[타이베이(대만)=권봉석 기자] 인텔이 올 3분기부터 주요 PC 제조사에 공급할 모바일(노트북)용 프로세서, 루나레이크(Lunar Lake)는 플랫폼 컨트롤러 타일에 최대 48 TOPS(1초 당 1조 번) AI 연산이 가능한 4세대 NPU(신경망처리장치), NPU 4를 탑재한다.
NPU 4는 CPU나 GPU 대비 훨씬 적은 전력으로 CPU(5 TOPS)의 5배 이상, Xe2 GPU(67 TOPS)의 71% 수준 AI 처리를 수행한다. AI 연산 성능만 따지면 코어 울트라 시리즈1(메테오레이크)의 CPU, GPU, NPU를 모두 합친 수치(34 TOPS)를 넘어선다.

NPU 4는 PC가 켜져 있을 때 항상 같이 돌아가야 하는 음성 인식, 악성코드 탐지, 카메라를 이용한 사물 인식 등에 적합하다. 스테이블 디퓨전 1.5 기준으로 NPU 3 대비 최대 4배 빠르게 이미지를 생성해 전력 효율도 2.9배 향상됐다.
■ 인텔 NPU, 2018년 첫 출시 이후 올해 4세대 돌입
인텔 NPU는 2016년 인텔이 인수한 스타트업 '모비디우스' 기술력 기반으로 만들어졌다. 2018년 출시된 첫 제품은 별도 칩으로 출시돼 USB 단자 등을 통해 PC에 연결해 작동했다. 연산 성능은 0.5 TOPS로 영상 처리나 사물 인식 등에 적합했다.

2세대 제품인 'NPU 2'는 2021년 출시된 제품이며 IoT(사물인터넷) 기기를 대상으로 했다. 연산 속도는 7 TOPS 수준이며 배경 흐림, 프레임 인물 고정 등 윈도 스튜디오 효과를 지원했다.

지난 주 진행된 '테크투어 타이완' 행사에서 대런 크루스(Darren Crews) 인텔 NPU 수석 아키텍트는 "NPU는 7년 전만 해도 카메라를 통한 사물 인식 등에 주로 쓰였지만 현재는 높은 연산 성능과 함께 전력 효율성 등 두 가지 목표를 모두 달성해야 하는 상황"이라고 설명했다.
■ NPU 4 하나로 메테오레이크 연산 성능 능가
지난 해 출시된 코어 울트라 시리즈1(메테오레이크)는 SOC 타일에 3세대 제품 'NPU 3'를 통합했다. 연산 성능은 11.5 TOPS로 전체 연산 성능(34 TOPS)의 1/3 가량을 차지한다.
반면 후속 제품인 루나레이크에 탑재된 NPU 4의 AI 연산 성능은 최대 48 TOPS로 메테오레이크의 CPU, GPU, NPU를 모두 합친 것보다 더 빠르다.

대련 크루스 수석 아키텍트는 "AI 연산을 실제로 수행하는 엔진 수 증가, 작동 주파수 향상, 내부 아키텍처 개선으로 NPU 4의 성능이 급격히 향상됐다"고 설명했다.
■ "TOPS 수치, 작동 클록과 MAC 연산 능력이 좌우"
최근 PC용 프로세서를 구성하는 CPU와 GPU, NPU의 AI 연산 성능 측정을 위한 기준으로 'TOPS'가 널리 쓰인다. 그러나 이 수치가 정확히 어떤 과정을 거쳐 나오는지 정확히 아는 사람은 드물다.
대런 크루스 수석 아키텍트는 "TOPS는 AI 처리에 주로 쓰이는 연산 속도와 NPU 작동 클록에 크게 영향을 받는다" 고 설명했다.
AI 연산에 가장 널리 쓰이는 연산 방식은 큰 수치를 서로 곱해 더하는 행렬 연산인 MAC 연산이다. 메테오레이크의 NPU 3내 연산 엔진은 두 개이며 한 클록당 4천96개의 MAC 연산을 수행한다.

여기에 작동 클록(1.4GHz)을 곱하고 1조 번(10의 12승)으로 나눈 값이 11.5 TOPS다. 같은 방식으로 계산하면 루나레이크 내장 NPU 4의 TOPS는 48 TOPS다.
■ "TOPS는 행렬 연산에 치중... 벡터 계산 성능 향상도 중요"
단 MAC 연산 처리량은 자료형(데이터타입)의 정밀도에 큰 영향을 받는다. 예를 들어 인텔이 기준으로 삼은 자료형은 INT8(정수 8비트)이다. 이를 INT4(정수 4비트)로 바꾸면 MAC 연산량과 TOPS는 각각 두 배로 뛴다.

대런 크루스 수석 아키텍트는 "TOPS 값은 계산으로 얻어진 값이며 주로 행렬 연산에 집중됐다. 그러나 큰 수치를 한꺼번에 처리하는 벡터 연산이 실제 AI 응용프로그램 성능에 더 큰 영향을 미친다"고 설명했다.

NPU 4는 벡터 연산을 처리하는 레지스터 크기를 512비트로 확장하고, 대역폭은 전 세대 대비 4배 높였다. 행렬과 수치 연산을 모두 강화해 다양한 AI 연산을 처리할 수 있게 됐다. 양자화 전용 회로도 내장해 INT8, FP16 자료형을 모두 지원한다.
■ "TOPS, 행렬 연산에 치중...벡터 계산 성능 향상도 중요"
NPU 4는 뉴럴 연산 엔진을 2개에서 6개로 3배 늘렸다. MAC 연산을 담당하는 어레이도 4천 개에서 1만 2천개로 늘어났다. 같은 소비 전력에서 NPU 3 대비 성능은 두 배 늘어났고 최대 성능은 4배로 뛰어올랐다.
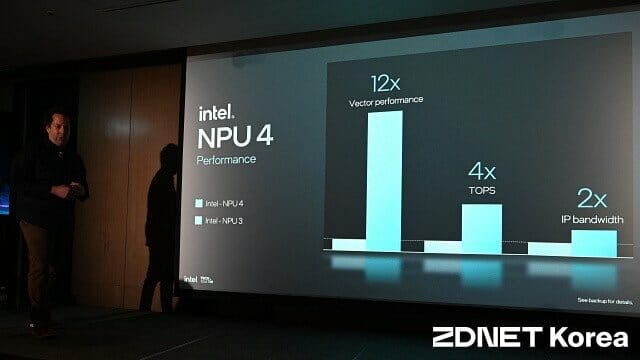
벡터 연산 성능은 최대 12배, TOPS는 4배 이상 향상됐다. LLM(거대언어모델)의 토큰 생성 속도에 영향을 미치는 대역폭도 최대 2배 향상됐다.
관련기사
- Arm, 3나노 공정 검증 마친 클라이언트용 'Arm CSS' 발표2024.05.30
- 인텔 "노트북용 CPU '루나레이크' 3분기 출시"2024.05.21
- 인텔 "루나레이크 AI 성능, 전작 대비 3배 높일 것"2024.04.10
- 인텔, 올 하반기 출시할 노트북용 '루나레이크' 시제품 공개2024.01.09
오픈소스 그래픽 프로그램 '김프'(GIMP)로 스테이블 디퓨전 1.5 플러그인을 이용해 이미지를 생성하는 테스트에서 메테오레이크는 22.08초, 루나레이크는 5.43초로 실제 처리 시간이 1/4 수준으로 줄었다.
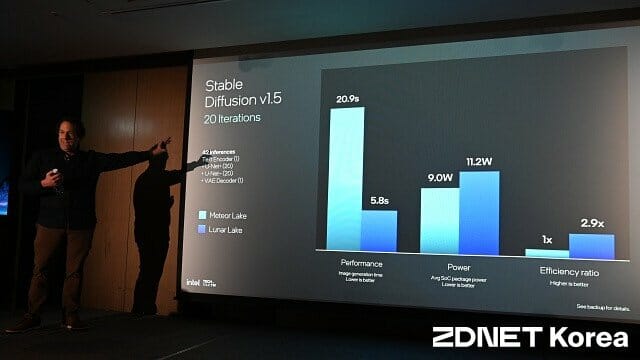
전력 소모는 NPU 3와 NPU 4 사이에 큰 차이가 없다. 메테오레이크 소모전력은 9W, 루나레이크 소모전력은 11.2W다. 대런 크루스 수석 아키텍트는 "소모 전력이 높아졌지만 소요 시간이 크게 줄어 실제 전력 소모는 줄어든다. 이를 통해 전력 효율을 2.9배 높였다"고 밝혔다.