챗GPT 등장 후 생성형 인공지능(AI) 기반 서비스가 모든 산업군에 변화를 만들고 있다. AI 기술은 모든 산업의 새로운 먹거리로 인식되는 상황이다. 대기업, 인터넷서비스기업, 클라우드 기업 등은 AI 시장을 선점하려 대대적인 물량 투자와 함께 기업 인프라를 개혁하고 있다.
오늘날 AI 기술은 챗GPT 이전과 이후로 나뉜다고 할 정도다. 챗GPT를 뒷받침하는 트랜스포머 아키텍처는 인간과 소통하듯 '자연스러운' 대규모언어모델(LLM)을 만들어냈다. 그리고 이 '자연스러움'을 더욱더 인간처럼 구현하려면 방대한 규모의 고성능 GPU 클러스터 인프라가 필수적이다.
AI 인프라의 근간인 GPU, 서버, 스토리지, 네트워크 등은 수많은 제품을 요구하는 고비용 서비스다. LLM의 경우 GPU 갯수를 늘릴수록 학습 시간을 획기적으로 늘릴 수 있는 구조다. 예를 들어 2년 전 나온 GPT-3.5의 경우 1만개의 GPU로 서비스된다. GPT-3.5를 GPU 한개로 학습시킨다면 약 355년이 필요하다.
AI 인프라 기술 그 자체는 전과 크게 달라지지 않았다. AI 인프라가 작은 연산 자원을 대규모로 한대 묶어 성능을 획기적으로 높이는 고성능컴퓨팅(HPC) 기술을 근간으로 한다. HPC 기술은 처음에 CPU를 중심으로 발전하다 21세기 들어 GPU 클러스터로 발전했다.
현재 LLM 학습과 추론을 위한 GPU 시장은 엔비디아 독주 체제다. 엔비디아 텐서코어 H100이나 A100 GPU는 칩셋 하나당 5천만원 내외의 단가로 거래되고, 그마저도 공급부족으로 품귀현상을 보인다. 주문한다고 해도 구하기 쉽지 않고, 가격도 고공행진중이다. 오픈AI의 GPT, 구글 제미나이, 메타 라마 등 유명 LLM의 발전과 출시는 GPU의 빅테크 쏠림과 공급부족 현상을 한층 부추기고, 일반 수요자를 더 안달나게 만든다. 이런 독점 체제를 깨기 위해 AMD, 인텔 등이 경쟁 제품을 속속 출시중이다.

■ AI 인프라에서 네트워킹이 왜 중요한가
AI 인프라의 핵심인 GPU의 성능을 높이려면 여러 GPU를 연결하는 네트워킹 기술이 필요하다. 여기서 GPU 연결에 노드 내부와 노드 외부 등 두 종류의 네트워킹이 요구된다.
엔비디아의 경우 표준 아키텍처에 의하면, DGX 같은 전용 서버 한 대에 GPU를 8개씩 장착할 수 있다. 8개의 GPU는 노드 내 연결은 엔비디아의 NV링크란 독점 기술을 쓴다. 그리고 GPU 서버를 여러대 연결하는 노드 외 연결은 고대역폭 인피니밴드나 이더넷 스위치를 이용한다.
엔비디아는 H100 GPU의 노드 연결에 400Gbps의 고대역폭 네트워킹을 기본 사양으로 권고한다. 엔비디아는 고사양 GPU 신제품을 내놓을 때마다 대폭의 네트워킹 사양 업그레이드를 요구해왔다. V100 GPU에서 A100으로 넘어가면서 네트워킹 사양을 100Gbps에서 200Gbps로 올렸다. 성능 요구치는 초당 300GB에서 600GB로 올렸다. H100의 성능 요구치는 초당 900GB에 이른다.
만약 네트워킹 사양을 부족하게 구성하면 아무리 많은 GPU를 구비한다 해도 LLM 학습이나 추론 성능이 떨어질 수밖에 없다. 빠른 AI 서비스를 출시하려면 고비용의 대규모 AI 인프라 도입에서 특히 각 연산 요소 간 통신에 필요한 네트워킹이 필수적인 것이다.
고성능 AI 인프라 수용을 위한 네트워킹은 전통적인 워크로드 수용을 위한 인프라보다 거대할 수밖에 없는 구조다.
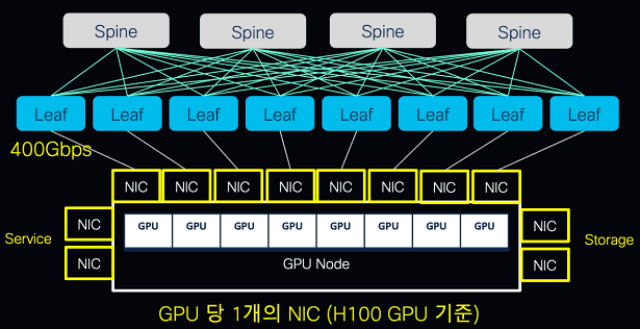
노드 내 GPU 간 연산 능력은 4개의 GPU를 내부 버스를 통해 P2P로 연결하는 NV링크 또는 서버 내 8개의 GPU를 연결하기 위해 NV스위치를 통해 극대화 가능하다.
여러 GPU 노드를 클러스트링하고 각 GPU 노드들의 통신 간 병목현상을 최소화하려면 GPU 당 한개의 고성능의 네트워크인터페이스카드(NIC)를 할당하게 된다.
각 NIC는 400Gbps 대역폭을 수용할 수 있어야 한다. GPU 한개에 1대의 400Gbps급 스위치를 연결하게 된다. 400Gbps가 제공되는 고사양의 스위치를 근간으로 2티어에서 3티어 구조의 '리프스파인(Leaf-spine)' 아키텍처를 구성하므로 대형 GPU 노드 클러스터의 경우 최소 수십대의 400Gbps급 스위치가 기본 제공돼야 한다.
엔비디아의 멀티 GPU 클러스터 상품인 '슈퍼팟(SuperPOD)'의 경우 32대의 DGX H100 노드를 최대 256개의 GPU 클러스터링으로 연결하며, 이론적으로 최대 57.8 TBps의 데이터 연산 성능을 제공하게 돼 있다.
따라서 기존 네트워크 물량 대비 최소 3~4배의 네트워킹 물량이 필요해진다. LLM의 경우 손실없는 완벽한 논블로킹 네트워킹 구조를 요구하므로, 네트워킹 장비와 케이블 수가 문자그대로 '기하급수'로 증가한다.
■ 왜 인피니밴드보다 이더넷인가
AI 인프라는 다수의 GPU 간 병렬 연산을 빠르게 수행하기 위해 다양한 부하분산 기술을 필요로 한다. RDMA, GPU 간 P2P, GPU 다이렉트스토리지 등이 활용된다. 이중 대표적인 오프로딩(Off-Loading)기술인 RDMA(Remote Direct Memory Access)는 워크로드 내 존재하는 다수의 프로토콜 계층을 건너뛰는 제로카피 기술 'DMA(Direct Memory Access)'를 네트워킹까지 확장한 것이다. RDMA는 서버 간 혹은 서버와 스토리지 간 간섭없는 메모리 접근을 제공해 GPU 간 병렬 연산 능력을 극대화한다. 인피니밴드나 RDMA오버컨버지드이더넷(RoCE)를 통해 활용가능하다.
수백개 GPU가 병렬처리를 통해 수백, 수천 시간을 학습하고 빠르게 서비스를 제공하려면 네트워크의 안정성도 중요하다. 잠깐의 방해도 재연산을 하게 만들 수 있다.
과거 네트워킹 기술의 성능과 안정성 면에서 인피니밴드가 이더넷보다 앞선 것으로 여겨져왔다. 인피니밴드가 이더넷의 대역폭을 월등히 앞섰기 때문에 HPC 분야에서 주료 인피니밴드를 활용했었다. 엔비디아 DGX 서버도 이더넷보다 인피니밴드를 장려한다. 안정성의 측면에서 인피니밴드는 패킷 무손실을 전제하지만, 이더넷은 어느정도의 패킷손실을 전제로 한다.
LLM 인프라가 HPC 기술을 바탕에 두기 때문에 GPU 클러스터의 네트워킹은 인피니밴드를 주로 쓴다.
만약 앞서 계산했듯 기존 비즈니스 워크로드 대비 3~4배 많은 네트워킹 인프라 물량을 인피니밴드로 구성하면 비용 부담이 적지 않다.
특히 인피니밴드 기술은 제조사 간 경쟁이 사라진 독점 기술이다. 과거 인피니밴드 솔루션을 개발하고 공급해오던 기업들이 하나둘 대형 업체에 흡수되거나 사라졌는데, 마지막 독립 업체로 남아 있던 멜라녹스도 엔비디아에 인수됐다. 지금은 엔비디아가 인피니밴드 기술을 독점 공급하는 상황이다. 공개 표준 기술이 아니므로 인피니밴드 핵심 기술은 비공개다. 발전 방향이나 정도가 엔비디아 결정에 100% 달려있다. 비용 구조도 엔비디아 종속적이다. 심지어 인피니밴드 스위치 공급 부족 현상이 GPU 공급부족보다 더 심각하다는 말까지 나온다.
비용, 기술 모두 특정업체 종속적인 상황에서 인피니밴드는 외부의 여러 워크로드를 LLM에 연동하기 힘들게 하는 장애물이 된다. 인피니밴드를 다룰 줄 아는 전문가는 매우 희귀하며, 기술적 어려운 정도도 매우 높다.
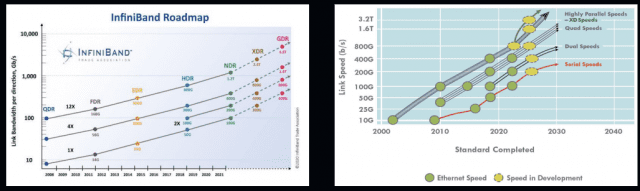
AI 인프라에서 인피니밴드가 당연시 된 건 이더넷 기술에 대한 오해 때문이기도 하다. 얼마전까지 인피니밴드는 속도 면에서 이더넷을 앞섰으며, 400Gbps란 대역폭은 인피니밴드의 전유물처럼 여겨졌었다.
하지만, GPU 제조사인 엔비디아도 네트워킹 영역의 무게중심을 인피니밴드에서 이더넷으로 이동하고 있을 정도다. 대부분의 기존 AI 네트워크 인프라는 인피니밴드라는 프로토콜과 특정 업체가 시장을 독점했지만, 이젠 표준 기반 기술을 통해 비용 이슈 제거 및 편리한 운영 관리가 가능한 표준 기반의 RDMA 방식인 RoCE가 인피니밴드 기술을 대체할 것으로 기대된다.
근래 들어 이더넷 진영은 400G, 800G 제품을 선보이면서 인피니밴드와 동등한 성능을 제공하게 됐다. 지금은 인피니밴드나 이더넷이나 현존하는 NIC과 스위치 포트에서 낼 수 있는 최대한의 대역폭이 400Gbps로 똑같다.
이젠 인피니밴드와 이더넷 모두에서 어느정도 동급 성능을 기대할 수 있을 정도로 이더넷 기술의 진화는 뚜렷해졌고 엔비디아의 GPU 성능 테스트 도구인 NCCL을 이용해 인피니밴드와 RoCE를 비교 테스트 결과를 보더라도 대역폭과 지연시간이 동등하거나 약간의 차이만 보일정도로 AI 인프라 영역에서의 이더넷 기술의 상당한 신뢰성을 제공할 수 있는 프로토콜로 발전하고 있다.
RoCEv2(버전2)는 인피니밴드의 헤더와 RDMA 기술을 그대로 탑재했으며, TCP 제거, UDP 활용 등을 통해 이더넷 스위치의 지연시간을 개선하고 있다. 안정성 면에서도 PFC, ECN 등 이더넷의 표준 기술로 패킷 손실을 최대한 상쇄할 수 있다.
무엇보다 이더넷은 표준 기술이고 치열한 경쟁을 보이는 시장이기 때문에 개방적이면서 누구나 쉽게 구축 및 운영할 수 있다. 이미 이더넷으로 구축된 외부 서비스와 연동도 더 쉽다. 운영 인력의 저변도 매우 넓다.
기술 로드맵상으로도 인피니밴드와 이더넷은 800Gbp란 같은 방향을 가리키고 있는데, 오히려 이더넷의 대역폭 증가가 인비니밴드를 앞선 상황이다. 인피니밴드의 800G 이후 계획은 시점을 확정하지 않은 반면, 이더넷의 800G는 이미 상용화됐다. 2025년이면 1.6Tbps 기반 패브릭 기술 제품도 출시될 것으로 예상된다.
관련기사
- 생성 AI의 엔비디아 GPU 탈출은 가능할까2023.08.17
- '생성 AI 열풍' GPU 품귀에 국가 슈퍼컴 유탄 맞아2023.08.18
- "생성 AI에 맞는 스토리지 써야 GPU 활용률 높아진다”2023.09.12
- "시스코, 'HW+SW' 혁신 지원 강자"2023.06.27
이같은 흐름속에 시스코는 LLM 인프라용 제품으로 넥서스 시리즈 스위치를 제공하고 있다. 네트워킹 프로비저닝과 모니터링에 쓰이는 오케스트레이션 툴 '넥서스 대시보드'는 대규모 AI 인프라의 빠른 구축과 관리를 위해 턴키 기반 자동화와 로스리스 안정성을 보장하는 가시성을 제공한다. 또한 지연시간에 민감한 AI 트래픽의 가시성을 제공하는 분석 도구와 솔루션도 이용가능하다. 시스코는 특히 전용 SoC 칩으로 넥서스 스위치를 구동해 인피니밴드 장비보다 더 적은 전력으로 고성능 AI 인프라를 구동할 수 있다고 강조한다.
AI 인프라에서 서서히 독점의 시대가 저물고 있다. 개방형 표준 제품과 기술이 갈수록 높아지는 AI 인프라 투자 및 운영 비용을 절감하고 기업 경쟁력을 높이는 열쇠가 될 것이다.