






[애리조나(미국)=권봉석 기자] 인텔은 2011년 '빌트인 비주얼'을 내세우며 프로세서 안에 내장 그래픽칩셋을 탑재하기 시작했다. 이후 2018년부터 자체 개발한 Xe GPU 아키텍처를 이용해 내장 그래픽칩셋과 그래픽카드 등을 시장에 공급하고 있다.
지난 해 코어 울트라 200V(루나레이크)에 탑재된 Xe2 코어 기반 GPU는 기본 성능 강화로 1080p 해상도 게임 성능을 강화했다. 코어 울트라 200V의 AI 연산 성능은 GPU 67 TOPS(1초당 1조 번 연산), 신경망처리장치(NPU)는 48 TOPS에 달한다.
인텔 차세대 모바일(노트북)용 프로세서 '팬서레이크'는 GPU AI 연산 성능을 두 배 가까운 120 TOPS, NPU 연산 성능은 소폭 상승한 50 TOPS로 높였다. 여기에 CPU(10 TOPS)를 더하면 최대 연산 성능은 180 TOPS까지 향상된다.

29일 오전(이하 현지시간) 미국 애리조나 주 '인텔 테크투어 US' 행사장에서 톰 피터슨 인텔 아키텍처, 그래픽·소프트웨어 펠로우는 "GPU와 NPU 강화는 AI와 에이전틱 워크로드(작업)가 등장하며 변화하는 PC 요구사항을 충족하기 위한 것"이라고 설명했다.
Xe3 코어 4개/6개 묶음으로 이원화... 최대 12코어 구성 가능
팬서레이크에 탑재될 내장 GPU는 Xe3 코어 기반이며 코드명 '배틀메이지', '아크 B시리즈'라는 이름으로 출시된다.

코어 울트라 200V에 탑재된 GPU는 Xe2 코어 4개와 레이트레이싱 유닛 4개를 한데 묶은 '렌더 슬라이스(조각)' 2개를 이용해 총 8코어로 구성됐다.
팬서레이크의 렌더 슬라이스는 ▲ Xe3 코어·레이트레이싱 유닛 4개 구성 ▲ Xe3 코어·레이트레이싱 유닛 6개 구성 등 총 두 개로 구성된다.


전자는 8코어 CPU(4P+4E)/16코어 CPU(4P+8E/LP 4E)와 결합되며 4코어 렌더 슬라이스 하나만 이용한다. 후자는 16코어 CPU(4P+8E/LP 4E)와 짝을 이루며 6코어 렌더 슬라이스 2개를 활용해 12코어 GPU를 만든다.
Xe3, 처리 가능 데이터에 FP8 추가
Xe3 코어는 512비트 벡터 엔진 8개, AI 연산에 필요한 XMX(Xe 행렬 확장) 엔진 8개로 전세대 Xe3 코어와 차이가 없다. 그러나 데이터를 임시 저장하는 캐시를 33% 늘려 지연 시간과 성능을 향상시켰다.

XMX 엔진은 INT2(정수 2비트), INT4, INT8, FP16(부동소수점 16비트), BF16, TF32 등 자료형을 처리할 수 있다. 여기에 정밀도에는 큰 차이가 없지만 연산 속도가 더 빠르고 배터리 소모가 적은 FP8(부동소수점 8비트) 양자화를 더했다.
AI 연산 성능은 INT8 자료형 기준 최대 120 TOPS다. 전 세대인 코어 울트라 200V 프로세서 성능을 GPU 하나만으로 감당하게 됐다.
전세대 대비 GPU 성능 최대 50% 향상
인텔은 Xe2/Xe3 대상으로 실시한 자체 벤치마크 결과를 토대로 Xe3 GPU의 성능이 전 세대 대비 평균 50% 향상됐고 깊이 쓰기(Depth write) 벤치마크에서는 7배 이상 성능이 높아졌다고 설명했다.
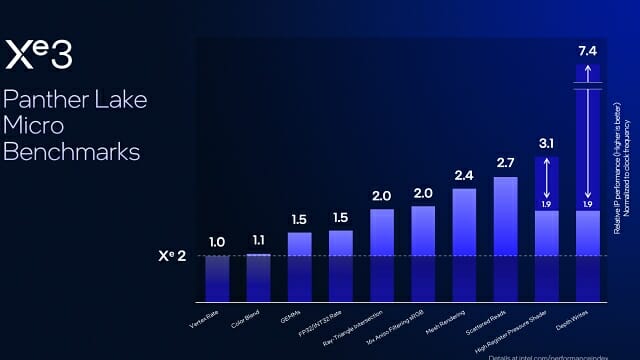
톰 피터슨 펠로우는 "Xe3 GPU의 최대 성능은 루나레이크 대비 50% 높아졌고 애로우레이크H 대비 같은 전력에서 40% 더 높은 성능을 낸다"며 "게임용 고성능 노트북뿐만 아니라 휴대성을 강조한 소형·경량 노트북에서도 GPU 경쟁력을 확보했다"고 설명했다.

인텔은 마이크로소프트와 협력해 윈도 운영체제 그래픽 라이브러리인 다이렉트X 12에 Xe3 GPU의 XMX 연산 능력을 활용하는 '협동 벡터'(Cooperative Vectors)도 도입했다. 행사에서는 이를 활용해 2D 이미지로 3차원 입체를 만드는 'NeRF' 기술도 시연했다.
NPU 5는 성능보다 작동 효율 향상에 방점
NPU는 소음 감소나 배경 흐림 등 최대한 전력을 적게 소모하며 상시 구동돼야 하는 작업에 최적화됐다. 팬서레이크에 탑재된 NPU 5도 전 세대 'NPU 4' 대비 연산 효율을 높이는 한편 인텔 18A 공정 적용으로 작동 효율을 높였다.
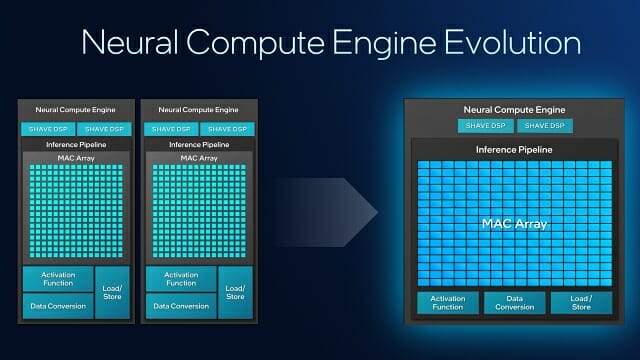
NPU 4는 AI 처리에서 주로 쓰이는 MAC(Multiply–accumulate, 곱셈 가산) 연산과 DSP 처리를 수행하는 뉴럴 컴퓨트 엔진을 6개 탑재해 48 TOPS급 성능을 구현했다. 반면 NPU 5는 뉴럴 컴퓨트 엔진 수를 줄이는 대신 MAC를 처리하는 'MAC 어레이' 크기를 2배로 늘렸다.
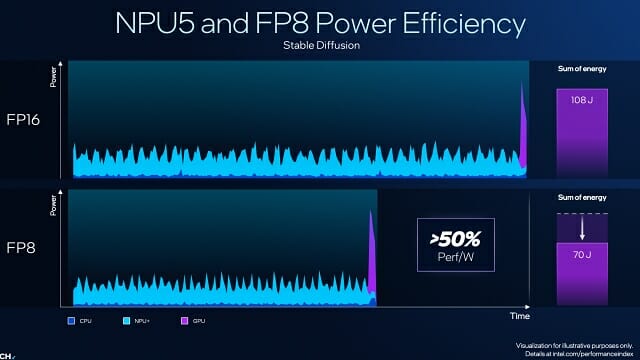
톰 피터슨 펠로우는 "NPU 5는 FP16 대비 에너지 소모를 50% 줄이면서 유사한 품질을 얻을 수 있는 FP8(부동소수점 8비트)를 지원해 스테이블 디퓨전 등 생성 AI 작업에 필요한 전력량을 108J(줄)에서 30% 낮은 70J(줄)까지 끌어내렸다"고 설명했다.
Xe3 4코어 GPU는 인텔 3 공정서 생산 예정
인텔은 노트북용 프로세서에 탑재되는 대부분의 내장·외장 GPU를 대부분 인텔 파운드리가 아닌 대만 TSMC에서 생산했다. 그러나 팬서레이크부터는 GPU 타일 중 Xe3 4코어 내장 제품을 극자외선(EUV) 기반 자체 공정인 인텔 3(Intel 3)에서 생산 예정이다.
관련기사
- 인텔 "팬서레이크, 성능·효율성 모두 잡은 차세대 플랫폼"2025.10.09
- "팬서레이크 CPU 코어, 반응성·성능 동반 향상"2025.10.09
- "인텔 파운드리, 양대 신기술 적용 1.8나노 반도체 첫 상용화"2025.10.09
- 인텔 "AI 미래, 이기종 컴퓨팅과 개방성에 달렸다"2025.10.09
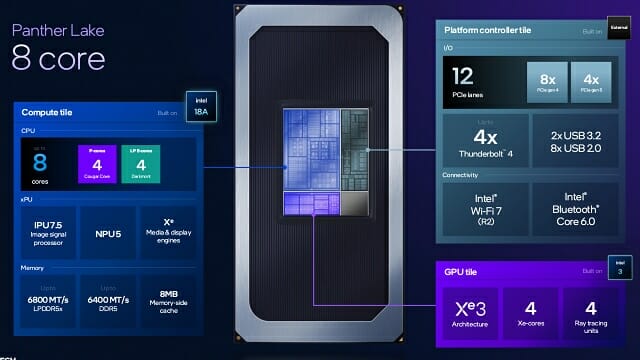
팬서레이크는 레이트레이싱과 그래픽 연산에 필요한 각종 요소를 떼어내 GPU 타일로 분리했다. CPU는 그대로 두고 GPU를 더 강력한 제품으로 교체하는 것도 얼마든지 가능하다. 인텔은 이를 위해 더 강력한 GPU인 'Xe3P'도 준비중이다.
톰 피터슨 펠로우는 "CPU(경량 AI 모델), NPU(저전력 상시구동 윈도11 코파일럿+), GPU(대형언어모델 / 생성 AI) 등 3개 요소를 균형있게 강화해 AI 처리를 최적화하는 것이 인텔 목표"라고 강조했다.





