중국 알리바바가 생성형 인공지능(AI) 초거대 모델 신규 시리즈를 공개하면서 미국 메타의 모델을 뛰어넘었다고 강조했다.
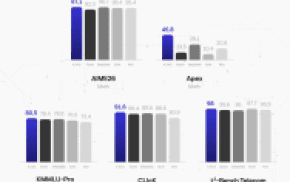
19일 중국 언론 IT즈자에 따르면 알리바바클라우드의 저우징런 CTO는 "퉁이쳰원의 신규 오픈소스 모델 '큐원 2.5' 중 큐원 2.5-72B 모델의 성능이 메타의 '라마 405B' 성능을 뛰어넘었다"고 밝혔다.
이날 알리바바는 지난 9월 중순 기준 퉁이쳰원 오픈소스 모델의 누적 다운로드 수가 4천 만 건을 넘어서, 메타의 라마에 이어 세계적 수준의 모델 그룹이 됐다고도 공식적으로 밝혔다. 큐원 시리즈 파생 모델 총 수량이 5만 개를 넘어서면서 라마에 이어 세계 2위의 모델군이 됐다.
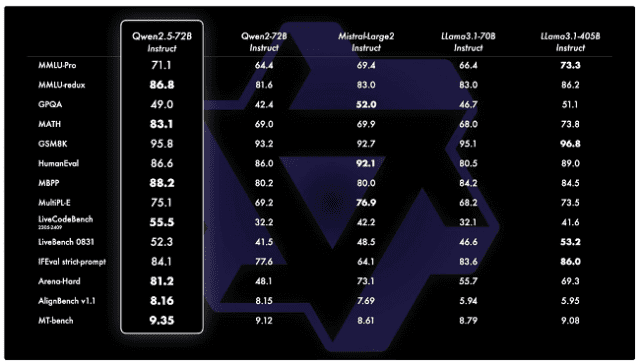
큐원 2.5는 이날 알리바바클라우드가 '2024 압사라 컨퍼런스'에서 발표한 모델이다. 큐원2.5-72B가 주력 모델이다. 72B는 매개 변수 숫자를 의미하며, 720억 개의 매개 변수를 지원한단 의미다.
큐원 2.5는 대규모 언어 모델, 멀티 모달 모델, 디지털 모델, 코딩 모델 등이 크기와 버전 별로 총 100여 개 포함돼있다.
데이터 관점에서 봤을 때, 모든 큐원2.5 시리즈 모델은 18T 토큰 데이터로 사전훈련돼있으며, 기존 큐원2와 비교해 전반적 성능이 18% 이상 향상됐다. 컨텍스트는 8K~128K(약 8천~12만8천 개 토큰) 길이로 생성할 수 있으며, 챗봇 작업도 구현한다.
관련기사
- 알리바바 클라우드가 파리올림픽 중계 몰입도 높인 비결은?2024.08.12
- 오픈AI 中 서비스 중단…알리바바 '큐원2'가 대안될까2024.08.09
- 中 언론 "알리바바, 올림픽 최초 AI 초거대 모델 공급 기업"2024.07.25
- "오픈소스 성공적"...메타, LLM 라마 전년 대비 10배 성장2024.08.30
큐원 2.5는 특히 명령 따르기, 이해 구조화 데이터, 구조화 데이터 출력 생성 등에서 상당한 진전을 이뤘다고 소개됐다. 또 코딩용 '큐원2.5-코더'와 수학용 '큐원2.5-매스'가 전 세대에 비해 눈에 띄게 발전했다.
큐원2.5-코더는 프로그래밍 관련 데이터 최대 5.5T 토큰 훈련을 받았으며, 큐원2.5-매스는 중국어와 영어로 된 이중 언어 수학 문제를 풀기 위해 사고 체인과 툴통합추론(TIR) 사용을 지원한다.