



인공지능 챗봇 이루다 개발사인 스캐터랩이 누구나 접근할 수 있는 오픈소스 프로젝트 저장소에 자사 서비스 연애의과학에서 추출한 100여 건의 이용자 대화 데이터를 개인정보 비식별조치하지 않은 상태로 공개해 놨다가 최근 삭제한 것으로 확인됐다. 연애의과학에서 획득한 데이터를 이용자의 충분한 동의 없이 다른 용도로 사용한데다가 개인정보까지 고스란히 노출한 것이다.
13일 관련 업계에 따르면 스캐터랩은 2019년 소스코드 저장소 깃허브에 자사가 구현한 '문장 생성 모듈(KG-CVAE 기반)' 프로젝트를 오픈소스로 공개했다.
문장 생성 모듈은 컴퓨터가 자연어를 처리해 질문에 대한 답변을 만들어 내는 데 쓰인다. 이루다 같은 AI 기반 챗봇이 대표적인 활용처다.

이 프로젝트는 스캐터랩이 기존 관련 연구결과를 바탕으로 한국어 등의 훈련을 추가하고 재구현해 누구나 활용할 수 있도록 공개한 것이다.
문제는 해당 프로젝트에 모델 훈련에 필요한 데이터셋으로 '연애의과학'에서 추출된 데이터가 비식별조치 조차 거치지 않고 함께 공개됐다는 점이다. 연애의과학은 연인 간 카카오톡 대화를 기반으로 애정도를 분석해주는 유료 서비스다.
이 같은 문제 제기는 페이스북 텐서플로우 한국커뮤니티에서 한 연구자가 최초로 제기했다. 현재 해당 프로젝트 리포지토리는 깃허브에서 삭제된 상태다.

스캐터랩은 해당 프로젝트 소개글(리드미)에서 데이터셋 출처에 대해 "한국어의 경우, 연애의 과학에서 추출된 대화 데이터를 활용하였습니다"고 명시했다.
연애의과학에서 획득한 이용자들의 대화 데이터를 프로젝트에 충분한 동의 없이 사용한 것 자체도 문제지만, 대화 내용 중 개인정보가 그대로 노출됐다는 점에서 문제의 심각성이 크다.
본지가 데이터셋 일부를 직접 확인한 결과 실제 "나는 볶음밥~XX도 밥 빨리먹어ㅎㅎ" 같이 실명이 그대로 노출된 사례가 확인됐다.
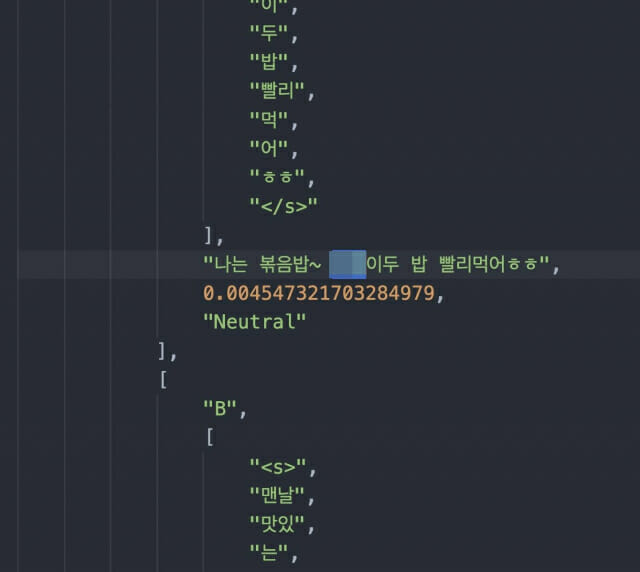
이 문제를 제기한 연구자는 "100개의 데이터 셋에서 필터링되지 않은 실명이 20여 번 노출됐다"고 지적했다. 또 "실명뿐 아니라 지역명, 질병 정보 등도 확인됐다"고 이 연구자는 강조했다.
스캐터랩은 챗봇 이루다 학습에 연애의과학 사용자 데이터를 활용하면서 개인정보 비식별화조치를 제대로 하지 않았다는 지적을 받은 바 있다. 이는 이루다가 사용자들과 대화 중 실명, 실제 주소로 보이는 정보를 얘기하면서 문제화 됐다.
이 같은 문제가 제기되자 스캐터랩 측은 "1억 건의 개별 문장을 사람이 일일이 검수하기는 어렵기 때문에 알고리즘을 통한 기계적인 필터링을 거쳤고, 이 과정에서 되도록 많은 변수를 주려고 노력했으나 문맥에 따라 인물의 이름이 남아 있다거나 하는 부분들이 발생했다”고 해명한 바 있다.
관련기사
- AI봇 이루다 개발사 "사람 실명 언급은 필터링 부족"2021.01.12
- 개인정보보호위, AI봇 '이루다' 개인정보 유출 조사 착수2021.01.12
- AI 챗봇 '이루다' 잠정 중단…"카톡 대화 활용 고지 안해 죄송"2021.01.11
- 한국인공지능윤리협회 "이루다 재 출시 해야"2021.01.11
하지만, 이번 프로젝트에서 스캐터랩은 단지 100건의 데이터셋에 대해서도 개인정보 비식별화 조치를 하지 않았다. 스캐터랩 측이 개인정보 보호 문제에 상당히 안일한 태도를 가지고 사업을 진행했음을 드러냈다고 할 수 있다.
스캐터랩 측은 이 사안에 대해 문의하자 공식 입장을 준비 중이라고 말했다.





