






이미지생성 인공지능(AI) 개발회사 스태빌리티AI가 비디오를 생성하는 첫 파운데이션 모델을 공개했다.
21일(현지시간) 스태빌리티AI는 이미지모델 스테이블디퓨전에 기반한 비디오 생성 모델 '스테이블 비디오 디퓨전'을 리서치 프리뷰로 발표했다.
스테이블 비디오 디퓨전은 모든 유형의 비디오 창작자를 위한 모델을 목표로 만들어지고 있다.

회사측은 이 미비도 모델은 멀티 뷰 데이터세트에 대한 미세조정을 통해 단일 이미지에서 멀티뷰 합성을 비롯한 다양한 하부 작업에 쉽게 적용될 수 있다고 설명했다. 스테이블디퓨전과 유사한 생태계를 구축하고 그 기반을 확장하는 다양한 모델을 개발중이라고 회사측은 밝혔다.
대기 신청을 통해 이용자는 접근권을 획득하고 텍스트투비디오 인터페이스를 갖춘 웹 UI를 이용할 수 있다. 광고, 교육, 엔터테인먼트 등 다양한 분야에서 스테이블 비디오 디퓨전의 적용사례를 보여준다.
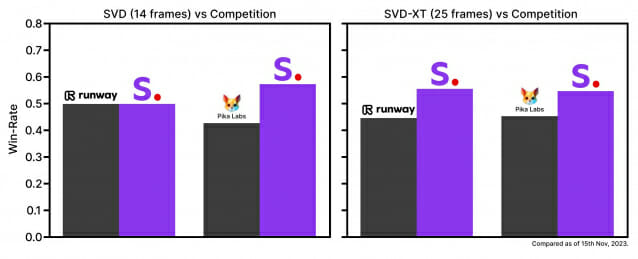
회사에 따르면, 스테이블 비디오 디퓨전은 초당 3~30 프레임 사이의 프레임 속도로 14 프레임과 25 프레임을 생성할 수 있는 두가지 모델로 출시됐다. 테스트에서 스테이블 비디오 디퓨전이 런웨이나 피카랩스보다 더 뛰어난 성능을 보이는 것으로 나타났다.
관련기사
- 스태빌리티AI, 오디오 생성 AI 공개…95초짜리 CD 음질2023.09.14
- 이미지생성 AI '스테이블디퓨전XL 1.0' 출시2023.07.27
- 손으로 그린 스케치, 예술작품으로 바꾸는 AI 등장2023.07.14
- 이미지 생성 AI, '독창성'·'정교함'으로 승부2023.07.06
스테이블 비디오 디퓨전은 깃허브 저장소에서 코드를 사용할 수 있으며, 허깅페이스 페이지에서 로컬 실행에 필요한 가중치를 확인할 수 있다.
스태빌리티AI 측은 "이 모델은 현재 단계에서 실제 또는 상업용 애플리케이션을 위한 게 아니다"라고 강조했다.





