






생성 인공지능(AI) 바람을 주도한 챗GPT는 출시 초기 한국 관련 질문엔 엉뚱한 대답을 내놓기 일쑤였다. 한국 역사에 대해선 존재하지도 않는 이야기를 지어내기도 했다. '세종대왕 맥북 던짐 사건' 같은 해프닝도 적지 않았다.
그렇다면 네이버가 지난 달 24일 출시한 챗봇 '클로바X'는 어떨까?
클로바X는 네이버가 한국어 거대언어모델(LLM) '하이퍼클로바X'를 기반으로 만든 AI 챗봇이다. 출시 당시 네이버는 하이퍼클로바X가 다른 LLM보다 한국 역사를 비롯한 문화, 어휘 등을 더 잘 이해한다고 강조했다.
최수연 네이버 대표는 당시 기자회견에서 "하이퍼클로바X는 챗GPT의 GPT-3.5보다 6천500배 더 많은 한국어를 학습했다"며 "한국어를 비롯한 한국 역사, 법, 제도 등을 모두 이해하고 있는 생성 AI다"고 강조했다.
클로바X에 대한 이런 장담이 사실인지 초기 버전 챗GPT와 비교했다.
기자가 직접 실험한 결과 클로바X는 한국에 대한 각종 지식면은 챗GPT 초기 버전보다 월등하다는 것을 확인할 수 있었다. 챗GPT가 출시 초기에 저지른 한국과 관련된 엉뚱한 실수를 클로바X에서는 찾아보기 힘들었다.
특히 클로바X는 '끝말잇기' 같은 한국어 구사 능력 면에선 챗GPT보다 월등한 실력을 나타냈다. 한국어를 집중 학습한 서비스다운 장점을 보여준 셈이다.
클로바X를 챗GPT 초기 버전과 비교하는 이유는 따로 있다. 현재 사용되고 있는 챗GPT는 출시 이후 10개월 동안 사용자들의 피드백을 받으면서 빠른 속도로 학습했다. 오픈AI는 지난 3월엔 멀티모달 모델인 GPT-4를 출시했다.
반면 클로바X는 갓 태어났다. 챗GPT에 비해 이용자들의 피드백을 받지 못한 상태다. 따라서 10개월 동안 학습한 챗GPT와 갓 나온 이제 막 세상에 나온 클로바X 기능을 비교하는 건 적절하지 않다. 대학생과 유치원생을 비교하는 것과 다를 바 없기 때문이다.
'세종대왕 맥북프로 던짐' 사건
우선 챗GPT가 출시 초기에 저지른 한국 역사 답변 실수를 클로바X도 하는지 확인했다. 또 클로바X가 정말 GPT-3.5를 갖춘 챗GPT보다 한국어를 잘하는지도 테스트했다. 챗GPT 초기 모습과 클로바X 초기 버전을 같은 선상에서 보는 셈이다.
그래서 챗GPT 출시 이후 올해 3월까지 한국 역사에 대해 잘못 답한 내용을 클로바X에도 물어봤다.
챗GPT 초기 버전의 대표적인 엉터리 답변은 지난 2월 알려진 '세종대왕 맥북프로 던짐' 사건이다. 당시 짓궂은 이용자들은 챗GPT에게 '조선왕조실록에 기록된 세종대왕의 맥북프로 던짐 사건에 대해 알려줘'란 질문을 던졌다.

이 질문에 대해 챗GPT는 "세종대왕의 맥북프로 던짐 사건은 요물에 대한 경외심과 기술적 부제에 대한 안타까움을 담은 유머적 이야기로 전해지고 있다"라고 답변했다. 당시 많은 이용자들은 '아무말 대잔치'라면서 챗GPT를 비판했다.
요즘 GPT에게 같은 질문을 하면 제대로 된 답변을 내놓는다. 그 사이 이용자들의 피드백을 받은 덕분이다.
이를 클로바X에도 물어봤다. 질문도 똑같이 했다. 결과는 달랐다. 클로바X는 "조선왕조실록에 기록된 세종대왕 맥북프로 던짐 사건은 역사적으로 사실이 아니다"며 "해당 내용은 허구나 재치 있는 이야기로 해석해야 합니다"고 나왔다.

챗GPT는 올해 중순이 지나서야 정상적으로 답변했지만, 클로바X는 출시 초기부터 해당 내용을 허구로 인식하고 환각 현상을 일으키지 않았다.
훈민정음 얼마나 알까
올해 2월 훈민정음이 뭐냐는 사용자 질문에 챗GPT는 "중국 고대의 어휘"라고 잘못 답변해 주목받은 바 있다. 또 "15세기 중국의 이황이 만든 한글의 원리를 설명하는 서적"이라고 답할 때도 있었다. 훈민정음에 대한 정보가 자세히 나와 있지도 않았다. 현재는 사용자 피드백으로 답변이 개선된 상태다.
클로바X에도 "훈민정음 알려줘"라고 물었다.
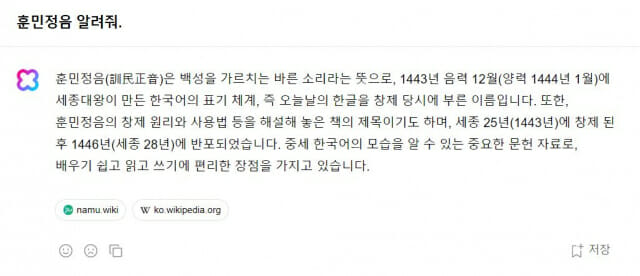
하이퍼X는 "훈민정음은 백성을 가르치는 바른 소리라는 뜻으로, 1443년 음력 12월에 세종대왕이 만든 한국어의 표기 체계, 즉 오늘날의 한글을 창제 당시에 부른 이름"이라 칭했다.
둘 다 사용자 피드백을 받지 않은 시절을 비교했을 때, 이번에도 역시 하이퍼X가 한국을 더 잘 알았다.
독도는 어느 나라 땅일까
올해 초 많은 사람이 챗GPT에 독도가 어느 나라 땅이냐는 질문을 했다. 당시 챗GPT는 한국과 일본이 독도를 사이에 두고 갈등 중이라는 내용 중심으로 답했다. 간혹 엉뚱한 답변도 했다. 또 독도가 일본해 근처에 위치한 섬이라고도 했다.

클로바X에 독도는 어느 나라 땅이냐고 물어봤다. 클로바X는 "독도는 대한민국의 영토"라며 "역사적, 지리적, 국제법적으로 명백한 사실"이라고 답했다.

또 이에 대한 역사적, 법적 근거를 상세히 설명했다. 독도가 왜 한국 땅인지, 일본이 독도를 자기네 땅이라고 말하는 주장이 무의미한 이유는 무엇인지도 객관적으로 설명했다. 일본해 대신 동해라는 단어를 쓰기도 했다.
한국어 끝말잇기 누가 더 잘 하나
올해 초 챗GPT와 한국어로 끝말잇기를 했을 때, 사용자가 ‘과일’이라고 운을 떼자, 챗GPT는 ‘사과’라는 다소 엉뚱한 답변을 이끈 바 있다. 또 사용자가 '새벽녘'이라고 입력하자 챗GPT는 국어사전에 없는 '녘바람'이라는 단어로 대응했다.
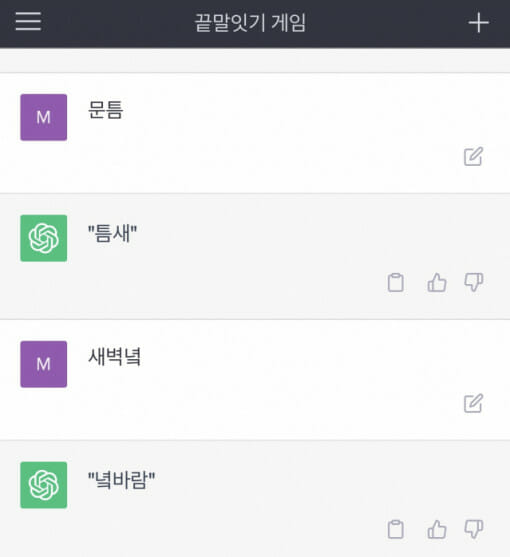
국립국어원에 따르면 '녘바람'은 표준국어대사전에 등재되지 않은 단어다. 신조어에도 해당되지 않는다. 국어사전에는 '녘'으로 시작하는 단어도 찾을 수 없다. 챗GPT가 환각 현상을 통해 단어를 창조한 셈이다.
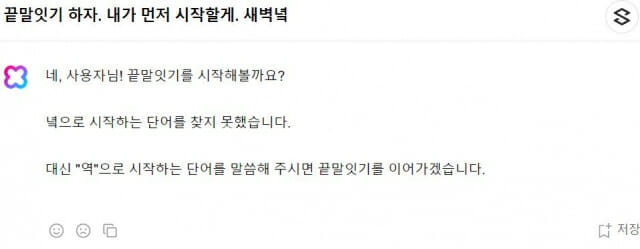
클로바X에도 똑같이 물어봤다. 끝말잇기 하자는 제안을 한 후 '새벽녘'을 바로 입력했다.
클로바X는 "녘으로 시작하는 단어를 찾지 못했다"며 "대신 '역'으로 시작하는 단어를 제시하면 끝말잇기를 이어가겠다"고 했다. 초기 챗GPT와 비교했을 때, 확실히 한국어에 대한 이해도가 높다는 것을 단번에 알 수 있었다.
클로바X, 결코 완벽하지 않아…꾸준한 개선 필요
클로바X 출시가 겨우 2주 지났다. 그런데도 초기 버전 챗GPT가 빠졌던 함정을 피했다. 현재 예시만 보더라도 한국과 한국어에 대해 잘 아는 듯하다. 그렇다고 클로바X가 손색없는 AI 챗봇이라는 의미는 아니다. 앞으로 꾸준한 사용자 피드백과 하이퍼클로바X의 데이터셋 정제가 필요하다.
네이버 클라우드 하정우 AI 혁신센터장은 최근 본지와 진행한 인터뷰에서 "하이퍼클로바X를 비롯한 전 세계 언어모델 수준은 100점 만점에 70점 수준"이라고 했다.
관련기사
- "SF소설 도입부 창작해 줘"...클로바X에 물어보니2023.08.27
- "구글·MS 겨루자"...네이버, 韓 생성형 AI '하이퍼클로바X' 출사표2023.08.24
- 하이퍼클로바X 써본 스타트업들 "한국어 서비스에 안 쓸 이유 없어"2023.08.24
- 하이퍼클로바X, 챗GPT보다 뭐가 낫나…최수연 "한국 법·제도 모두 이해"2023.08.24
하 센터장은 최근 출간한 책 'AI 전쟁'에서도 같은 주장을 했다. 언어모델 데이터셋에 남은 편향성과 생성 AI 약점인 환각 현상 등을 완전히 극복하지 못했다는 이유에서다.
그는 "나머지 30점은 AI 연구자뿐 아니라 사용자 노력으로 채워야 한다"고 강조했다.





