



“파파고는 번역 품질의 좋고 나쁨을 분별할 수 있는, 이른바 ‘빨간 펜’ 선생 같은 역할을 하는 QE 모델을 마련했다. 글로벌 학회인 'WMT'에서도 경쟁력을 인정받은 만큼 고도화한 기술로, 이용자들에게 만족도 높은 번역 서비스를 제공하고 있다.”
임승현 네이버클라우드 개발자는 28일 서울 코엑스에서 열린 컨퍼런스 ‘데뷰(DEVIEW) 2023’에서 이렇게 밝히며, 네이버 파파고팀이 자체 개발한 자동 번역 품질 평가(QE) 모델을 소개했다.
번역 모델은 크게 전문가, 자동 번역 평가로 나뉜다. 전문가가 원문과 번역문을 비교해 정확성을 높이는 방식이 전자라면, 후자는 번역 모델 사이 품질을 기계가 비교, 분석한다. 전문가 평가 과정은 모두 수작업으로 진행돼 많은 시간과 비용이 소요된다. 자동 번역 평가는 다만, 정밀함이 떨어진다는 단점이 있다.

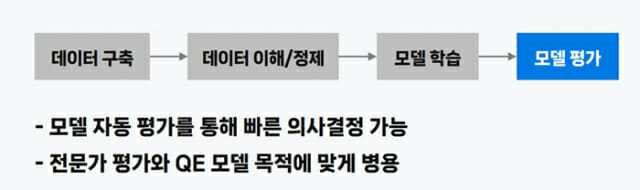
번역 품질을 제고하려면, 기존 모델과 새로운 모델 간 빠르고 정확한 비교 평가 기술이 수반돼야 한다. 네이버 파파고팀이 선보인 QE 모델은 품질 평가 과정을 자동화한 기술로, 번역 데이터를 효율적으로 단기간 평가할 수 있다는 게 강점이다.
먼저 새로운 데이터를 구축할 때, 자동으로 품질을 검수해 데이터 내 문제점을 확인하거나 의심되는 데이터를 정제할 수 있도록 했다. 이전 데이터와 품질을 비교할 수도 있다. 또 커리큘럼 학습 등에 이용돼, 모델 자동 평가를 통한 빠른 의사결정이 가능하다.
파파고 팀은 학습 데이터가 많지 않은 상황에서도 QE 모델이 원활히 작동하도록 학습 방법을 개선했다. 임 개발자는 “학습 과정에서 QE가 고품질이라고 판단한 학습 데이터 빈도수를 높이는 방법도 있다”면서 “정확도 측면에서 장점을 지닌 전문가 평가 방법을 모델 평가에 목적에 맞게 병렬적으로 사용하고 있어, 활용처가 다양하다”고 말했다.
파파고는 인공 학습 데이터를 생성해, 데이터양과 언어쌍을 보강하기도 했다. 기존 데이터와 인공 데이터를 함께 학습하면서, ‘한-일’ ‘영-독’ 등 모든 언어쌍에서 QE 성능이 향상됐다는 얘기다. 임 개발자는 “사람이 만든 데이터만으로 모델을 학습할 때 대비, 인공 데이터를 사용하면 언어쌍 평가 기준 성능이 개선됐다”고 말했다.
고품질 학습 데이터가 부족한 환경에 특화된 QE 학습 방법론도 고안했다. 가령 자연어 처리 딥러닝 언어모델인 BERT 모델을 번역 모델에 더 적합하게 미리 학습시키는 방법이다. 축구를 배우기 전, 족구를 먼저 시작하는 것과 같은 논리다.
파파고는 ‘Parallel Mining(PM, 병렬 말뭉치와 유사한 개념으로 원문에서 번역문을 생성하는 가장 높은 확률이 있는 문장을 최종 번역문으로 제시)’ 기술로 추가 데이터를 확보하고 있다. 이는 크로스 인코더(Cross encoder)와 듀얼 인코더(dual encoder)를 살펴보면 된다.
크로스 인코더는 두 문장 유사성과 차이점을 모델 내 직접 비교 분석하는 모델이다. 문장 사이 다른 점을 점검한다는 얘기다. 듀얼 인코더는 한 번에 문장 하나를 입력해 대표 의미를 추출하는 형태다.
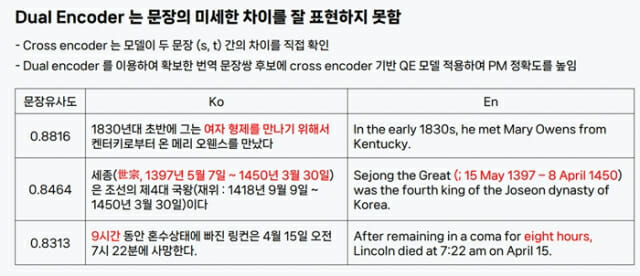
PM에서는 듀얼 인코더를 통해 각 문장을 ‘벡터화’한다. 예를 들어 ‘세종은 조선의 제4대 국왕이다’라는 문장 번역문을 확보할 때, PM은 세종에 관한 해외 문서를 탐색해 해당 문장과 유사한 번역문 후보를 추려낸다.
이후 다국어 문장 인코더를 통해 유사도를 측정해 원문에 가장 근접한 번역문을 판단한다. 이때 QE 모델을 활용함으로써, 가장 정확하게 번역된 최종 문장을 접할 수 있다.
관련기사
- [데뷰23] 네이버 "파파고, 딥러닝으로 가독성 개선했다"2023.02.27
- 네이버 클로바·파파고, 지난해 글로벌 학회서 논문 100건 발표2023.01.04
- 네이버 파파고, 통번역 대학원생이 꼽은 '가장 뛰어난 번역 앱' 선정2021.11.25
- 네이버클라우드, 파파고 문서번역·웹번역 API 공개2021.08.02
김현중 네이버클라우드 개발자는 “PM은 웹에 생성해둔 문장 데이터를 효율적으로 확보할 수 있어, 데이터 구축에 유용한 기술”이라며 “QE 모델을 PM으로 구축한 데이터 품질을 높이는 데에도 활용할 수 있다”고 말했다.
이어 “데이터는 곧 QE 모델 품질을 좌우하며, 이는 곧 번역 서비스 품질을 결정한다”며 “QE 모델과 PM 기술 학습법을 개선하며 성능을 강화해 나갈 예정”이라고 덧붙였다.





