오픈AI가 차세대 인공지능(AI) 모델 'GPT-4.1' 시리즈를 회사 애플리케이션 프로그램 인터페이스(API) 중심 전략의 핵심으로 삼았다. 기존 고사양 모델의 부담을 줄이고 실사용 효율성을 높이려는 전략이지만 업계 일각에서는 기대와 우려가 엇갈리는 분위기다.
오픈AI는 'GPT-4.1' 기본형과 경량형 모델을 함께 제시하고 고비용 모델인 'GPT-4.5'는 오는 7월을 기점으로 단계적으로 퇴장시킬 계획이라고 15일 밝혔다. 새로운 '4.1' 시리즈에는 멀티모달 기능과 장문 대응 구조를 적용하며 사용자 범용성을 강화했다는 점을 강조했다.
다만 '4.1'의 실제 성능과 가격 구조를 놓고는 회의적인 시선도 제기된다. 일부 벤치마크 결과에서 경쟁 모델에 비해 정확도가 낮게 나타났고 지표 구성 방식에 대한 지적도 뒤따르며 향후 시장 내 경쟁력에 관심이 쏠린다.

멀티모달·장문 대응 갖춰…'4.5'는 5개월 만에 퇴장
오픈AI는 새로 출시된 'GPT-4.1' 시리즈가 프론트엔드 앱 생성, 코드 리뷰, 문서 분석, 고객 응대 등 실사용 환경에 더욱 적합하도록 최적화됐다고 설명했다. 특히 프로그래밍 업무의 생산성을 높이는 데 중점을 두고 개발됐으며 기존 'GPT-4o'보다 다양한 지시 유형과 포맷을 정확하게 따를 수 있다는 것이다.
'GPT-4.1' 시리즈의 입력당 가격은 모델별로 구분된다. 가장 성능이 높은 'GPT-4.1'은 입력 1백만 토큰당 2달러(한화 약 2천800원), 출력은 8달러(한화 약 1만1천200원)다. 'GPT-4.1 미니'는 입력 당 0.4달러(한화 약 560원), 출력 1.6달러(한화 약 2천200원)로 책정됐다.
가장 작은 'GPT-4.1' 나노는 입력 0.1달러(한화 약 160원), 출력 0.4달러(한화 약 640원)로 가격 접근성이 높다. 동일 프롬프트를 반복 사용하는 경우에는 최대 75%까지 입력 요금 할인이 적용된다.

이러한 'GPT-4.1'의 투입은 고성능 모델로 자리했던 'GPT-4.5'의 단계적 종료와 맞물린다. 오픈AI는 오는 7월을 기점으로 'GPT-4.5' 애플리케이션 프로그램 인터페이스(API) 제공을 종료하고 후속 제품인 'GPT-4.1'을 주력 모델로 대체한다고 밝혔다. 'GPT-4.5'의 연산 비용이 지나치게 높아 상용화 부담이 컸기 때문이라는 점이 교체의 배경으로 제시됐다.
'GPT-4.5'는 지난 2월 말 발표된 오픈AI 최대 규모 모델로, 보다 많은 학습량과 계산 자원을 투입해 설득력과 문장 구성 능력을 개선한 바 있다. 그럼에도 출시 5개월 만에 API 시장에서 퇴장 수순을 밟게 되면서 'GPT-4.1'이 향후 오픈AI의 API 전략을 실질적으로 이끌 주력 제품이 될 것으로 전망된다.
"개선된 게 맞나"…벤치마크 해석·가성비 논란에 경쟁력 의문
이같이 오픈AI가 'GPT-4.1'이 향상된 명령 이행력과 코딩 성능을 가졌다고 전면에 내세웠지만 실제 성능을 두고는 업계 일각에서 회의적인 시선이 나온다.
실제로 'GPT-4.1'은 오픈소스 프로젝트의 코드 이슈를 해결하는 능력을 평가하는 SWE-벤치 베리파이드(SWE-bench Verified) 기준 54.6%의 정확도를 기록했지만 같은 지표에서 구글의 제미니 2.5 프로는 63.8%, 앤트로픽의 클로드 3.7 소넷은 62.3%로 오히려 더 높은 수치를 보였다. 자연어 기반 코드 수정과 리팩토링 성능에서 오픈AI가 경쟁사보다 앞서 있다고 보긴 어려운 수치다.
가격 대비 성능에서도 의문이 제기된다. 'GPT-4.1'은 입력 1백만 토큰당 2달러, 출력은 8달러로 책정돼 가격이 높은 편이다. 같은 범주의 제품인 구글 '제미나이 2.5 프로'는 출력 단가는 10달러(한화 약 1만4천원)로 다소 높지만, 입력 요금은 1.25달러(한화 약 1천500원)로 저렴하다. SWE-벤치 코딩 성능에서 입력 단가가 낮은 '제미나이 2.5' 모델이 더 높은 정확도를 기록한 만큼, 가성비 면에서는 오픈AI가 밀린다는 평가다.
'미니' 모델도 상황은 비슷하다. 입력 비용이 경쟁 프로덕트인 구글 '제미나이 플래시'보다 2배 이상 비싸지만 성능은 오히려 낮다는 분석이 뒤따른다. 컨텍스트 캐싱을 적용하지 않는 경우에는 가격 차이가 더 벌어져 규모가 작은 프로젝트에서 선택하기 어려운 구조다.
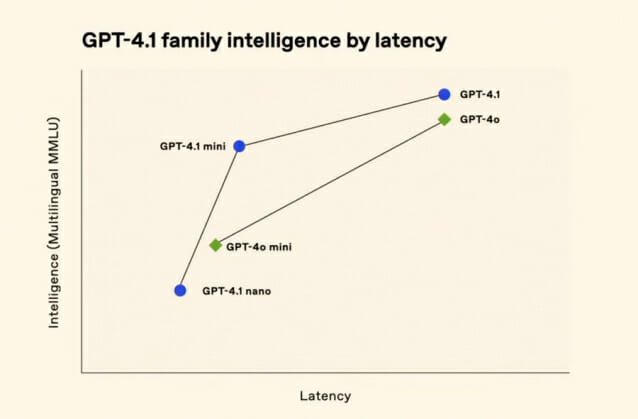
오픈AI의 벤치마크 구성 방식에 대한 지적도 나온다. 'GPT-4.1'의 성능을 보여주는 공식 차트에는 고난도 문제와 논리 추론 항목이 포함된 공신력 있는 벤치마크인 표준 MMLU 대신 다국어 MMLU(M-MMLU)가 사용됐기 때문이다.
MMLU는 다양한 학문 분야의 지식과 추론 능력을 평가하는 대표적 지표로, 표준 MMLU는 영어 기반으로 구성되며 M-MMLU는 이를 여러 언어로 번역한 버전이다. 원본보다 번역된 문항이 많아 모델에 유리하게 작용할 가능성이 있다는 분석도 나온다. 고난도 문제를 포함한 MMLU-프로 성능은 아예 공개되지 않았다.
관련기사
- 中 딥시크에 자극 받은 오픈AI, 'GPT-4.5'로 격차 벌리기 총력2025.02.28
- 오픈AI, 새 모델 GPT 4.1 공개 예정2025.04.12
- 오픈AI, MS 애저에 'GPT-4.5' 곧 탑재…GPT-5도 준비2025.02.21
- 알트먼 "GPT-4.5, 몇 주내 출시"…추론 모델 'o' 버린다2025.02.13
이외에도 오픈AI가 공개한 차트의 y축 수치가 표시되지 않아 모델 간 실제 성능 격차를 시각적으로 축소하려는 의도가 아니냐는 해석도 있다. 점수 차이가 적음에도 불구하고 동일한 막대 높이로 표시돼 상대적 우위를 부각시키는 방식이 아니냐는 지적이다.
테크크런치는 "'GPT-4.1'은 SWE-벤치 기준으로만 보면 전작보다 향상된 결과를 보이지만 실제 활용 환경에서는 여전히 보완이 필요하다"고 평가했다.