






현대 AI의 새로운 도전: 70-80%를 차지하는 어텐션 계산 문제
딥시크(DeepSeek)가 발표한 연구 논문에 따르면, 차세대 AI 언어모델에서 긴 문맥 처리 능력이 매우 중요해지고 있다. 심층 추론, 저장소 수준의 코드 생성, 다중 턴 자율 에이전트 시스템 등 실제 응용 사례가 증가하면서 긴 문맥 처리의 중요성이 더욱 부각되고 있다. (☞ 논문 바로가기)
오픈AI의 O-시리즈 모델, 딥시크-R1(DeepSeek-R1), 제미니 1.5 프로(Gemini 1.5 Pro) 등은 이미 전체 코드베이스나 긴 문서를 처리하고, 수천 개의 토큰에 걸친 일관된 대화를 유지할 수 있다. 하지만 6만4천 토큰 길이의 문맥을 처리할 때 기존 소프트맥스 어텐션 구조는 전체 지연 시간의 70-80%를 차지하는 심각한 병목 현상을 보이고 있다.
기존 스파스 어텐션 접근법의 한계 분석
연구진은 기존의 스파스 어텐션 방식들을 세 가지 유형으로 분류하고 각각의 한계를 분석했다. 고정 스파스 패턴을 사용하는 슬라이딩윈도우 방식은 메모리와 계산 비용을 줄일 수 있지만, 전체 문맥 이해가 필요한 작업에서 성능 제한을 보였다. H2O와 SnapKV 같은 동적 토큰 제거 방식은 디코딩 중 KV-캐시 메모리 사용을 줄이는 데 효과적이었으나, 미래 예측에 중요한 토큰을 놓칠 위험이 있었다. Quest, InfLLM, HashAttention, ClusterKV 등 쿼리 기반 선택 방식은 청크 단위로 중요도를 평가해 토큰을 선택하지만, 학습 단계에서의 최적화가 어려운 한계가 있었다.
기술 구현의 실제적 도전과 해결
기존 접근법들의 가장 큰 문제는 이론적인 계산량 감소가 실제 속도 향상으로 이어지지 않는다는 점이었다. 연구진은 이를 '효율적 추론의 환상'이라 명명하고, 두 가지 주요 원인을 지적했다. 첫째, 디코딩이나 프리필링 단계 중 하나에만 최적화되어 전체 추론 과정의 효율성이 떨어지는 '단계 제한적 희소성' 문제가 있었다. 둘째, MQA(Multiple-Query Attention)나 GQA(Grouped-Query Attention)와 같은 최신 어텐션 아키텍처와의 호환성 부족으로 인해 메모리 접근 패턴이 비효율적이었다. NSA는 이러한 문제들을 계층적 토큰 모델링과 하드웨어 최적화를 통해 해결했다.
NSA 구조: 3단계 병렬 어텐션으로 최적화된 문맥 처리
딥시크의 NSA(Native Sparse Attention)는 세 가지 병렬 어텐션 경로를 통해 입력 시퀀스를 처리한다. 압축된 거시적 토큰, 선택적으로 유지된 미시적 토큰, 지역 문맥 정보를 위한 슬라이딩 윈도우를 결합한 것이 특징이다. 구체적인 구현에서는 압축 블록 크기(l) 32, 슬라이딩 스트라이드(d) 16, 선택 블록 크기(l') 64, 선택 블록 수(n) 16(초기 1블록과 지역 2블록 포함), 슬라이딩 윈도우 크기(w) 512를 적용했다.
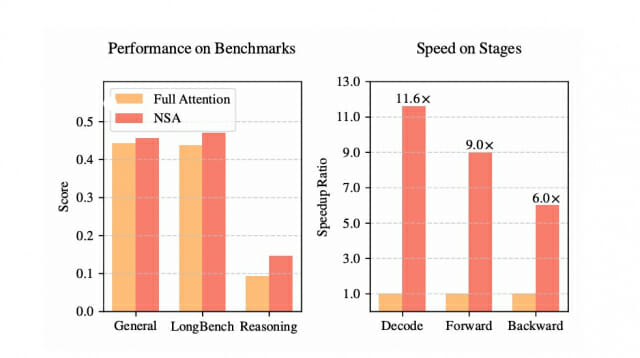
벤치마크 성능: 9개 중 7개 지표에서 기존 모델 상회
NSA를 적용한 모델은 지식(MMLU, MMLU-PRO, CMMLU), 추론(BBH, GSM8K, MATH, DROP), 코딩(MBPP, Humaneval) 분야의 벤치마크 테스트에서 기존 풀 어텐션 모델을 크게 앞섰다. 특히 DROP 테스트에서 +0.042, GSM8K에서 +0.034의 성능 향상을 보였으며, 9개 평가 지표 중 7개에서 더 우수한 성능을 기록했다. 롱벤치(LongBench) 평가에서도 NSA는 0.469점을 기록해 풀 어텐션(0.437)과 다른 스파스 어텐션 방식들을 모두 능가했다.
처리 속도: 최대 11.6배 향상된 디코딩 성능
8-GPU A100 시스템에서 진행된 성능 테스트에서 NSA는 6만4천 토큰 길이의 시퀀스 처리 시 디코딩에서 11.6배, 순방향 전파에서 9.0배, 역방향 전파에서 6.0배의 속도 향상을 달성했다. 특히 디코딩 단계에서는 메모리 접근 횟수를 크게 줄여 기존 모델이 필요로 하는 65,536 토큰 대비 5,632 토큰만으로도 처리가 가능했다.
수학적 추론: 16K 문맥에서 14.6% 정확도 달성
딥시크-R1의 지식을 증류하여 32K 길이의 수학적 추론 트레이스로 10B 토큰의 지도 학습을 수행한 결과, NSA-R 모델은 미국 수학 초청 시험(AIME) 벤치마크에서 8K 문맥에서 12.1%, 16K 문맥에서 14.6%의 정확도를 달성했다. 이는 동일 조건에서 기존 풀 어텐션 모델이 보인 4.6%와 9.2%를 크게 상회하는 결과다.
기술적 혁신: 하드웨어 최적화와 종단간 학습 지원
관련기사
- [Q&AI] 코인시장 불 지핀 '파이코인', 뭐길래... OKX 거래 방법은2025.02.21
- "정부 덜 멍청하게 만들자"…머스크 측근이 만든 AI 공무원2025.02.19
- 딥러닝 대가가 '그록3' 평가했더니…제미나이·클로드 못푸는 문제도 해결2025.02.20
- AI발 메모리 대란, 자동차 업계도 덮쳤다2026.07.25
NSA는 텐서 코어 활용과 메모리 접근을 최적화한 하드웨어 친화적 알고리즘 설계를 통해 이론적 계산량 감소를 실제 속도 향상으로 이어지게 했다. 또한 27B 파라미터 트랜스포머 모델에 260B 토큰으로 사전학습을 수행하며 종단간 학습이 가능한 구조를 입증했다. 이는 기존 스파스 어텐션 방식들이 추론 단계에만 적용되거나 학습 효율성이 떨어지는 한계를 극복한 것이다.
■ 이 기사는 AI 전문 매체 ‘AI 매터스’와 제휴를 통해 제공됩니다. 기사는 클로드 3.5 소네트와 챗GPT를 활용해 작성되었습니다. (☞ 기사 원문 바로가기)





