



구글클라우드는 최근 개최한 연례 컨퍼런스에서 주특기인 데이터 관련 새 기술을 대거 공개했다.
엔터프라이즈급 생성 AI 구축을 지원하도록 데이터베이스 서비스를 강화하고, 데이터베이스도 생성 AI를 채택해 작업을 단순화했다. 트랜잭션 시스템에 영향을 주지않고 바로 분석할 수 있는 통합 데이터 환경도 정식 출시했다. 빅쿼리는 더 쓰기 쉬워지고 더 많은 영역을 다룰 수 있게 발전했다. 전체 데이터제품군의 워크플로우를 모두 작업하는 통합 작업 공간도 나왔다.
구글클라우드는 지난달 30일 미국 샌프란시스코에서 개최된 '구글클라우드 넥스트23'에서 알로이DB AI, 듀엣AI인클라우드스패너, 클라우드스패너 데이터부스트, 클라우드SQL 업데이트, 빅쿼리 스튜디오 등 데이터베이스 관련 발표를 대거 공개했다.

■ 알로이DB, 생성 AI 개발 지원 강화
구글클라우드의 매니지드형 포스트그레SQL 데이터베이스 서비스인 알로이DB는 엔터프라이즈 기업의 생성 AI 구축을 지원하는 '알로이DB AI'를 제공한다. 알로이DB AI는 고성능 pgVector 호환 벡터 검색을 제공한다.
이는 표준 포스트그레SQL보다 최대 10배 빠르고, 4배 더 큰 벡터를 지원한다. 데이터베이스 내에서 임베딩을 쉽게 생성하고, 버텍스AI나 오픈소스 생성 AI 도구와 통합가능하다. 알로이DB AI는 다운로드버전인 알로이DB 옴니로 미리보기로 제공된다. 올해 후반 알로이DB 클라우드 서비스로 제공될 예정이다.
■ 클라우드 스패너에 들어간 생성 AI 기능
구글의 생성 AI 보조도구인 '듀엣AI'는 클라우드 스패너에 투입됐다. 클라우드 스패너는 대규모로 수평 확장 가능한 데이터베이스다. 클라우드 스패너의 듀엣AI를 이용하면 사람의 언어로 데이터를 구조화, 수정, 쿼리하는 코드를 생성할 수 있다. 구글에 따르면 '메시지 테이블의 모든 데이터를 표시하는 쿼리 작성'을 듀엣AI에 요청하면 알아서 필요한 SQL이 생성된다. 생성된 SQL은 추가로 검토하거나 수정할 수 있다.
구글클라우드는 향후 알로이DB, 클라우드SQL 등 타 데이터베이스에도 듀엣AI를 적용할 계획이라고 밝혔다.
■ 듀엣AI 활용해 오라클에서 알로이DB로 DB 마이그레이션
데이터베이스 마이그레이션 서비스도 강화됐다. 오라클에서 포스트그레SQL이나 알로이DB용 클라우드SQL로 이전하는 기능이 정식 출시됐다. 데이터베이스 마이그레이션 서비스도 듀엣AI를 사용해 오라클에서 포스트그레SQL로 이전하는 마지막 단계에 코드변환을 요청해 오라클DB의 저장 프로시저, 함수, 트리거, 패키지 및 사용자정의 PL/SQL 코드 등을 포스트그레SQL로 자동 변환할 수 있다.
■ 트랜잭션 환경 '클라우드 스패너'에 바로 쿼리 날리는 '데이터부스트'
구글 클라우드 스패너에 저장된 운영 데이터를 빅쿼리, 데이터플로 같은 서비스로 바로 분석할 수 있는 '클라우드 스패너 데이터부스트'가 정식 출시됐다. 이 서비스는 거래 처리 워크로드에 영향을 거의 주지 않고 분석, 보고 등을 위한 데이터를 조회할 수 있다.
클라우드스패너 데이터부스트는 분리된 컴퓨팅 및 스토리지 아키텍처를 활용하므로 조회 시 기존 트랜잭션 워크로드에 영향을 거의 주지 않는다. 트랜잭션 환경에서 분석 시스템으로 데이터를 복제, 이동하지 않으므로 파이프라인 구축 및 운영 부담이 사라진다. 분석 시 항상 최신의 데이터를 활용할 수 있다는 게 가장 큰 장점이다.
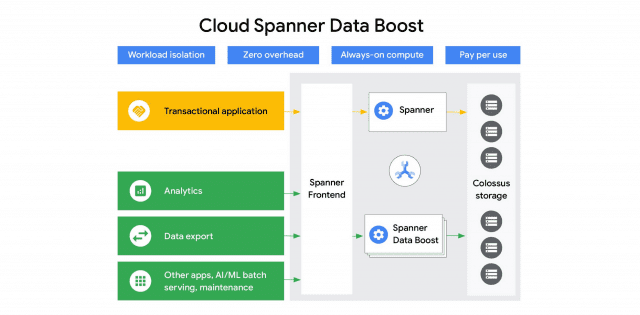
데이터부스트 사용자는 용량 프로비저닝이나 관리가 필요없다. 스패너의 분산스토리지인 콜로서스(Colossus)에 저장된 데이터를 직접 처리하기 위해 사용자 쿼리를 항상 수신할 준비를 하고 있다. 데이터부스트 사용자마다 접근권한을 부여하면 코드나 스키마 변경없이 바로 사용할 수 있다. 데이터부스트는 쿼리 실행 방법을 알아서 최적화된 방식으로 결정해 더 적은 비용으로 더 높은 성능을 누리게 해준다.
비용은 쿼리 처리에 필요한 CPU, 메모리, 데이터 접근 등을 포함하는 서버리스프로세싱유닛(SPU)로 측정돼 사용량에 따라 과금된다. 비용초과를 방지하기 위해 사용자나 특정쿼리 사용량을 감시하고 제한할 수 있다.
■ 빅쿼리에서 빅테이블로 역방향 ETL
빅쿼리에서 빅테이블 운영 데이터베이스로 데이터를 쉽게 보낼 수 있게 됐다. 빅쿼리는 빅테이블로 역방향 ETL을 지원해 별도의 ETL 수정없이 애플리케이션에 분석 정보를 제공할 수 있다.
머신러닝이나 AI 시스템으로 데이터 분석 결과를 다시 보내는 흐름을 형성하는 사례가 늘어나고 있다. 빅쿼리의 역방향 ETL은 별도의 데이터 파이프라인을 운영하는 부담을 없애준다.
■ 데이터 분석 제품군의 공동 작업 공간 '빅쿼리 스튜디오'
구글클라우드의 데이터 분석 제품군을 위한 통합 공동 작업공간으로 '빅쿼리 스튜디오'가 공개됐다.
빅쿼리 스튜디오는 데이터 수집, 준비, 분석, 탐색, 시각화 등에 이르는 분석 워크플로우를 모두 다룰 수 있는 툴이다. 빅쿼리 내에서 SQL, 파이썬, 스파크, 또는 자연어를 사용할 수 있고, CI/CD 버전 기록, 소스 제어 등을 데이터 자산으로 확장할 수 있다. 빅쿼리 내 데이터 계보, 프로파일링, 품질 등 거버넌스 관리도 가능하다.
코랩(Colab) 노트북 환경에서 파이선으로 픽쿼리의 데이터를 분석할 수 있다. 빅쿼리 스튜디오의 노트북 환경은 데이터세트 및 스키마 탐색, 데이터세트 및 열 자동 완성, 데이터 쿼리 및 변환 등을 지원한다. 모델학습, 맞춤설정, 배포, ML옵스 등을 위해 버텍스AI에서 동일한 코랩엔터프라이즈노트북에 접근할 수 있다.

아파치 파케이, 델타레이크, 아파치 아이스버그 등을 지원하는 빅레이크를 활용해 구글클라우드, 마이크로소프트 애저, 아마존웹서비스(AWS) 등 멀티클라우드에 저장된 정형, 비정형, 반정형 데이터를 단일 창에서 활용할 수 있다.
빅쿼리 스튜디오를 통해 SQL 스크립트, 파이썬 스크립트, 노트북, SQL 파이프라인 등의 분석 자산에 버전관리나 소스제어 등 소프트웨어 개발 권장사항을 적용할 수 있다.
빅쿼리 듀엣AI는 사용자와 데이터의 맥락을 이해하고, 이를 사용해 SQL과 파이썬용 함수, 코드블록을 자동 제안한다. 채팅 인터페이스로 자연어를 사용해 특정 작업 수행에 대한 개인화된 실시간 지침을 얻을 수 있다.
데이터 실무자는 빅쿼리 스튜디오를 활용해 데이터 품질을 관리할 수 있다. 데이터 계보 추적, 프로파일링, 품질 제약 조건 적용 등으로 고품질이면서 정확하고 신뢰할 수 있는 데이터를 유지할 수 있다. 연말께 데이터세트 요약, 심층분석 도출 방법 권장사항 등 맞춤형 메타데이터 통계가 제공될 예정이다.
빅쿼리 스튜디오는 버텍스AI와 통합돼 빅쿼리 내에서 버텍스AI의 생성 AI 모델의 연동을 지원한다. 데이터파이프라인을 별도로 구축하지 않고 빅쿼리와 버텍스AI 간 연결된다.
빅쿼리는 개인정보를 보호하면서 데이터를 공유하고 분석할 수 있도록 '데이터 클린룸'을 도입했다. 데이터 클린룸을 간단히 만들고 배포해 조직 외부인과도 안전하게 협업할 수 있다.
■ 클라우드SQL 파트너 인증
마이SQL, 포스트그레SQL, SQL서버 등의 데이터베이스를 매니지드형으로 제공하는 '클라우드SQL'의 경우 핵심 기능 및 상호운용성 요구사항을 충족한 파트너를 공식 인정하는 '구글클라우드레디 클라우드SQL'을 출시했다. 평가, 강화, 지원 등 3단계를 거쳐 데이터통합, 마이그레이션, 비즈니스인텔리전스, 고급분석, 머신러닝, 데이터품질, 옵저빌리티, 보안 등의 파트너 기술과 통합을 검증한다. 현재 34개 파트너가 인증을 받았다.
관련기사
- 딥마인드, AI 생성 이미지에 투명 워터마크 입히는 기술 공개2023.08.30
- 구글클라우드, 생성 AI 플랫폼 '버텍스AI' 생태계 확장2023.08.30
- LG전자, 품질 검사 AI 도입…구글 클라우드 기반2023.08.18
- 구글클라우드 '빅쿼리 옴니' AWS 서울 리전 지원2023.05.18
이밖에도 레디스 클러스터용 메모리스토어가 미리보기로 발표됐다. 마이크로초 단위 지연시간으로 시존보다 60배 더 많은 처리량을 제공하고 10배 더 많은 데이터를 지원한다. 고가용성 및 복원력을 위한 노드의 지능적 자동 영역 분산, 자동화된 복제본 관리 및 승격, 99.99% 가용성 SLA를 제공한다.
또한 빅테이블 변경 스트림 기능이 출시돼, 변경 사항 발생 시 빅테이블의 변경 사항을 캡처해 스트리밍할 수 있다. 클라우드 빅테이블의 백업 사본을 생성해 모든 지역과 프로젝트에 최대 90일동안 보관할 수 있다. 비공개 미리보기로 발표된 클라우드 빅테이블 요청 우선순위는 시간에 민감하지 않은 대규모 워크로드를 빅테이블 클러스터에서 낮은 우선순위로 실행해 일괄 처리의 영향을 최소화하게 해준다. 클라우드 스패너는 자동 생성 키를 지원해 스키마 작성자가 중요한 ID 논리를 데이터베이스에 푸시할 수 있게 한다.





