






마이크로소프트가 사진 한장으로 실제 사람과 같은 표정을 구현할 수 있는 새로운 인공지능(AI) 모델을 공개했다.
21일 더레지스터 등 외신에 따르면 마이크로소프트는 시각적 감정 기술(VAS) AI모델 '바사-1(VASA-1)'을 공식 블로그를 통해 공개했다.
바사-1는 실제 사람의 얼굴을 볼 때 생동감을 느끼게 하는 다양한 얼굴의 미세한 변화와 자연스러운 머리 움직임을 생성하는 AI모델이다.
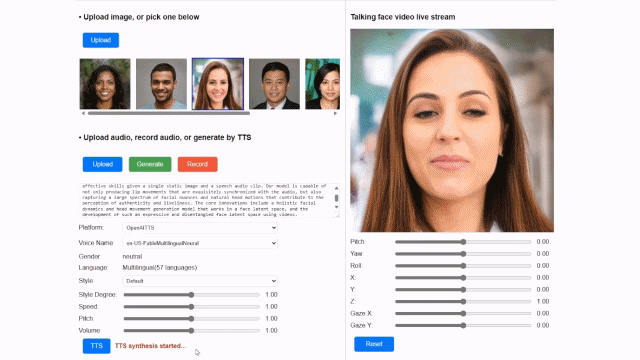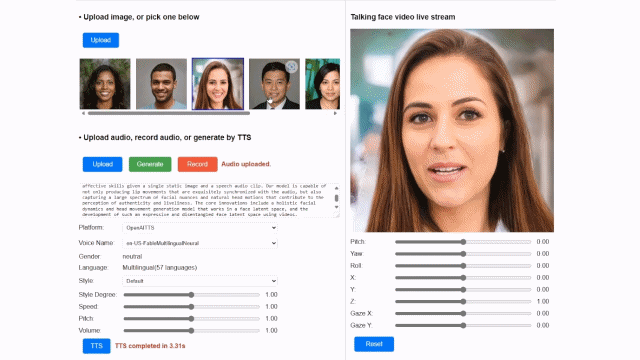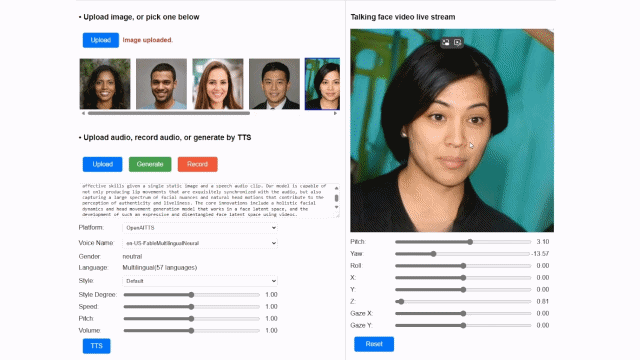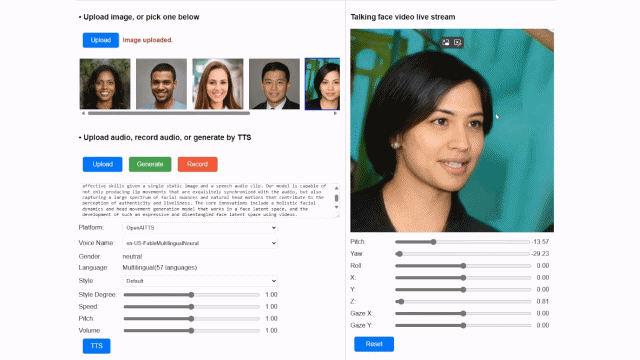
마이크로소프트는 자연스러운 표정의 변화를 구현하기 위해 얼굴과 머리카락의 움직임을 별도로 표현했다.
특히 이 모델은 한 장의 사진만으로도 다양한 표정, 입 모양, 눈동자 움직임을 정교하게 구현할 수 있는 것이 특징이다.
이는 얼굴 잠재 공간이라는 새로운 기술을 활용한 것이다. 눈 크기, 입 모양, 표정 등 얼굴의 다양한 특성을 숫자로 변환해 AI가 빠르게 학습할 수 있는 기술로 이를 활용해 실시간으로 다양한 표정이나 머리카락 표현을 구현했다.
또 음성파일과 연계해 실제 사람이 말하는 것처럼 자연스럽게 표정과 입모양을 자연스럽게 맞물리도록 생성하는 기술도 적용했다.
관련기사
- 국제 AI 보안 표준 발표..구글-오픈AI-알리바바 동참2024.04.18
- MS, 중동 AI 기업에 2조 투자…中 견제 나선 美 정부에 힘 실어2024.04.17
- 메가존클라우드, 디지털전환 역량 입증2024.04.17
- 마이크로소프트, 다이나믹스365 가격 10% 이상 인상 예고2024.04.16
마이크로소프트는 해당 기술을 테스트해본 결과 지연 없이 최대 40fps(초당 프레임 수) 로 512x512의 영상을 실시간으로 생성할 수 있었다고 밝혔다. 이를 활용한다면 가상 교육, 원격 회의, 엔터테인먼트 등 다양한 분야에서 실시간으로 가상 캐릭터를 활용할 수 있을 전망이다.
마이크로소프트 연구원들은 "이를 실제 인물과 혼동을 불러 일으키거나 해로운 콘텐츠를 생성하는 행위에 악용될 것을 반대한다"며 "이를 위해 생성된 이미지는 AI로 개발됐다는 것을 확인할 수 있는 요소를 추가할 것"이라고 밝혔다.





