구글의 차세대 언어모델 '제미나이'가 오픈AI의 GPT-4보다 더 높은 벤치마크 테스트 성적을 받았다는 발표에 마이크로소프트가 반격을 가했다. GPT-4에 고도의 프롬프트 엔지니어링을 거쳐 제미나이 성능을 뛰어넘는 성적을 받았다는 것이다.
지난 12일 마이크로소프트의 연구진은 'Steering at the Frontier: Extending the Power of Prompting'이란 블로그 글에서 "수정된 버전의 메드프롬프트로 GPT-4를 조정해 완전한 MMLU 벤치마크에서 최고점수를 달성했다"고 밝혔다.
메드프롬프트는 올해 마이크로소프트 연구진이 고안해낸 프롬프트 방법으로 의학 분야에 특화돼 프롬프트 전략이다. 이달초 에릭 호비츠 마이크로소프트 최고과학책임자를 비롯한 연구원들이 메드프롬프트 방식으로 오픈AI의 GPT-4를 활용해 의학 분야 벤치마크테스트에서 구글의 의료특화 미세조정 모델인 MedPaLM2를 능가했다는 결과를 발표하며 주목받았다. 메드프롬프트는 kNN 기반의 소수 예시 선택, GPT-4에서 생성된 사고 프롬프트 체인, 다수결 선택 앙상블 등을 결합한다.
당시 연구원들은 파운데이션모델을 특정 목적을 위해 미세조정하지 않고 고도의 프롬프트 전략을 활용하는 것만으로도 다양한 분야에서 특출난 성과를 낼 수 있다고 강조했었다.
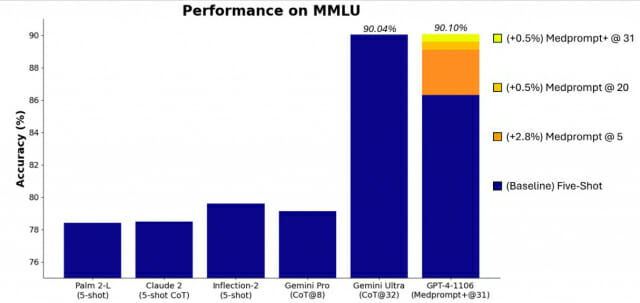
이달초 구글은 제미나이 울트라를 공개하면서 MMLU(Measuring Massive Multitask Language Understanding) 테스트에서 90.04%를 받아 GPT-4뿐 아니라 인간 전문가의 점수도 뛰어넘었다고 발표했다. MMLU는 대규모언어모델의 일반지식과 추론능력을 테스트할 목적으로 만들어진 벤치마크다. 기초 수학부터 미국 역사, 법률, 컴퓨터 과학, 공학, 의학 등 57개 영역에서 수만가지 도전문제를 풀게 된다.
이에 마이크로소프트 연구진은 GPT-4에 기존 메드프롬프트를 적용해 MMLU에서 89.1%의 점수를 달성했다. 이후 메드프롬프트의 항상블 호출 수를 5개에서 20개로 늘린 뒤 같은 테스트에서 89.56%로 점수를 더 높일 수 있었다고 한다. 그리고 더 간단한 프롬프트 방법을 추가하고, 기본 전략과 단순 프롬프트 출력을 통합해 최종답변을 도출하는 정책을 공식화해 '메드프롬프트+'를 만들었다. 메드프롬프트+를 활용한 GPT-4는 MMLU 테스트에서 90.10%를 기록해 구글 제미나이 울트라를 약간 앞섰다.
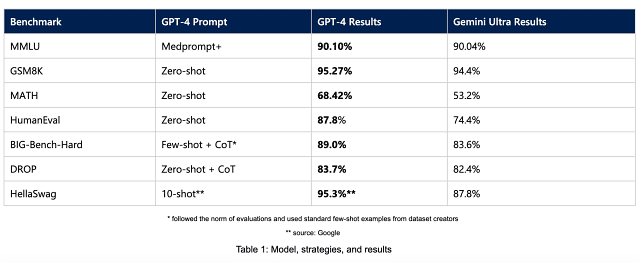
MMLU뿐 아니라 GSM8K, MATH, Humaneval, BIG-Bench-Hard, DROP, HellaSwag 등의 테스트에서도 GPT-4는 제미나이 울트라보다 더 높은 성적을 받았다. 심지어 MMLU를 제외한 타 테스트의 경우 GPT-4는 제로샷으로 제미나이 울트라를 앞섰다. 제로샷은 언어모델이 배우지 않은 작업을 수행하는 것을 의미한다.
에리 호비츠는 "최종 답변의 종합은 GPT-4에 의해 관리되는 제어 전략과 후보 답변의 추론된 신뢰도에 따라 진행된다"며 "복잡하고 간단한 쿼리를 결합하는 관련 방법은 구글 제미나이팀에서 활용했던 것"이라고 설명했다.
그는 "수정된 메드프롬프트+는 GPT-4의 신뢰점수(logprobs)에 접근하는 데 의존한다"며 "현재 API를 통해 공개적으로 사용할 수 없지만 가까운 시일 내에 모두 사용할 수 있게 될 것"이라고 덧붙였다.
파운데이션모델은 주로 인터넷 상에 공개된 데이터를 학습한다. 조직 내부에 보호된 전문 데이터를 학습하지 못하고, 특정 시점까지의 데이터만 학습하므로 생성하는 정보의 전문성과 최신성에 약점을 갖는다. 이때문에 파운데이션모델을 특별히 선별된 데이터로 더 학습시키는 미세조정을 사용하게 된다.
마이크로소프트 연구진은 막대한 비용을 들여야 하는 미세조정을 줄일 방법으로 파운데이션모델을 더 광범위하게 훈련시키는 방법을 연구했고, 자신들의 발상을 입증하고 있다.
에릭 호비츠는 "체계적인 프롬프트 엔지니어링으로 최대 성능을 얻을 수 있지만, 간단한 프롬프트를 통해 프론티어 모델의 기본 성능을 계속해서 탐색했다"며 "GPT-4의 기본 기능과 제로샷 또는 퓨샷 프롬프트 전략으로 모델을 어떻게 조종할 수 있는지 계속 주시하는 게 중요하다"고 밝혔다.
구글의 제미나이는 모델의 크기에 따라 ▲제미나이 울트라 ▲제미나이 프로 ▲제미나이 나노 등 세 버전으로 존재한다. 이중 제미나이 울트라는 아직 외부에 공개되지 않았으며, 현재는 제미나이 프로와 나노만 외부에 공개돼있다.
관련기사
- 생성AI, 미세조정보다 프롬프팅이 나을 수 있다2023.12.04
- 구글 "제미나이 프로, 맞춤형으로 사용 가능"2023.12.14
- "구글 제미나이 시연은 과장됐다"2023.12.09
- '제미나이' 영상 봤더니…"논리-추론 탁월, GPT-4 능가는 글쎄?"2023.12.07
구글에서 공개한 논문 속 테스트 결과표에 의하면, 제미나이 프로의 경우 MMLU 테스트에서 GPT-3.5를 앞선 79.13%를 받은 것으로 공개됐었다. 다만, 제미나이 프로가 사용한 방법론은 제미나이 울트라와 다르며, GPT-3.5의 방법론도 다르다. 이에 제미나이와 GPT를 동일한 방법론으로 테스트해 비교해야 한다는 반론이 제기됐다.
구글이 제미나이 울트라의 벤치마크 테스트에 사용한 방법론은 'CoT@32'라 불린다. 여러 방법을 혼합한 것이지만, 대표적인 방법은 쿼리를 답변에 따라 꼬리물듯 이어서 LLM에 던지는 것이다. 사고사슬(CoT)로 해석되는 이 기법은 특정 작업에서 LLM에게 최종답변을 받기까지 질문을 계속 던져 답변을 다듬어 간다. CoT@32는 컨텍스트 길이를 3만2천 토큰으로 설정한 것이다.