



KAIST가 거대언어모델(LLM)을 이용해 챗GPT4.0의 기업 의사결정 정답률을 32.5% 개선한 '플랜래그'(Plan RAG)를 처음 공개했다.
오픈AI의 최신모델인 챗GPT 4.0은 의사결정 구조에서 통상 40~50%의 정답률을 보인다. 이를 30% 이상 개선했다.
KAIST는 전산학부 김민수 교수 연구팀이 ▲의사결정 문제 ▲기업 데이터베이스 ▲비즈니스 규칙 집합 등 3 가지를 기반으로 비즈니스 규칙에 부합하는 최적의 의사결정을 내릴 수 있는 '플랜래그(PlanRAG)'을 개발했다고 19일 밝혔다.

김 교수는 엔비디아 GPU 연구센터장과 IBM 알마덴 연구센터 연구원을 지냈다. 지난 2021년부터 KAIST 전산학부 교수로 재직 중이다.
연구팀은 기업 의사결정 문제를 푸는데 있어 GPT-3.5 터보에서 반복적 RAG 기술을 사용하더라도 정답률이 10% 미만이라는데 착안해 대안을 모색했다.
최근 AI분야에서는 LLM이 학습된 내용만으로 답변하는 것 대신, 데이터베이스를 검색해 답변을 생성하는 검색 증강 생성(Retrieval-Augmented Generation; 이하 RAG) 기술이 각광받고 있다.
연구팀은 여기에서 한 단계 더 나아갔다. 반복적 RAG를 이용하기 전에 먼저 어떤 데이터 분석이 필요한지에 대한 거시적 차원의 계획을 먼저 생성했다.
마치 기업의 의사결정권자가 어떤 데이터 분석이 필요한지 먼저 계획을 세우면, 그 계획에 따라 데이터 분석팀이 데이터베이스 솔루션들을 이용해 분석하는 형태와 유사한 구조다.
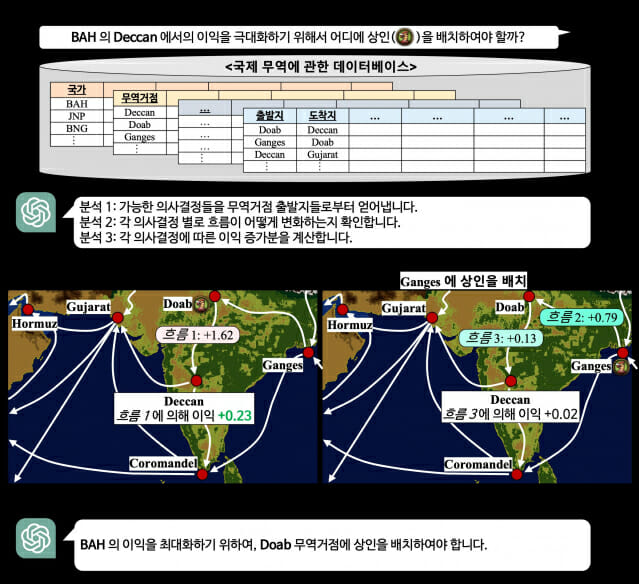
연구팀은 "다만 이러한 과정을 모두 사람이 아닌 거대언어모델이 수행하도록 한 것이커다란 차이"라며 "'플랜래그' 기술은 계획에 따른 데이터 분석 결과로 적절한 답변을 도출하지 못하면, 다시 계획을 수립하고 데이터 분석을 수행하는 과정을 반복한다"고 설명했다.
김민수 교수는 “지금까지 LLM 기반으로 의사결정 문제를 푼 연구가 없었다"며 "기업 의사결정 성능을 평가할 수 있는 의사결정 질의응답(DQA) 벤치마크를 새롭게 만들었다"고 말했다.
실제 이 벤치마크에서 GPT-4.0을 사용할 때 종래의 반복적 'RAG'의 의사결정 정답률에 비해 '플랜래그'는 최대 32.5%까지 정답률을 개선했다.
관련기사
- "애플, 챗GPT 공짜로 쓴다…오픈AI에 사용료 안 내"2024.06.14
- 티맥스 "챗GPT가 못하는 IT 통합, '가이아'는 할 수 있다"2024.06.13
- 챗GPT 품은 시리, 얼마나 똑똑해질까2024.06.11
- 엔비디아, 마침내 美 시총 1위…MS까지 제쳤다2024.06.19
김 교수는 "기업 CEO가 '플랜래그'를 실제 활용하기 까지는 1~2년이 더 걸릴 것으로 예상한다"며 "기존 챗GPT 4.0의 의사결정 정답률을 획기적으로 끌어올려 문제의 3분의 2가량을 맞출 수 있다는데 큰 의미를 부여한다"고 덧붙였다.
이 연구에는 KAIST 전산학부 이명화 박사과정과 안선호 석사과정이 공동 제1 저자, 김민수 교수가 교신 저자로 참여했다. 연구 결과는 자연어처리 분야 최고 학회(top conference)인 ‘NAACL’ 에 지난 17일 발표됐다.





