



엔비디아의 GPU 성능을 넘어서는 고용량·고성능 AI 가속기가 상용화 수준으로 개발됐다.
이 기술을 개발한 KAIST 정명수 전기및전자공학부 교수는 "빅테크 기업들의 러브콜이 이어지고 있다"며 “대규모 AI 서비스를 운영하는 이들의 메모리 확장 비용을 획기적으로 낮추는 데 기여할 것"이라고 말했다.
KAIST(총장 이광형)는 차세대 GPU간 연결기술인 CXL(Compute Express Link)를 새로 설계해 고용량 GPU 장치의 메모리 읽기/쓰기 성능을 최적화하는데 성공했다고 8일 밝혔다.
연구는 전기및전자공학부 정명수 교수의 컴퓨터 아키텍처 및 메모리 시스템 연구실이 수행했다. 연구결과는 미국 산타클라라 USENIX 연합 학회와 핫스토리지 연구 발표장에서 공개한다.

GPU 내부 메모리 용량은 수십 기가바이트(GB, 10의9승)에 불과해 단일 GPU만으로는 모델을 추론·학습하는 것이 불가능하다.
업계에서는 대안으로 GPU 여러 대를 연결하는 방식을 채택하지만, 이 방법은 최신 GPU가격이 비싸 총소유비용(TCO·Total Cost of Ownership)을 과도하게 높인다.
이에 따라 산업계에서는 차세대 인터페이스 기술인 CXL를 활용해 대용량 메모리를 GPU 장치에 직접 연결하는‘CXL-GPU’구조 기술이 활발히 검토되고 있다.
CXL-GPU는 CXL을 통해 연결된 메모리 확장 장치들의 메모리 공간을 GPU 메모리 공간에 통합시켜 고용량을 지원한다. CXL-GPU는 GPU에 메모리 자원만 선택적으로 추가할 수 있어 시스템 구축 비용을 획기적으로 절감할 수 있다.
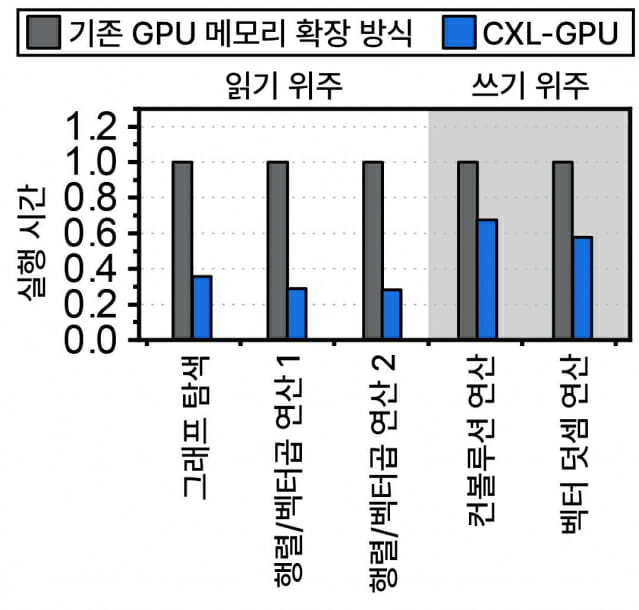
그러나 여기에도 근본적인 한계가 있다. 기존 GPU 성능 대비 CXL-GPU의 읽기 및 쓰기 성능이 떨어진다는 점이다. 아무리 GPU가 연산처리를 빨리 해도 CXL-GPU가 이를 같은 속도로 처리하지 못한다.

연구팀이 이 문제를 해결했다.
메모리 확장 장치가 메모리 쓰기 타이밍을 스스로 결정할 수 있는 기술을 개발했다. GPU 장치가 메모리 확장 장치에 메모리 쓰기를 요청하면서 동시에 GPU 로컬 메모리에도 쓰기를 수행하도록 시스템을 설계했다.
메모리 확장 장치가 내부 작업을 수행 상태에 따라 작업 하도록 했다. GPU는 메모리 쓰기 작업의 완료 여부가 확인될 때까지 기다릴 필요가 없다.
연구팀은 또 메모리 확장 장치가 사전에 메모리 읽기를 수행할 수 있도록 GPU 장치 측에서 미리 힌트를 주는 기술을 개발했다. 이 기술을 활용하면 메모리 확장 장치가 메모리 읽기를 더 빨리 시작한다.
GPU 장치가 실제 데이터를 필요로 할 때는 캐시(작지만 빠른 임시 데이터 저장공간)에서 데이터를 읽어 더욱 빠른 메모리 읽기 성능을 달성할 수 있다.
이 연구는 반도체 팹리스 스타트업인 파네시아(Panmnesia)의 초고속 CXL 컨트롤러와 CXL-GPU 프로토타입을 활용해 진행됐다.
테스트 결과 기존 GPU 메모리 확장 기술보다 2.36배 빠르게 AI 서비스를 실행할 수 있음을 확인했다.
관련기사
- CPU·GPU 에너지 사용 100만분의 1로 줄인 '열컴' 나오나2024.06.26
- GPU 포기설 부인한 인텔...2세대 '배틀메이지' 온다2024.06.04
- '10코어 GPU' M2 아이패드 에어, 알고보니 9코어2024.06.04
- 리사 수 AMD CEO "매년 신제품 투입...4분기 서버용 GPU MI325X 출시"2024.06.03
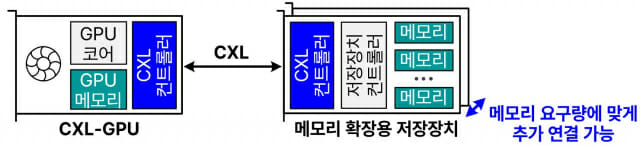
파네시아는 업계 최초로 CXL 메모리 관리 동작에 소요되는 왕복 지연시간을 두 자리 나노초(10의 9승분의 1초) 이하로 줄인 순수 국내기술의 자체 CXL 컨트롤러를 보유하고 있다.
이는 전세계 최신 CXL 컨트롤러 등 대비 3배 이상 빠른 속도다. 파네시아는 고속 CXL 컨트롤러를 활용해 여러 개의 메모리 확장 장치를 GPU에 바로 연결함으로써 단일 GPU가 테라바이트 수준의 대규모 메모리 공간을 형성할 수 있도록 했다.





