






애플이 아이폰과 아이패드, 맥 컴퓨터의 AI 연산 처리 중심 장치를 신경망처리장치(NPU)에서 GPU로 전환했다.
16일 공개한 아이패드 프로·맥용 SoC(시스템반도체) M5 칩의 GPU 안에 '신경망 가속기'를 내장한다고 밝힌 것이다.
애플 실리콘 M 시리즈는 응용프로그램 처리 등 일반적인 연산에는 CPU를, 그래픽 처리와 일부 병렬 연산에는 GPU를 활용했다. NPU '뉴럴 엔진'은 특정 AI 연산을 실행하는 방식으로 독립적으로 작동했다.

이로 인해 애플의 AI 연산은 높은 효율을 유지했지만, GPU를 통한 AI 연산 확장성은 상대적으로 제한적이었다. 그러나 AI 모델의 용량이 커지고 복잡해지면서 NPU로만 이를 처리하는 방식은 한계에 부딪혔다.
GPU는 더 높은 메모리 대역폭과 병렬 연산 유연성을 제공하기 때문에, 복합 AI 워크로드에 더 적합하다. 애플이 GPU에 AI 가속 엔진을 통합한 것은 지금까지 유지해 온 구조를 벗어나 AI 연산 중심 장치를 GPU로 옮기겠다는 의도로 읽힌다.
애플, 2017년부터 A시리즈 칩에 NPU 탑재
애플은 2017년 아이폰8·X에 탑재한 SoC 'A11 바이오닉'에 처음으로 NPU인 뉴럴엔진을 통합했다. 이는 스마트폰 분야 경쟁사인 삼성전자나 퀄컴 대비 수 년을 앞선 시도였다.

애플은 이후 출시한 아이폰용 A시리즈 SoC는 물론 이 구조를 계승해 자체 설계한 PC용 SoC인 애플 실리콘 M시리즈에도 꾸준히 뉴럴엔진을 탑재했다.
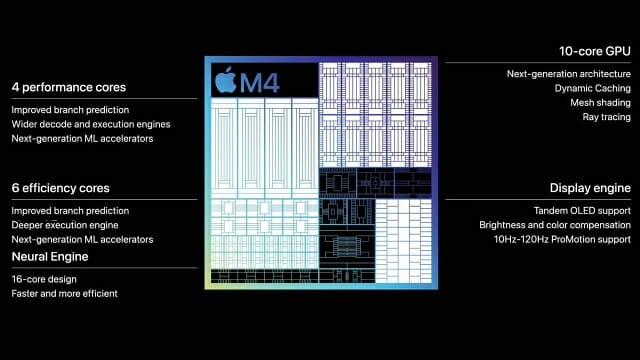
뉴럴엔진은 주로 사진·음성·자연어 처리 등 다양한 기능을 처리했다. 지난 해 공개된 애플 실리콘 M4에 탑재된 뉴럴엔진은 INT8(정수, 8비트) 기준 38 TOPS 수준의 연산 성능을 갖췄다.
애플, M5 칩 GPU 구조 개선
애플이 16일 아이패드 프로와 맥북프로 신제품에 탑재한 애플 실리콘 'M5'는 최대 10코어 CPU, 10코어 GPU와 16코어 NPU '뉴럴 엔진'으로 구성됐다.

특기할 점은 GPU 내부에 AI 연산을 가속할 수 있는 '신경망 가속기'를 통합했다는 것이다. 이는 AI 연산을 전용 NPU에만 전담시키던 기존과 달리 대부분의 AI 연산을 GPU로 우선 처리하겠다는 의도로 해석된다.
애플은 이런 구조 변경을 통해 "AI 작업 처리시 M4 대비 최대 4배 성능이 향상됐다"고 설명했다.
기준이 되는 AI 연산의 정밀도(FP16, INT8, FP8)나 벤치마크 방식은 공개되지 않았지만, CPU와 뉴럴 엔진 관련 언급은 나오지 않았다. GPU를 AI 처리의 중심에 둔 것이다.
인텔·AMD, AI 연산에 GPU 우선 활용
AI PC 시장이 본격화되면서, 인텔·퀄컴 등 주요 반도체 업체들도 GPU 기반 AI 연산을 강화하는 전략을 앞다퉈 내세우고 있다.
인텔이 올 연말부터 공급할 코어 울트라 시리즈3(팬서레이크)는 GPU의 AI 연산 성능을 전작(코어 울트라 200V) 대비 두 배 가까운 120 TOPS로 끌어올린 반면 NPU 연산 성능은 소폭 상승한 50 TOPS 수준에 머물렀다.

AMD가 공급하는 라이젠 AI 300 시리즈 역시 내장 라데온 GPU의 AI 처리 성능을 강화했다. 새로운 RDNA 3.5 아키텍처는 FP16·INT8 연산을 지원하며, NPU와 GPU가 AI 연산을 병행하는 구조를 구현했다.
NPU TOPS보다 시스템 전체 연산 성능 중요도 상승
그동안 AI 연산 성능의 기준은 NPU의 초당 연산 횟수(TOPS)로 나타났다. 그러나 GPU를 활용한 추론이 AI 연산이 주류로 부상하면서 NPU에만 의존할 수 없게 됐다.
관련기사
- 애플, M5 맥북 프로·아이패드 프로 공개…"가격은 그대로"2025.10.16
- 인텔 "팬서레이크 내장 GPU, AI 성능 2배↑"2025.10.09
- 엔비디아 윈도 PC용 'N1X' 칩, 벤치마크서 포착2025.08.04
- 기업이 AI PC 도입 망설이는 이유는2025.06.18

NPU 뿐만 아니라 GPU, CPU를 모두 조화롭게 활용해야 하는 상황인 것이다.
애플이 AI 연산 처리에 GPU를 앞세운 것은 이런 변화를 반영한 것이다. AI 연산은 더 이상 NPU라는 전용 블록의 역할이 아니라, SoC 전반이 수행해야 하는 가장 중요한 작업이 됐다.





