






한국지능정보사회진흥원(NIA, 원장)은 업스테이지(대표 김성훈, 영어명 성킴)와 공동 운영하는 ‘Open Ko-LLM 리더보드’가 시즌2로 전면 개편했다고 12일 밝혔다. 추론능력, 감성, 무해성, 등 9개의 새로운 지표를 적용, 성능을 측정한다. 시즌1에서는 5개 지표(4개는 허깅페이스 벤치마킹,1개는 고대 임희석 교수 마련)를 적용했다.
‘Open Ko-LLM 리더보드’는 지난해 9월 민관협력을 통해 개설한 국내 최대 개방형 한국어 LLM 평가 체계다. 산·학·연 각계 분야에서 올 7월 말 기준 1700개가 넘는 LLM 모델을 제출해 평가를 받았다. 하지만 LLM 기술이 빠르게 발전함에 따라 1년 전에 만든 리더보드 벤치마크(평가지표)의 개선 필요성이 제기됐다. NIA가 벤치마킹한 글로벌 ‘Open LLM 리더보드’를 운영 중인 허깅페이스도 지난 6월 6개 항목의 성능 평가로 구성한 새로 개편한 리더보드 시즌2를 공개한 바 있다.
허깅페이스가 새로 마련한 6가지 성능 지표는 ▲MMLU-Pro(Massive Multitask Language Understanding-Pro version, MMLU(대규모 다중 작업 언어 이해) 데이터셋 개정판. 모델에게 10가지 선택지를 제공하고 더 많은 질문에서 추론을 요구) ▲GPQA(Google-Proof Q&A Benchmark, 대학원 수준의 구글 검증 Q&A 벤치마크. 생물학, 물리학, 화학 분야의 박사급 도메인 전문가가 만든 고난도 지식 데이터셋) ▲MUSR(Multistep Soft Reasoning, 약 1000단어 길이의 복잡한 문제들로 구성. 추론과 긴 문맥 분석 능력을 통해 해결하는 능력 평가) ▲MATH(Mathematics Aptitude Test of Heuristics, 고등학교 수준의 경쟁 문제들로 구성) ▲IFeval(Instruction Following evaluation, 주어진 지시를 얼마나 잘 이해하고 따르는지를 평가. '키워드 ★ 포함' '△형식 사용'과 같은 명시적인 지시를 따르는 모델 능력 평가) ▲BBH(Big Bench Hard, 객관적인 지표를 사용해 수학, 상식 추론 등에 대해 평가) 등이다.
NIA '리더보드'에 대해 일각에서는 "자본을 투입해 일시적으로 성능을 높일 수 있다"면서 "LLM 생태계를 교란시키고 엔드 투 엔드 딜리버리 품질을 하향 평준화 시키는 이런 리더보드를 왜 운영해야 하는 지 모르겠다"는 비판적 시각도 보였다.
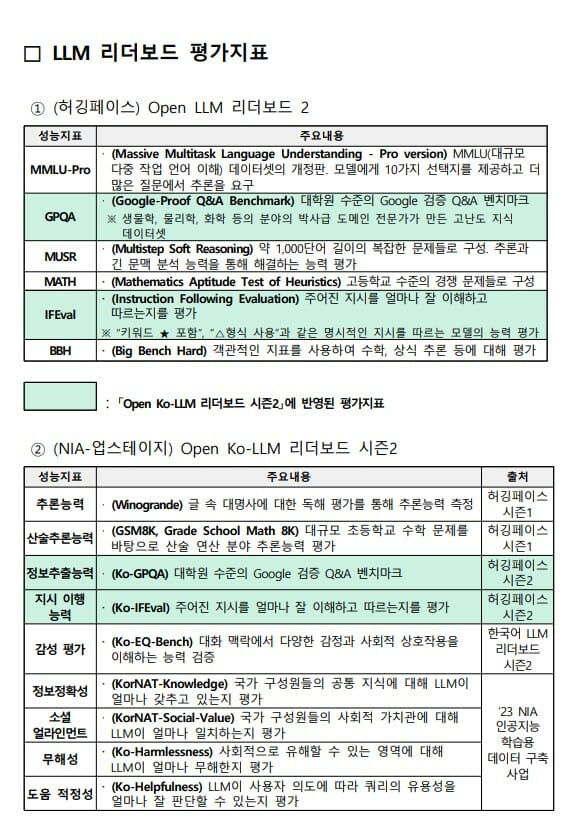
12일부터 시행하는 NIA의 '시즌2 리더보드'는 기존에 운영한 평가지표(벤치마크)들을 전면 폐지하고, AI 데이터 전문 기업인 ‘플리토’와 ‘셀렉트스타’, ‘KAIST AI대학원’이 참여해 만든 추론능력 지표, 감성 지표, 무해성 지표 등 9개의 새로운 벤치마크를 적용한다. NIA는 시즌1에 제출한 모든 모델을 포함해 향후 제출하는 모든 LLM은 신규 벤치마크를 통해 평가한다.
관련기사
- 업스테이지-플리토, 아시아 다국어 AI모델 함께 만든다2024.05.09
- 오픈AI, AI모델 정확성 높이는 비법 공개2024.05.09
- "더 똑똑하고 저렴"…마이크로소프트, 소형 AI모델 '파이3 미니' 출시2024.04.24
- "韓 피지컬 AI, 첨단 제조업 위에 온디바이스 반도체 뿌리내려야"2026.07.08
황종성 NIA 원장은 "리더보드는 민관 협업을 통해 한국어 LLM 생태계 조성에 크게 기여하고 있다"면서 "시즌2 개편을 통해 한국어 LLM 기술이 세계적 수준에 한발 더 올라설 수 있는 계기가 되기를 기대한다”고 밝혔다. 공동 운영기관인 업스테이지의 박찬준 리더는 “많은 전문기업과 학계 참여로 시즌2를 빠르게 준비할 수 있었으며, 시즌2에서도 지속적인 관심과 참여를 부탁한다”고 전했다.
Open Ko-LLM 리더보드 시즌2는 AI허브(https://www.aihub.or.kr) 사이트의 참여하기-리더보드 메뉴에서 확인 할 수 있다.





