



구글이 대규모 언어모델(LLM) 스스로 디버깅해 정확도를 높이는 방식을 공개했다.
연구 결과 현재 최대 12%까지 정확도를 높였으며 이후 더욱 높은 효율을 기록할 수 있을 것이라고 밝혔다.
최근 싱크드닷컴에 다르면 구글 연구팀과 버클리대학 연구팀은 ‘대규모 언어 모델의 자체 디버깅 교육’이라는 논문을 아카이브에 발표했다.
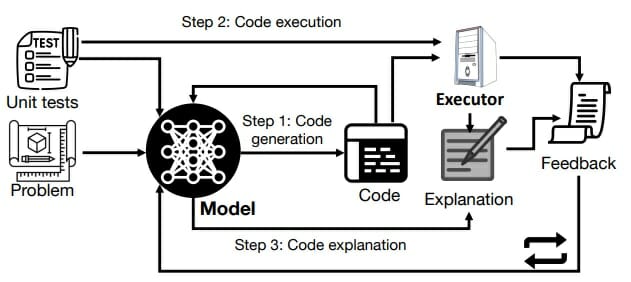
구글은 자체 디버깅을 연구한 이유에 대해 LLM을 새로 학습시킬 때마다 과도하게 소비되는 비용과 에너지, 시간을 줄이기 위함이라고 밝혔다.
방대한 데이터과 복잡한 구조로 인해 한 번에 올바른 솔루션을 생성하는 것이 어려워지는 상황에서 일일이 사람이 테스트하고 결과를 확인하는 것이 아니라 AI가 테스트하고 검증할 수 있는 환경을 조성하는 것이다.
대표적인 LLM인 GPT-3의 경우 1회 학습 비용이 약 150억 원 정도로 알려져 있다.
LLM은 광범위한 복잡한 작업에서 인상적인 기능을 지속적으로 보여주며 컴퓨터 코드 생성에도 능숙하다. 하지만 이런 고성능 AI 역시 사람의 지시와 같은 외부 피드백 없이 컴퓨터 코드를 확인하고 수정하기 위해선 새로운 방안을 고안해야 했다.
이를 위해 연구팀은 먼저 프롬프트를 통해 몇 번의 입출력 예시 작업을 마련한 후 이중 어떤 방식이 더 나은지 지침을 마련했다. 이후 LLM을 활용한 몇 번의 반복작업을 통해 올바른 실행 결과가 가장 많이 나오는 예측 코드를 디버깅하도록 가르치는 프레임워크를 구축했다.
논문에 따르면 이러한 작업 과정은 복잡한 프로그래밍 없이 프롬프트로 이뤄졌으며 정확도 최대 12%까지 향상됐다.
관련기사
- MS·서비스나우, 노코드와 AI 결합으로 생산성 극대화2023.03.24
- "실패 없는 디지털 전환, 비법은 체인지 매니지먼트"2023.04.10
- "챗GPT, PPT·엑셀 문서까지 뚝딱 만든다"2023.03.17
- AI 얻은 '빙 검색' 인기…이틀만에 100만명 대기2023.02.14
구글 연구팀은 "LLM은 인상적인 성능을 달성하며 우리를 다음 세대로 이끌고 있다"라며 "하지만 복잡한 프로그래밍 작업은 일부 작업에서 문제를 발생시킬 수 있어 자체 디버깅을 제안하게 됐다"고 설명했다.
이어서 "몇 번의 데모 시연을 통해 우리는 자체 디버깅이 LLM을 코드 정확성이나 오류 메시지에 대한 피드백 없이 실수를 식별할 수 있는 것을 확인했다"며 "이를 활용하면 LLM을 효율과 활용성을 더욱 높일 수 있을 것"이라고 강조했다.





