한다고 설명했다. 전통적인 벤치마크에서 인상적인 결과를 달성한 모델들조차 언어와 공간 개념을 양방향으로 연결하는 데 심각한 결함을 보였기 때문이다. 물리적 세계와 상호작용해야 하는 AI 시스템을 개발하려면, 이 부분을 우선적으로 개선해야 한다는 의미다.
이 문제를 해결하려면 단순히 AI를 크게 만들거나 데이터를 많이 넣는 것으로는 부족하다. 공간을 이해하는 새로운 구조와 학습 방법이 필요하다. LTD-Bench는 이런 발전 과정을 측정하고 추적할 수 있는 직관적이고 투명한 평가 도구를 제공한다. 무엇보다 일반인도 AI의 실제 능력을 직접 확인할 수 있게 한다는 점에서 AI 연구와 이해 방식의 장벽을 낮춰 의미가 있다.
FAQ ( ※ 이 FAQ는 본지가 리포트를 참고해 자체 작성한 내용입니다.)
Q1. LTD-Bench는 기존 AI 평가와 어떻게 다른가요?
A1. AI에게 직접 그림을 그리게 해서 능력을 확인합니다. 85점 같은 숫자 대신 실제 그림을 보고 어디서 실수했는지 눈으로 바로 알 수 있습니다. 전문가가 아니어도 AI의 장단점을 쉽게 파악할 수 있습니다.
Q2. 최신 AI의 그림 그리기 실력은 어느 정도인가요?
A2. 가장 좋은 AI도 평균 70% 정도 맞혔고, 대부분은 30~60% 수준이었습니다. 사람은 쉽게 푸는 문제에서도 AI는 좌우를 헷갈리거나 글자를 거꾸로 그리는 등 기본적인 실수를 많이 했습니다.
Q3. 사진을 학습한 AI가 그림을 더 잘 그리나요?
관련기사
- 챗GPT, 무더기 소송 당했다…자살 계획 사용자에 "잘했다" 격려 논란2025.11.10
- AI 언어 이해력, 1위는 폴란드어…한국어 22위, 왜?2025.11.07
- AI, 덧셈보다 뺄셈 훨씬 자주 틀린다...왜 그럴까?2025.11.06
- 깐부치킨, 'AI 깐부' 세트 출시…물 들어올 때 노 젓는다2025.11.05
A3. 꼭 그렇지는 않았습니다. 사진과 글을 함께 학습한 GPT-4o가 텍스트만 학습한 AI보다 항상 우수하지는 않았습니다. 사진 데이터를 학습했다고 해서 자동으로 공간 이해 능력이 생기는 건 아닙니다.
■ 이 기사는 AI 전문 매체 ‘AI 매터스’와 제휴를 통해 제공됩니다. 기사는 클로드 3.5 소네트와 챗GPT를 활용해 작성되었습니다. (☞ 기사 원문 바로가기)





