






인텔은 19일 메타가 공개한 생성 AI LLM(거대언어모델) 라마3(Llama 3)를 제온 프로세서와 가우디 AI 가속기, 코어 울트라 탑재 AI PC 등에서 지원한다고 밝혔다.
메타가 공개한 라마3는 오픈소스 생성 AI 모델이며 데이터셋 중 비영어권 데이터 비중을 5%까지 높였다. 현재 매개변수 80억 개, 700억 개 버전이 선 공개됐다. 매개변수 4천억 개 버전은 현재 데이터셋 훈련중이다.

인텔은 가우디 AI 가속기, 제온/코어 울트라 프로세서와 아크 GPU로 메타가 선공개한 매개변수 80억/700억 개 버전의 구동을 검증했다고 밝혔다.
인텔은 파이토치(PyTorch), 딥스피드, 인텔 옵티멈 하바나 라이브러리, 인텔 파이토치 익스텐션 등 오픈소스 소프트웨어로 수행한 자체 벤치마크 결과도 공개했다.
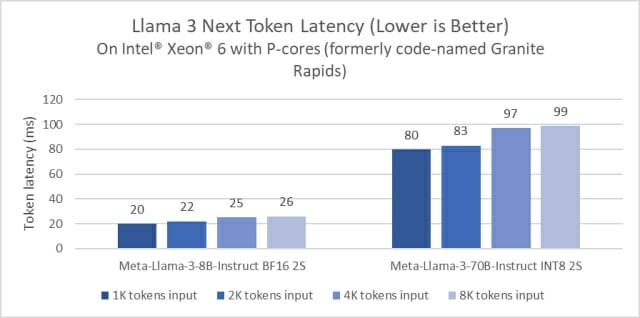
인텔이 2분기 중 출시할 P코어 제온6 프로세서는 80억 개 모델 추론 구동시 4세대 제온 스케일러블 프로세서 대비 지연 시간을 절반으로 단축했다. 또 700억 개 버전에서 토큰 하나당 지연시간을 0.1초 미만으로 줄였다.

코어 울트라 프로세서는 내장 아크 GPU를 이용해 라마3 구동시 사람이 읽을 수 있는 것보다 더 빠른 속도로 토큰을 생성했다. Xe 행렬곱셈 확장(XMX)을 내장한 아크 A770은 16GB 메모리를 활용해 라마3 처리를 가속한다.
관련기사
- 퀄컴 "메타 라마3 PC·스마트폰·차량서 구동 지원"2024.04.19
- 메타, '라마3' 전용 AI인프라 공개...GPU만 4만9천개2024.03.17
- 美 정부, 엔비디아 H200 중국 수출 공식화…"초기 인도물량 미미"2026.07.15
- 유진테크, 코쿠사이 반도체 ALD장비 특허 추가 무효화...특허법원서 뒤집어2026.07.15
가우디2 AI 가속기는 라마2 3개 모델(70억개, 130억개, 7천억개)에 이어 라마3 모델도 구동했다. 올 하반기 출시될 가우디3 AI 가속기도 라마3를 지원한다.
인텔은 향후 매개변수를 늘리고 성능을 강화한 라마3 모델도 지속 지원할 예정이다.





