






오픈AI의 GPT-4나 구글의 PaLM2 같은 대규모언어모델(LLM)은 파운데이션모델로서 그 자체로 큰 역량을 가졌지만 특정 분야에서 맥락을 이해하지 못하고 수준이하 혹은 잘못된 답변을 내놓기 쉽다. 이에 모델 미세조정을 활용해 특화 모델을 만드는게 일반적이다. 하지만 최근 한 의학 분야 연구에서 GPT-4를 미세조정하지 않고 프롬프트 엔지니어링만 사용해 더 나은 성능을 낼 수 있다는 결과가 나와 주목받고 있다.
지난달 28일 마이크로소프트 연구블로그에 '프롬프팅의 힘'이란 제목의 글이 게재됐다. 에릭 호비츠 마이크로소프트 최고과학책임자의 글로, 일반 GPT-4 모델이 의학적 과학 문제 벤치마크에서 미세조정된 모델을 능가하는 성적을 받았다는 내용을 담았다.
에릭 호비츠는 "이 결과는 일반 파운데이션 모델에서 영역별 전문 지식을 불러일으키는데 프롬프트 전략이 얼마나 효과적일 수 있는지 보여주는 연구 중 하나"라며 "일반적 추론 능력을 넘어 GPT-4가 다양한 영역에서 도메인별 전문가로 활동할 수 있다는 사실을 발견했다"고 밝혔다.

파운데이션모델은 주로 인터넷 상에 공개된 데이터를 학습한다. 조직 내부에 보호된 전문 데이터를 학습하지 못하고, 특정 시점까지의 데이터만 학습하므로 생성하는 정보의 전문성과 최신성에 약점을 갖는다. 이때문에 파운데이션모델을 특별히 선별된 데이터로 더 학습시키는 미세조정을 사용하게 된다.
연구진은 막대한 비용을 들여야 하는 미세조정을 줄일 방법으로 파운데이션모델을 더 광범위하게 훈련시키는 방법을 연구했다.
이에 지난 3월 연구진은 간단한 프롬프팅 전략만으로 GPT-4의 의학적 지식에 대한 역량을 끌어낼 수 있다는 걸 입증했다.
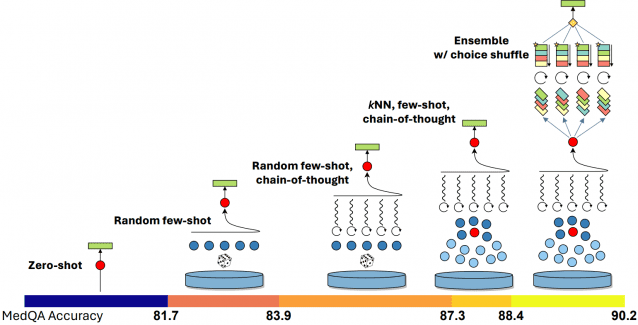
이어 최근 연구에서 여러 프롬프트 전략을 '메트프롬프트(Medprompt)'란 방법으로 구성해 GPT-4가 최고 성능을 달성할 수 있도록 효율적으로 유도하는 방법을 보여줬다. 메드프롬프트를 적용한 GPT-4는 최고의 성능을 발휘하는 것으로 나타났다.
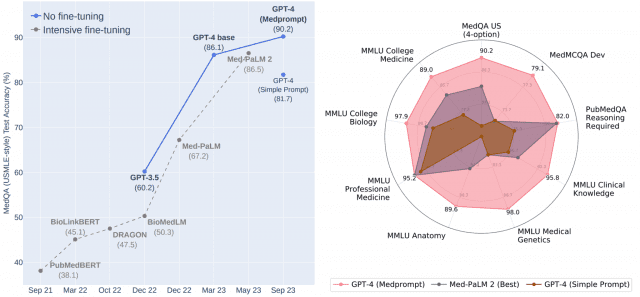
메드프롬프트를 이용한 GPT-4는 MedQA 데이터세트에서 90% 초과달성했다. MultiMedQA 제품군의 9개 벤치마크 데이터세트 모두에서 최고 결과를 달성했다. MedPaLM 2보다 MedQA에서 오류율이 27% 감소했다. MedPaLM 2는 구글에서 의료용으로 내놓은 PaLM2의 특수목적 버전이다.
메드프롬프트는 kNN 기반의 소수 예시 선택, GPT-4에서 생성된 사고 프롬프트 체인, 다수결 선택 앙상블 등을 결합한다.
에릭 호비츠는 "많은 AI 실무자가 특정 영역에서 우수한 성능을 발휘하도록 범용 파운데이션 모델을 확장하려면 전문문야 중심의 미세조정이 필요하다고 생각한다"며 "미세조정으로 성능을 향상시킬 수 있지만 이 과정은 많은 비용이 들 수 있다"고 설명했다.
그는 "미세조정을 하려면 전문가 또는 전문적으로 라벨을 지정한 데이터세트를 통해 모델 매개변수를 업데이트하고, 연산해야 하는 경우가 많다"며 "이 프로세스는 자원집약적이고 비용이 많이 들기 때문에 많은 중소규모 조직에서 접근하기 어려운 과제"라고 덧붙였다.
관련기사
- MS 임원은 생성 AI에 어떤 프롬프트를 넣을까2023.10.17
- 뤼이드의 생성 AI 도전…"교육기술기업의 LLM 활용법"2023.10.31
- "AI 모델 미세조정, 유해 답변·탈옥 확률 높여"2023.10.17
- 배달의민족, GPT로 메뉴 추천한다2023.10.30

이 연구는 범용 LLM을 추가 시간과 연산 자원 투입없이 프롬프트 엔지니어링으로 빠르게 전문분야에서 활용할 수 있다는 점을 보여줘 눈길을 끈다. 의학분야에 한정된 연구지만 다른 전문분야에서도 활용가능할 것으로 기대된다.
에릭 호비츠는 "우리가 제시하는 프롬프트 방식은 전기공학, 머신러닝, 철학, 회계, 법률, 심리학 등 다양한 분야의 전문 역량 시험에서 도메인별 업데이트 없이도 가치있다는 것으로 나타났다"고 강조했다.





