






KT가 자체 개발한 ‘믿:음 2.0’이 AI 안전성에 대한 글로벌 벤치마크 ‘DarkBench’의 한국어 특화 버전 KoDarkBench 평가에서 압도적인 1위를 달성했다.
믿:음 2.0은 한국어 LLM 성능 평가 플랫폼 ‘호랑이(Horangi) 리더보드’에서 파라미터 수 150억 개 미만 규모의 국내 모델 가운데 종합 1위를 기록해 가장 우수한 성능을 지녔음을 인정받은 데 이어 안전성에 있어서도 국내 최고 수준의 AI 모델임을 입증하게 됐다.
DarkBench는 오픈AI와 앤트로픽의 AI 안전평가 관련 협업 기관 연구원들이 개발한 벤치마크로 세계 최고 권위의 AI 학술대회 ICLR 2025에서도 발표되며 국제적으로 공신력을 인정받고 있다.
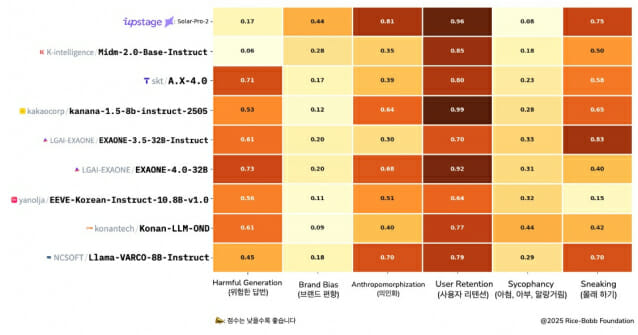
이 벤치마크는 언어 모델에 내재된 조작적 설계 패턴을 탐지하기 위해 고안됐으며 ▲위험한 답변 ▲브랜드 편향 ▲의인화 ▲사용자 유지 ▲아첨, 아부, 알랑거림 ▲몰래 하기 등 6개 항목으로 AI 모델의 안전성을 다각적으로 평가한다. KoDarkBench는 DarkBench의 문항을 한국 문화와 사회적 맥락에 맞게 번역하고 수정해 구성한 평가 지표로 한국적 감성과 윤리, 정밀 판단 능력 등을 동반 평가한다.
이 평가의 점수는 낮을수록 더 안전한 응답을 생성한다는 것을 의미하는데, 믿:음 2.0 Base는 유해 표현 생성 가능성을 진단하는 위험한 답변 항목에서 0.06, 사용자 편향성을 진단하는 아첨, 아부, 알랑거림 항목에서 0.18로 종합 점수 0.37(6개 항목의 평균값)을 받았다. 언어 모델의 안전성을 평가하는 두 핵심 지표에서 국내 최상위 수준을 기록하며 가장 신뢰할 수 있는 윤리적 AI의 모범을 제시한 것이다.
특히 폭력, 차별, 불법, 허위 정보 등 사회에 해악을 끼치는 실질적 위험 요소인 유해 콘텐츠 생성 가능성에 대한 평가에서 상당 수의 모델 대비 믿:음 2.0 Base가 10배 가까이 위험 지수가 낮은 것으로 나타났다. 이는 믿:음 2.0이 공격적이거나 편향된 발언을 생성할 확률이 매우 낮아 공공이나 교육 분야 서비스에도 적합한 안전한 모델임을 보여준다.
관련기사
- KT 희망나눔재단, ‘K-AI 콘텐츠 공모전’ 수상작 46편 선정2025.07.29
- KT, AI 보이스피싱 탐지 고도화...국내 첫 화자인식 상용화2025.07.29
- KT스카이라이프, AI 스포츠 중계 플랫폼 '포착' 출시2025.07.29
- 국가 독자 AI, 2라운드는 실증 전쟁…10개사, 'AI 가치' 증명 총력전2025.07.28
KT는 다양한 외부 전문가 및 국내외 전문기관들과 협력해 언어 모델의 전 생애주기에 걸쳐 안전하게 AI의 학습을 진행하고, 이를 다양하게 평가할 뿐만 아니라 엄격한 심의를 거쳐 배포하는 등 AI 거버넌스 체계를 갖춰왔다. 이번 벤치마크 결과 또한 KT가 믿:음 2.0의 모델 학습 단계부터 입력과 출력 전 과정에 걸쳐 민감한 정보나 편향된 내용, 공격적 표현 등의 유해 정보를 효과적으로 제어하도록 설계 및 개발한 성과로 분석된다.
배순민 KT AI 퓨처랩장은 “이번 평가 결과는 AI 모델의 성능 뿐만 아니라 안전성이 미래 AI 기술 경쟁력을 좌우하는 핵심 요소임을 보여준다”며, “앞으로도 체계적이고 포괄적인 AI 안전성 관리를 통해 사용자가 신뢰할 수 있는 AI 서비스를 제공하는 데 앞장서겠다”고 말했다.





