






기계학습 알고리즘 두 번째는 나이브 베이즈 분류기(Naive Bayes Classifier)다.
이 알고리즘은 그림 1에서 표현된 베이즈 정리에 기반을 둔다. 이것은 각각의 사건들이 일어날 확률들을 측정하는 것인데 P(A ¦ B) = (P(A ∩ B)) / (P(B))를 설명한다면 다음과 같다.
1. 전제: 두 사건 A, B가 있고, 사건 B가 발생한 이후에 사건 A가 발생한다고 가정한다.
2. 정의: 사건 B가 일어난 후 사건 A가 일어날 확률이다.
3. P(A): 사건 A가 일어날 확률
4. P(B): 사건 B가 일어날 확률 = 사건 A가 발생하기 전 사건 B가 일어날 확률 = 사전확률
5. P(A¦B): 사건 B가 일어난 후 사건 A가 일어날 확률 = 조건부 확률
6. P(B¦A): 사건 A가 일어났을 때 사건 B가 앞서 일어났을 확률 = 사후확률
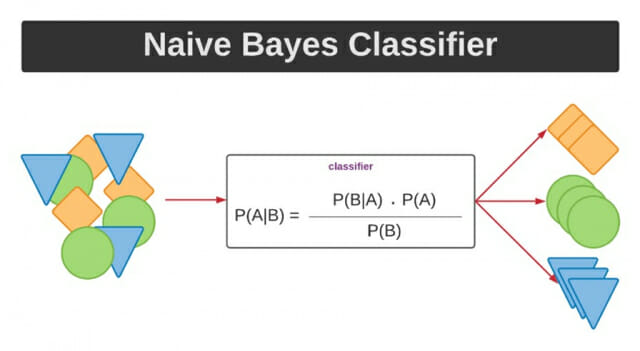
이렇게 정리를 한 상태에서 복잡하게 섞여 있는 문제를 비슷한 성격을 가진 특성(feature)으로 분류하는 것이다.
이 알고리즘을 사용하는 가장 대표적인 예는 넷플릭스에서 비슷한 성향을 보인 사람들에게 영화를 추천해줄 때 사용한다.
특정한 영화를 보고 A라는 사람이 좋아요를 누르고, B라는 사람도 좋아요를 눌렀다면 A와 B는 비슷한 성향을 가진 사람이라고 일차적으로 볼 수 있다. 하지만 다른 영화를 보고는 서로 다른 결론들을 보였다면, 복잡해진다.
확률적으로 A와 B가 좋아한다고 표현한 영화들, 별로라고 표현한 영화들의 데이터와 단순 영화 리스트뿐 아니라, 그 영화들에 출연한 배우들, 영화 장르, 스타일 등의 다양한 분석 데이터들을 감안하게 되면, 각각 A라는 사람과 B라는 사람이 특정 영화를 좋아할 만한 확률을 구하는 것은 매우 복잡한 다차원의 문제가 된다.
이것을 나이브 베이즈 분류기 알고리즘을 써서 각각의 영화, 배우, 장르, 스타일 등의 각 요소들에 대해 A, B 뿐 아니라 수많은 사람들이 지속적인 좋아할 확률값을 계산하고, 비슷한 성향의 사람들을 분류한다.
결론적으로 새로운 C라는 사람이 넷플릭스에 가입해 새로운 영화를 추천 받을 때, 기존에 가장 가까운 성향을 보이는 사람에게 좋은 평가를 받았던 영화를 제공하면 성공할 확률이 가장 높을 것이란 계산이 나온다.
이러한 방식으로 콘텐츠나 상품추천에 쓰이거나 기타 이메일 스팸 분류, 보안 분야에서의 이상징후 탐지, 암이나 심장병 등 의학데이터를 통한 질병진단, 문서 분류 등에 아주 다양하게 쓰인다.
세번째는 선형회귀(Linear Regression)이다. 이 알고리즘은 어쩌면 인공지능의 영역이라고 불리기 훨씬 전부터 전통적인 통계를 통한 알고리즘으로 이미 널리 사용되었다. 한국어로 번역하면, 선형회귀분석이라고 불리는데 이것은 우리가 중학교때부터 배우던 1차 방정식 y= aX + b를 학습을 통해 구현해 내는 것이라고 이해하면 된다.
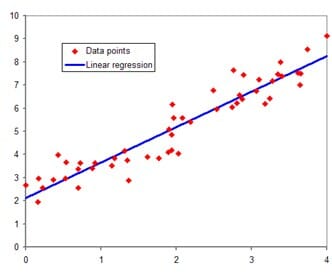
그림 2.에서 보듯이 X축과 Y축에 정해진 데이터 포인트들이 있고, 이 것들의 값을 학습하여, 새로운 input X나 Y가 들어왔을 때, 추정된 선형회귀 선과 가장 가까운 근사치 값으로 결론을 낸다. 이 알고리즘은 다양한 예측 모델에 활용되는데, 주가예측, 주택가격 예측, 날씨분석 및 예측, 판매 및 수요예측 등 다양한 업종에서의 예측에 활용된다.
주식가격에 영향을 미치는 다양한 데이터들, 즉 과거의 특정 주식가격 추이, 주가지수 추이, 경제지표 추이, 금리 및 해외주식 동향 등의 다양한 데이터들을 넣고, 특정 주식가격을 위한 회귀 분석을 해놓고, 최근의 데이터를 입력했을 때 어떻게 주식값이 될 것인가를 예측할 수 있다.
유통에서도 이 분석이 가장 많이 쓰인다. 어떤 프로모션이나 가격할인 등을 했을 때 과거 2년치의 판매데이터를 가지고 선형회귀를 했을 때, 이번의 가격이나 행사 때 얼마나 판매가 일어날 지 예측값을 얻을 수 있다.
마찬가지로 특정 매장의 특정 상품의 정확한 수요예측을 통한 발주 정확도를 높이기 위해 과거 2~3년치의 판매데이터, 날씨데이터, 행사데이터, 경제지표 및 경쟁사 데이터 등을 넣고 분석하여 오늘 혹은 이번주에는 얼마나 발주해야 하는지를 알 수가 있다.
네번째는 로지스틱 회귀(Logistic Regression)다. 이 알고리즘은 위에서 설명한 선형회귀와 연관된 사촌지간이라고 이해하면 쉽다.
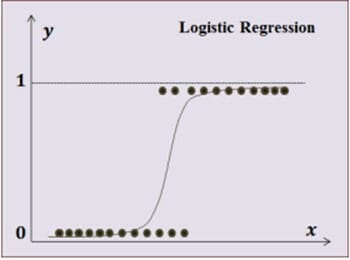
선형회귀는 예측값을 제공할 때 연속성의 값으로 제공하는 반면 로지스틱 회귀는 0이냐 1이냐의 값으로만 예측한다. 어떠한 의사결정을 할 수 있는 이분법적인 값으로 회귀하는 것이다.
그림 5에서 보는 바와 같이 X 축의 값의 변화에 따라 그림 4의 선형회귀에서는 다양한 Y값을 가지면서 선형의 연속값을 가지는데 비해 로지스틱회귀 Y값은 0 아니면 1이다. 이러한 값을 가지게 하기위한 시그모이드 함수라는 것으로 X값을 처리하여 특정값 이상이 되면 무조건 0이나 1로만 가지도록 데이터를 만들어 준다.
학습의 방법이나 데이터를 처리하는 방식 등은 선형회귀와 유사하나 그 복잡도는 커진다.
예를 들면 앞의 주가 예측의 예에서 선형회귀는 연속성의 값으로 이번의 특정 주가가 얼마나 될 것인가에 대한 예측값을 준다면, 로지스틱 회귀에서는 주가예측이 아니라 이 주식을 살 것인가 아닌가, 팔 것인가 아닌가 하는 의사결정의 방향을 제시한다.
과거에 팔았을 때의 성공이나 실패여부 등의 데이터들을 가지고 학습을 하여, 이 번에도 팔아야 할지 사야 할지 등의 의사결정의 데이터를 제공한다. 제조업에서도 많이 활용된다. 제품 품질의 불량 여부를 판단하는데 쓰인다. 품질을 판단하는데 참고하는 다양한 데이터들과 과거의 품질 불량판정 데이터를 가지고 학습을 하면 불량인지 아닌지 이분법적으로 결론을 제공해준다.
공장 현장에서는 불량일 확률이 몇 %이다라는 데이터는 큰 의미가 없다. 명확히 불량여부의 답을 내어주어야 하는 것이다. 이외에도 유통의 CRM 활동에서도 고객의 구매 확률보다는 명확한 구매 여부를 가지고 학습 및 데이터 결론을 내어주어야 할 때도 로지스틱 회귀가 많이 쓰인다.
관련기사
- [기고] AI 기본 이해하기2022.05.30
- [기고] AI의 기본 쉽게 이해하기 2-12022.06.13
- [기고] AI의 기본 쉽게 이해하기 2-22022.06.27
- [기고] AI 쉽게 이해하기 3-1. 기계학습 알고리즘2022.07.11
이번 글에서 14가지의 인공지능 알고리즘 중에서 먼저 가장 기본이 되는 4가지의 기계학습 알고리즘의 개념과 활용예시에 대해 알아보았다.
물론 이 정도 설명해서는 깊고 복잡한 알고리즘들을 이해할 수는 없겠지만, 멀게만 느껴지던 인공지능 알고리즘이라는 것에 대해 첫 발자국을 띠는 계기가 되었으면 하는 마음이다. 앞으로 몇차례에 걸쳐 남은 머신러닝과 딥러닝 알고리즘의 개념 및 활용에 대해서 공부해보고자 한다.
*본 칼럼 내용은 본지 편집방향과 다를 수 있습니다.






