






스마일서브가 인공지능(AI) 서비스 개발 기업을 겨냥해 '올라마(Ollama)' 프레임워크 기반의 솔루션을 새롭게 선보인다.
스마일서브는 대규모 언어 모델(LLM) 구축에 최적화된 그래픽처리장치(GPU) 클라우드 및 서버 호스팅 상품을 출시했다고 1일 밝혔다.
이번 상품은 올라마 프레임워크 기반으로 AMD와 엔비디아 GPU를 혼합해 다양한 선택지를 제공하는 것이 특징이다.
올라마는 GPU·신경망처리장치(NPU) 호환성이 넓어 가성비 높은 LLM 모델 구축 환경을 원하는 개발자와 서비스 기업 사이에서 각광받고 있다. 올해 초 저가형 게임용 GPU에서도 LLM 서비스 운용이 가능하다는 점이 알려지면서 엔비디아 주가에 일시적 영향을 줄 정도로 주목을 받은 바 있다.
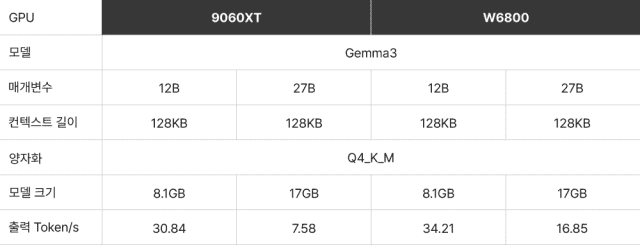
스마일서브는 AMD 라이젠 CPU 내장 GPU, 라데온 RX 9600 XT, W6800 프로 GPU 등을 자사 '클라우드브이' 서버 호스팅 서비스에 적용했다. 기존 엔비디아 중급 GPU 라인업은 올라마 전용 구성으로 리뉴얼해 새롭게 선보일 계획이다.
스마일서브는 데이터센터에서 활용도가 낮았던 내장 GPU도 올라마를 통해 LLM 서비스에 적용할 수 있게 됐으며 이를 활용해 8GB VRAM 환경을 지원하는 신규 서버 호스팅 상품을 출시했다.
스마일서브 이유미 대리는 "8GB VRAM 환경에서도 젬마 3 4B 모델을 포함한 중소형 LLM 모델 설치가 가능하다"며 "내장 GPU만으로 업무 자동화나 간단한 챗봇 운영이 가능해졌다"고 말했다.
이어 "DDR5 기반 라이젠 PC와 노트북 내장 GPU에서도 설치가 가능해 저비용 개발 환경을 원하는 이용자라면 자사 블로그 가이드를 참고해 직접 구현할 수 있다"고 덧붙였다.
새롭게 추가된 라데온 GPU도 눈에 띈다. 지난 6월 출시된 RX 9060 XT는 가성비 최강으로 평가받는 제품으로, 16GB VRAM을 탑재해 젬마 3 12B 등 중대형 모델도 안정적으로 지원한다. 함께 출시된 라데온 프로 W6800은 32GB VRAM을 갖춰 젬마 3 27B 같은 초대형 모델도 무리 없이 운영할 수 있다.
스마일서브는 이 GPU 기반으로 자사 챗봇을 개발 중이며 응답 정확도를 90% 수준까지 끌어올린 상태다. 정식 서비스는 이달 중 출시될 예정이다.
엔비디아 중급 GPU 라인업도 올라마 특화 GPU 클라우드 서비스 '아이윈브이'에서 새롭게 전면 배치된다. 이 라인업은 최소 16GB VRAM부터 최대 96GB까지 지원하는 다양한 GPU로 구성됐다. 특히 GDDR7 VRAM을 탑재한 제품군을 중심으로 LLM 운영에서 발생할 수 있는 메모리 부족 문제를 해결하는 데 초점을 맞췄다.
관련기사
- 서버용 AI칩, 향후 5년간 성장세 견조…"370兆 규모 성장"2025.08.30
- 쿠팡 AI 클라우드 컴퓨팅, ‘인텔리전트 클라우드’로 재단장2025.07.02
- 엘리스그룹-엔비디아, 원데이 워크숍에 20명 초청한다2025.06.19
- AMD, 차세대 AI 가속 GPU '인스팅트 MI350' 공개2025.06.13
스마일서브는 장기 이용자 대상 1년 약정 시 정가 대비 50% 할인 혜택을 제공하는 프로모션도 준비 중이다.
스마일서브 관계자는 "GPU 호스팅 상품은 GPU 가격뿐 아니라 서버·전력·공간·회선 등 다양한 요소가 단가에 영향을 주기에 가격을 낮추기 쉽지 않지만, 신규 론칭 단계에서 최대한 비용을 억제하고 가성비를 확보했다"고 밝혔다.





