






오픈AI 챗GPT로 촉발된 생성 AI 열풍은 전 분야에 휘몰아쳤다. 사업 분야와 규모에 상관없이 생성 AI 기반 서비스를 개발하고 출시하려는 곳은 셀 수도 없을 정도다. 그러나 생성 AI를 개발하는 모든 기업과 조직에서 안고 있는 큰 리스크가 있다. 막대한 엔비디아 GPU 비용이다.
지난 10여년 사이 AI 인프라는 엔비디아 GPU 천하로 정리됐다. 오픈AI를 비롯해 마이크로소프트, 구글, 아마존, 메타 등 빅테크뿐 아니라 모든 AI 관련 기업은 엔비디아 GPU를 사용해 AI를 개발, 서비스하고 있다.
AI 인프라는 크게 두 갈래로 나뉜다. AI 모델을 만드는 ‘학습’ 인프라와, 개발한 AI 모델을 실제로 운영하는 ‘추론’ 인프라다. 학습 인프라에서 AI를 교육시켜, 추론 인프라에 옮겨 구동한다.
엔비디아 GPU가 생성 AI 개발의 필수재로 여겨지는 건 성능 때문이다. 현재 엔비디아의 최고사양 GPU인 H100 텐서코어 GPU를 탑재한 서버는 한대당 수억원에 판매된다. H100의 절반 정도 가격에 구매할 수 있는 A100 텐서코어 GPU도 H100만큼은 아니지만 서버 한대당 수억원대에 팔린다. 높은 가격에도 불구하고 구할 수 없어서 배달까지 최대 12개월 걸릴 정도로 인기다. 대규모로 H100과 A100 인프라를 구축한 마이크로소프트나 구글, 아마존 같은 기업이 수천대 규모의 GPU 서버팜을 운용한다.

■ 생성 AI 학습 및 추론 인프라 엔비디아 종속에 비용 폭증
GPT-4는 1만~2만5천개의 A100으로 훈련된 것으로 추정된다. 메타가 약 2만1천개의 A100을 보유했고, 테슬라는 7천여개의 A100을 보유했다. 스태빌리티AI는 5천여개의 A100을 보유한 것으로 알려졌다.
빅테크 기업도 GPU 부족을 호소한다. 테슬라의 생성 AI 인프라를 구축하려는 일론 머스크는 "GPU를 마약보다 구하기 어렵다"는 말로 GPU 수급 불균형에 불만을 터뜨렸다. 오픈AI의 샘 알트만 CEO는 "GPU가 충분치 않아 사람들이 우리 제품을 덜 사용할수록 좋아한다"고 말했다. 마이크로소프트를 비롯한 클라우드 기업은 수천개로도 부족해서 H100과 A100의 접근 우선순위를 파트너인 오픈AI로 두고, 내부 직원의 활용을 제한할 정도다.
GPT-4나 구글 팜(PaLM)2, 메타 람다2 70B, 팔콘 40B 규모의 대규모언어모델(LLM)을 학습하고 추론하는데 얼마나 많은 GPU가 필요한지는 불확실하다. A10G 같은 구형 GPU로도 AI 모델을 학습시킬 수는 있지만, 고사양일수록 짧은 기간에 AI의 학습을 마치고, 더 빠르게 추론할 수 있다. 치열한 경쟁에서 승리하려면 고가의 GPU를 확보해야 유리하다. 빅테크의 LLM에 1천개 이상은 필요하다고 하며, 스타트업조차 100개 이상은 필요하다고 한다.
2020년 한 연구에 의하면 매개변수 15억개 규모의 텍스트 생성 AI 모델을 개발하는 비용은 160만달러 수준이다. PaLM의 매개변수 규모는 5천400억개다. 오픈AI GPT-4의 매개변수 규모는 1천750억개 내외로 추정된다.
H100 GPU 8개를 장착한 공식 서버인 엔비디아 DGX H100 가격은 한대 당 46만달러(약 6억1천600만원)다. 서버 업체가 H100 8개를 장착해 공급하는 OEM 서버인 HGX H100의 가격은 30만에서 38만달러(4억원~5억1천만원)에 구매가능하다. OEM 서버 가격은 메모리, CPU, SSD, 기술지원료 등의 요건에 따라 달라진다.
일론 머스크는 GPT-5를 H100으로 훈련하려면 3만~5만개가 필요하다고 추정했다. 구글클라우드가 H100 2만5천개를 애저가 1만~4만개 수준의 H100을 보유한 것으로 추정되고 있다. 오픈AI가 새 GPT 모델을 학습시키는데만 DGX H100 서버 5천대 이상 필요하다고 하니, 그 구매비용만 2천500억원이다.
GPU 구매로 비용지출이 끝나지 않는다. 전력, 냉각 등의 설비 비용과 모델을 개발하는 전문 인력 고용유지 비용은 산정조차 힘들다. 오픈AI는 챗GPT 플러스 유료 구독으로 매출을 대거 일으키고 있지만, 챗GPT 운영 비용이 하루에 70만달러 수준으로 추산된다. 오픈AI는 작년 5억4천만달러의 영업손실을 기록한 것으로 알려져있다.
가격도 가격이지만 GPU 공급 부족은 해결 기미도 없다. 엔비디아 GPU를 생산하는 TSMC의 생산 능력에 따라 공급량이 결정되고 있는데, 올해와 내년 사이 현재의 수요를 충족할 수준의 생산량을 확보할 수 있을지 미지수다.

이같은 GPU 수요의 폭발적 증가는 생성 AI의 등장과 함께 일어났다. 기존의 머신러닝, 딥러닝 모델은 주로 모델 학습에 GPU를 필요로 했다. 추론의 경우 학습보다 적은 수의 GPU만으로도 만족스러운 성능을 낼 수 있었다. 하지만, LLM은 학습 인프라와 거의 동일한 수준의 추론 인프라 규모를 필요로 한다. 연산량이 학습이나 추론이나 크게 차이나지 않기 때문이다. 과거 학습과 추론의 GPU 할당비율을 9대1로 맞췄던 기업과 조직은 5대5의 비율로 할당해야 한다. 학습에 H100을 투입하고, 추론에 A100을 투입하는 기업이 많은데, 점차 추론에도 H100을 투입하는게 가성비에서 좋다는 의견이 대세를 이루고 있다. 결국 추론 인프라를 위해 대대적인 GPU 구매가 필요하단 얘기다.
생성 AI 개발과 서비스운영에서 엔비디아 GPU의 대체재를 활용하는 건 어떨까. 현재 AI 전용 칩 개발에 많은 기업이 투자하고 있다. 구글의 TPU, 아마존웹서비스(AWS)의 ‘트레이니엄’ 및 ‘인퍼런시아2’, 마이크로소프트의 ‘아테나’ 등을 비롯해 우리나라에도 퓨리오사AI, 리벨리온, 사피온 같은 기업이 NPU란 이름의 AI 전용칩을 개발중이다. 인텔, AMD 등도 GPU나 가속기를 계속 선보이고 있다.
일찌감치 엔비디아 GPU를 대체하는 AI 전용칩을 개발하고, 실제 서비스까지 제공중인 AWS는 엔비디아의 견제를 받고 있다. 엔비디아는 퍼블릭 클라우드 업체에 대한 H100 공급을 내부 정책에 따라 조절하고 있는데, AWS 우선순위를 타사보다 후순위로 두고 있다는 후문이다. 이 때문에 주요 퍼블릭 클라우드 서비스 중 AWS가 가장 적은 수의 엔비디아 H100을 보유한 것으로 추정된다. 후발주자인 오라클이 가장 많은 엔비디아 H100을 보유했다는 분석도 있다.
■ 학습 인프라 독점의 비결은 쿠다 DNN 라이브러리
하드웨어만 보면 엔비디아 GPU 대체재가 없지 않지만, 그 내면을 보면 하드웨어를 교체하기 쉽지 않은 상황이다. 그 비결은 엔비디아 GPU를 기반으로 하는 쿠다(CUDA) 소프트웨어 생태계다. 오늘날 널리 쓰이는 AI 개발 프레임워크와 각종 라이브러리, 도구 등은 엔비디아 GPU에 최적화돼 있다. 엔비디아 GPU를 벗어나선 생성 AI를 개발하는게 불가능한 실정이다.
‘쿠다’는 엔비디아에서 개발한 GPU용 병렬 프로그래밍 언어다. 쿠다 언어 자체는 기계어에 가까워서 일반적인 AI 모델 개발자가 다루기 까다롭다. 머신러닝, 딥러닝, 트랜스포머 등의 모델을 밑바닥부터 한땀한땀 개발하는 최고 수준의 개발자가 아니라면 쿠다 언어로 AI를 개발하지 않는다. 애초에 고성능컴퓨팅(HPC) 분야 개발자들은 수치 정확도 부족을 이유로 쿠다를 선호하지 않았다.
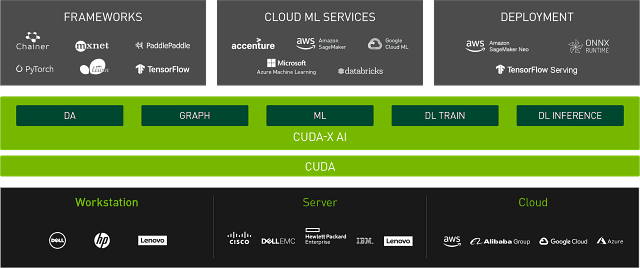
쿠다가 AI 세계에서 주도권을 쥐게 된 건 딥러닝 모델을 구동할 수 있는 DNN 라이브러리 덕분이었다. 쿠다를 활용한 ‘cuDNN’ 라이브러리가 딥러닝 모델을 가장 빠르게 돌린다는 지위를 얻게 되면서, 거의 모든 AI 개발자가 이 라이브러리 위에 AI 모델을 쌓아올렸다.
구글은 AI 개발 프레임워크인 ‘텐서플로우’ 첫 버전을 GPU 지원을 제외한 상태로 공개했다가 나중에 cuDNN 라이브러리를 채택해 GPU 가속을 활용할 수 있게 했다. 메타에서 내놓은 또 다른 AI 개발 프레임워크 ‘파이토치’도 cuDNN 라이브러리를 채택해 파이썬에서 GPU 기반 연산을 활용하게 했다. 주요 프레임워크가 cuDNN 라이브러리를 포함하면서, 개발자는 자신에게 익숙한 개발언어로 AI 모델을 만들 수 있게 됐다. DNN 라이브러리가 쿠다로 만들어졌고, 쿠다는 엔비디아 GPU만 사용할 수 있으니 자연스레 엔비디아가 기본 하드웨어로 자리잡았다.
대세 프레임워크 개발사조차 직접 DNN 라이브러리를 만들지 않고 엔비디아 쿠다를 채택하면서 엔비디아 GPU 의존성이 생겼다. 엔비디아가 DNN 라이브러리를 비롯한 여러 쿠다 기반 소프트웨어 생태계에 막대한 자본을 계속 투입하면서 의존성은 더 커졌다.
AMD가 ROCm을, 인텔이 원API를 내놓으며 쿠다 기반 GPU 소프트웨어 스택을 대체하겠다고 나섰다. 하지만, 엔비디아가 쌓아온 시간과 노력을 후발주자가 단기간에 따라잡기 쉽지 않다. AMD는 신뢰를 잃었다. ROCm 새버전을 내놓으면서 하드웨어 하위호환성을 보장하지 않아 고객 투자를 보호하지 않는다는 이미지를 구축해버렸다.
인텔의 원API는 GPU 외에 CPU, FPGA 등도 이용할 수 있다고 하지만 엔비디아만큼 사용자층을 확보하지 못한 상황이다. 인텔 원API를 사용하려면 텐서플로우, 파이토치 같은 프레임워크를 인텔 전용 버전으로 바꿔야 한다.
AI 모델 학습용 인프라에서 엔비디아 GPU 대체는 사실상 불가능한 상황이다. 엔비디아 수준의 학습 성능을 낼 수 있는 하드웨어와 소프트웨어가 없고, 도전자도 없다. 인텔과 AMD도 학습 인프라 영역에서 엔비디아를 단기간에 따라잡는 건 불가능하다고 본다.
그나마 인텔은 하드웨어와 소프트웨어 전반에 걸쳐 추론 인프라에서 가능성을 보여주고 있다. 나승주 인텔코리아 상무는 “인텔은 대규모 GPU를 동원해야 하는 파운데이션 모델 개발 외에 개별기업의 미세조정 수요를 보고 있다”며 “소규모로 구동되는 AI 모델을 개발한다면 굳이 엔비디아 GPU를 쓰지 않고, 자사의 하드웨어만으로도 충분하다”고 말했다.
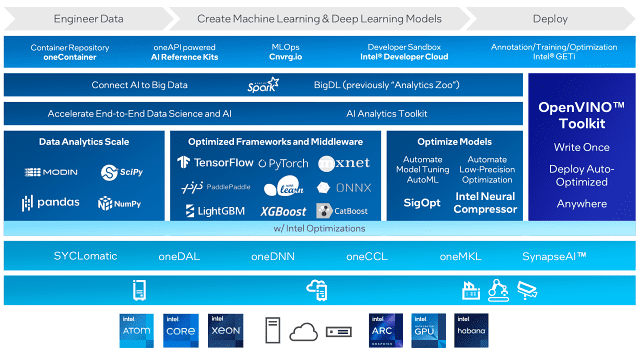
원API는 CPU인 제온 스케일러블 프로세서 4세대(사파이어래피즈 HBM), 가우디, CPU 맥스 등을 지원한다. 퍼포먼스 라이브러리, 대중적 프레임워크 및 툴, 플랫폼과 키트 등 3계층으로 구성된다. 라이브러리 계층에서 SYCLomatic, oneDAL, oneDNN, oneCCL, oneMKL, SynapseAI 등을 포함한다. SYCLomatic은 쿠다 기반을 C++이나 CYCL 기반으로 변환해주는 툴이다. 인텔은 90~95% 수준을 전환할 수 있다고 한다. 그밖에 DNN, MKL, DAL 등에서 엔비디아에 필적하는 수준이라고 강조한다.
프레임워크 및 툴 계층은 데이터 분석의 MODIN, 판다스, SciPy, NumPy 등을 제공하고, 프레임워크와 미들웨어로 텐서플로우, 파이토치, MXNET, 패들패들, ONNX, XGBoost, CatBoost, LightGBM 등의 최적화 버전을 제공한다. 최적화 모델로 오토ML, 인텔뉴럴컴프레서, 오토메이트모델튜닝, 시그옵트 등을 제공한다. 그 위에 빅DL. 스파크 등의 플랫폼과 키트를 넣었다.
■ 아직 틈새 있는 추론 인프라, 도전자는
확실히 추론 인프라는 엔비디아 GPU 대체의 여지가 남아 있다. 인텔 하바나랩스의 ‘가우디’는 AI 벤치마크 테스트인 Mlperf에서 엔비디아 A100을 앞선 성능을 보였다. CU DNN을 원API로 교체했을 때 성능 저하를 걱정하지 않아도 된다는 것이다.
추론 인프라의 DNN 라이브러리는 학습 인프라의 것보다 단순하다. 개인도 노력여하에 따라 만들 수 있는 정도다. 맨땅에 헤딩하는 강도가 학습보다는 약하다. 시도할 가치는 있는 것이다.
문제는 호환성이다. 현존하는 AI 라이브러리는 엔비디아 GPU의 구조에 최적화돼 있다. 엔비디아 GPU는 16비트 연산을 활용해 속도를 높이는 대신 정확도를 희생한다.
AI 개발 플랫폼 ‘백엔드닷AI’를 개발하는 래블업의 신정규 최고경영자(CEO)는 “엔비디아의 쿠다코어와 텐서코어를 잘 활용해 학습하고 완성된 모델이 타사 하드웨어 기반의 추론 인프라로 이식됐을 때 성능과 결과값이 일정하지 않다”며 “우연히 성능이 잘 나올 수도 있지만 일정 수준의 성능과 결과를 내야 하는 소프트웨어에서 ‘우연’은 의미가 없다”고 설명했다.
하드웨어 제조사마다 칩에서 지원하는 기능이 동일할 수 없으므로 엔비디아 쿠다 소프트웨어의 것을 100% 호환되게 하는 건 거의 불가능하다. 학습 단계부터 추론 인프라를 고려해 AI 모델을 설계하는 수밖에 없다. 이런 접근을 할 수 있는 조직은 전세계에 손꼽힌다.
오픈AI는 파이토치 프레임워크와 트라이톤이란 개발언어를 사용해 GPT 모델을 개발한다. 트라이톤은 기계어보다 더 추상화된 언어다. 모델 훈련 단계부터 DNN 라이브러리나 드라이버, 컴파일러 등을 쿠다 대신 자체적인 소프트웨어 스택으로 쓰는 것이다. 메타도 추론에서 엔비디아 GPU에 종속되지 않는 방안에 투자중이다. 구글은 GPU와 여러 가속기를 활용할 수 있는 컴파일러로 ‘XLA’를 만들어 하드웨어 종속 탈피를 추구했다. 마이크로소프트는 다양한 하드웨어에서 표준으로 사용할 수 있는 ‘ONNX’란 AI 모델용 포맷과 그 런타임을 만들었다. 마이크로소프트, 아마존 등도 자체적인 AI 스택을 보유했거나 구축중인 것으로 추정된다.
하지만, 이런 빅테크 기업에서 내부의 추론용 AI 소프트웨어 스택을 외부에 공개할 가능성이 점차 희박해지고 있다. 구글은 오픈AI와 경쟁을 위해 기술 자산 공유를 꺼리고 있으며, 퍼블릭 클라우드 기업이 AI 소프트웨어 스택을 공개할 것으로 기대하기 힘들다. AWS, 애저, GCP 등의 추론용 인스턴스 판매를 포기하고 엔비디아 GPU 공급업자로 스스로를 격하시키는 결정이기 때문이다.
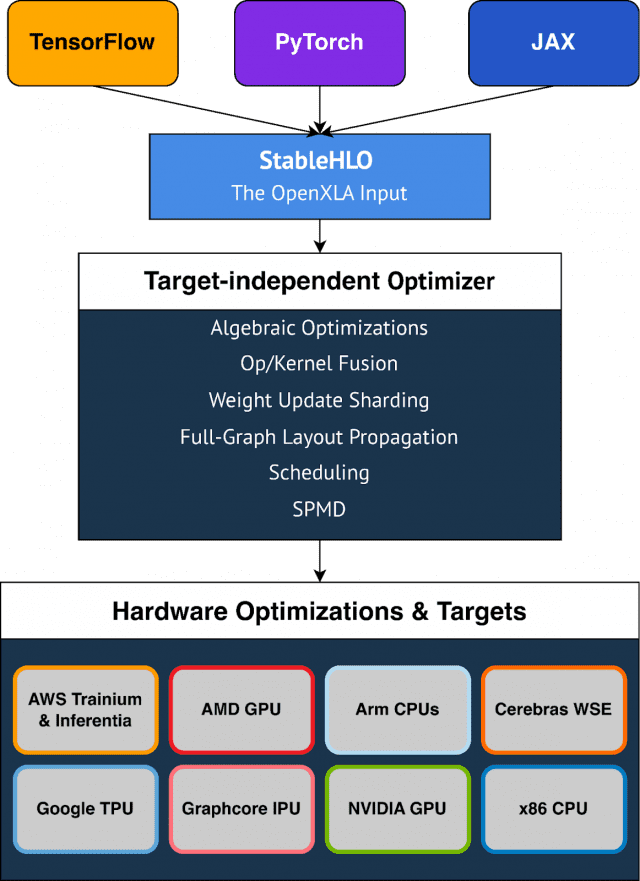
첨예한 경쟁 관계 속에서 동맹이 유연하게 결성될지도 미지수다. 구글은 XLA를 오픈소스로 풀고 메타나 마이크로소프트 등에 AI용 컴파일러 채택을 요구했지만, 메타와 마이크로소프트의 반응은 미온적이다.
NPU 칩 개발사들은 하드웨어 설계와 함께 소프트웨어 스택 개발에도 나선 상태다. 그러나 현재까지 쿠다 생태계와 완벽하게 호환된다고 자신하는 기업은 나타나지 않고 있다. 아예 GPU 종속을 없앤 AI 소프트웨어 스택만 개발하겠다고 나선 기업도 있다. 모듈러, 모레 등이 도전장을 던졌다. 구체적 성과가 언제쯤 나올지는 확실치 않다.
관련기사
- 마이크로소프트는 오픈AI의 슈퍼컴을 어떻게 구축했나2023.03.15
- 챗GPT와 유사한 오픈소스 모델 공개됐지만…2023.01.03
- 파이토치 2.0, 정식출시...AI 열풍 가속화 기대2023.03.17
- 구글, '오픈XLA' 공유…AI 생태계 표준 컴파일러 되나2023.03.14
희망은 여전히 있다. 쿠다 스택의 덩치 탓에 엔비디아도 추론 인프라에서 쿠다를 대신하는 소프트웨어를 계획중이다. 시장의 투자가 AI 추론 칩 분야로 대거 흘러들어가면서 개발사의 노력이 힘을 얻고 있기도 하다.
대중적인 개발 프레임워크도 가속 하드웨어 지원에 여유가 있다. 텐서플로우, 파이토치는 플러그인이나 모듈 교체로 가속기를 바꿀 수 있다. 구글이나 메타가 텐서플로우와 파이토치에 엔비디아 GPU와 호환 가능한 추론용 소프트웨어 스택을 병합해 선보인다면 현 상황이 한결 빠르게 해소될 수 있다. 구글은 JAX란 라이브러리에 투자해 하드웨어 의존성 없는 상태의 XLA 가속 성능을 높이고 있다.





