



구글이 딥러닝 모델 최적화 컴파일러 프로젝트인 '오픈XLA'를 오픈소스로 공유했다. 텐서플로우, 파이토치, JAX 등 다양한 인공지능(AI) 프레임워크에서 모두 사용가능하다. 프로젝트에 웬만한 하드웨어 및 클라우드 서비스 회사를 참여시켜 표준 컴파일러로 내세우는 모습이다.
구글은 최근 머신러닝 프레임워크의 모델을 위한 공통 컴파일러인 '오픈XLA' 프로젝트를 공개했다.
XLA는 구글의 딥러닝 전용칩인 TPU 칩과 텐서플로우 프레임워크에 최적화된 컴파일러였다. 개발자는 오픈XLA를 활용해 텐서플로우와 TPU 외에 다양한 하드웨어와 프레임워크에서 모델을 쉽게 최적화할 수 있다.

오픈XLA 프로젝트는 XLA, 스테이블HLO, IREE 저장소 등을 포함한다. 이 프로젝트에 알리바바, 아마존웹서비스, AMD, 애플, ARM, 세레브라스, 구글, 그래프코어, 허깅페이스, 인텔, 메타, 엔비디아 등이 생태계 구성에 동참했다.
제임스 루빈 구글 머신러닝 제품관리자는 "수많은 산업분야의 개발팀이 머신러닝을 사용해 질병 예측 및 예방, 개인화된 학습 경험, 블랙홀 물리학 같은 복잡한 문제를 해결하고 있다"며 "모델 매개변수 수가 기하급수적으로 증가하고, 딥러닝 모델을 위한 컴퓨팅이 6개월마다 두배 증가함에 따라 개발자는 인프라의 최대 성능과 활용도를 추구하고 있다"고 설명했다.
그는 "개발팀이 다양한 하드웨어 장치를 텐서플로우나 파이토치에 연결하는 공통 컴파일러 없이 머신러닝을 효율적으로 실행하기 위해선 각 하드웨어 대상에 대한 모델 작업을 수동으로 최적화해야 한다"며 "맞춤형 소프트웨어 라이브러리 사용이나 도메인 전문지식을 필요로 하는 장치별 코드 작성은 유지 관리 비용 부담 가중과 공급업체 종속을 야기한다"고 강조했다.
오픈XLA 프로젝트는 성능, 확장성, 이식성, 유연성 등의 이점을 제공한다. 개발자는 모든 프레임워크를 대상으로 삼을 수 있는 통합 컴파일러 API와, 플러그형 디바이스 특화 백엔드 및 최적화 등을 통해 광범위한 하드웨어에 대해 선호하는 프레임워크에서 모든 모델을 쉽게 컴파일하고 최적화할 수 있다. 여러 호스트 및 가속기에서 확장되고, 엣지 배포의 제약 조건을 충족하며, 미래의 새로운 모델 아키텍처로 일반화되는 현재 및 새로운 모델에 대해 고성능을 제공한다.
오픈XLA 생태계는 개발자에게 고유한 사용 사례에 맞게 재구성할 수 있는 MLIR 기반 구성 요소와, 컴파일 흐름의 하드웨어별 사용자 지정용 플러그인 지점을 제공하는 계층화되고 확장가능한 머신러닝 컴파일러 플랫폼을 구축해준다.
일단 프로젝트 지원기업의 면면을 보면 흥미롭다. 구글, 메타와 대립구도인 마이크로소프트, 오픈AI는 빠졌다.
대신 웬만한 머신러닝 관련 하드웨어 및 가상 서버를 제공하는 업체는 다 이름을 올렸다. AWS 트레이니엄과 인퍼렌시아, 구글TPU, AMD GPU, 엔비디아 GPU, ARM CPU, 그래프코어 IPU, 세레브라스 WSE, x86 CPU 등의 하드웨어를 제공하는 참여업체는 자사의 제품에서 공통의 컴파일러, 런타임 등을 제공하게 된다. 현재 업계에 출시된 딥러닝 관련 하드웨어는 XLA를 최적화 컴파일러로 지원하는 셈이다.
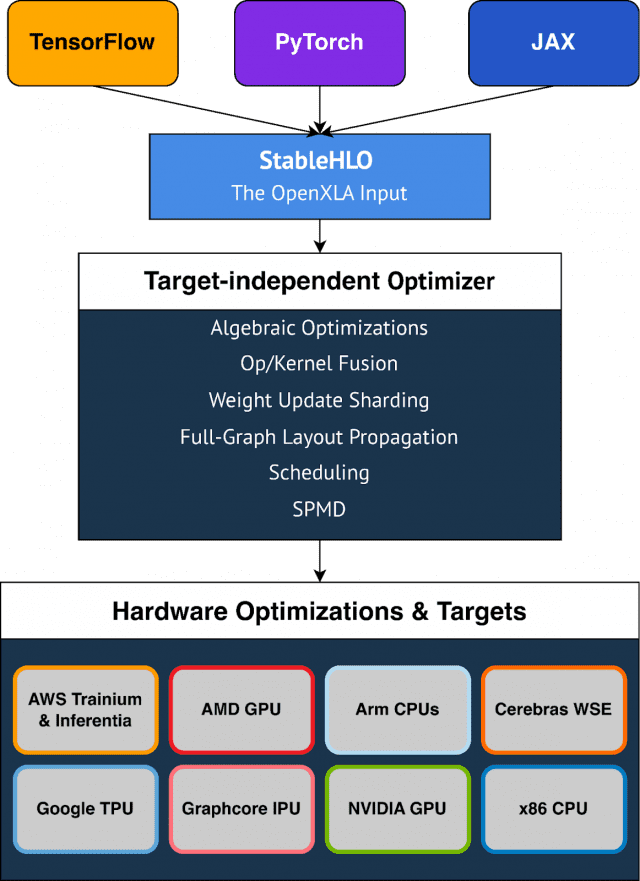
오픈XLA의 도구는 모듈식으로 이용가능하다. 표준화된 모델 표현을 활용해 이식 가능하고, 대상 독립적이면서 하드웨어별 최적화를 통해 도메인별 컴파일러를 제공한다. 오픈XLA 도구 체인은 머신러닝 학습 모델을 일관되게 표현, 최적화, 실행할 수 있게 하는 컴파일러 인프라인 MLIR을 활용한다.
고급작업용 작업집합(HLO)인 스테이블HLO는 머신러닝 프레임워크와 컴파일러 간의 이식성 계층이다. 텐서플로우, 파이토치, JAX 등 이기종 프레임워크가 스테이블HLO를 생성할 수 있다. 메타의 파이토치팀은 올해 중 2.0 버전에 스테이블HLO를 통합할 계획이다.
오픈XLA는 다수 머신러닝 사례에 적용됐다. 딥마인드의 알파폴드, GPT2, 알리바바클라우드의 스윈 트랜스포머, 아마존닷컴의 멀티모달 대규모언어모델(LLM) 등의 모델의 전체규모 트레이닝을 포함한다. 웨이모는 차량 내 실시간 추론에 오픈XLA를 활용하고 있다. 로컬 머신의 AMD RDNA 3에서 스테이블디퓨전의 최적화된 서비스에도 사용되고 있다.
구글은 "오픈XLA를 사용하면 장치별 코드를 작성할 필요없이 모델 성능을 쉽게 높일 수 있다"며 "대수식 단순화, 메모리 내 데이터 레이아웃 최적화, 피크 메모리 사용 및 통신 오버헤드를 감소하기 위한 개선된 스케줄링 등의 기능을 한다"고 밝혔다. 또 "고급 오퍼레이터 융합 및 커널 생성은 장치 활용도를 개선하고, 메모리 대역폭 요구사항을 줄이는 데 도움을 준다"고 덧붙였다.
관련기사
- ML 라이브러리 ‘파이토치 2.0’ 공개…최대 2배 속도 향상2022.12.08
- 오픈소스 ML 라이브러리 ‘파이토치’, 메타에서 독립2022.09.14
- 개발자 학습 관심 1위는 AI…자바·파이썬 제쳐2023.03.07
- AWS, 허깅페이스와 파트너십 체결...AI 경쟁 동참2023.02.22
오픈XLA는 병렬화 알고리즘 개발 단순화도 약속한다. 구글은 "GSPMD 기능을 사용하면 컴파일러가 병렬화된 계산을 자동으로 생성하는데 사용가능한 중요 텐서 하위집합에만 주석을 달면 된다"며 "이렇게 하면 여러 하드웨어 호스트와 가속기에 모델을 분할하고 효율적으로 병렬화하는데 필요한 많은 작업을 제거할 수 있다"고 설명했다.
사용자는 오픈XLA로 모델에서 핫스팟을 수동으로 조정할 수 있게다. 커스텀콜(Custum-call) 확장 매커니즘으로 쿠다(CUDA), HIP, SYCL, 트리톤(Triton) 및 기타 커널 언어로 딥러닝 프리머티브를 작성할 수 있다.





