






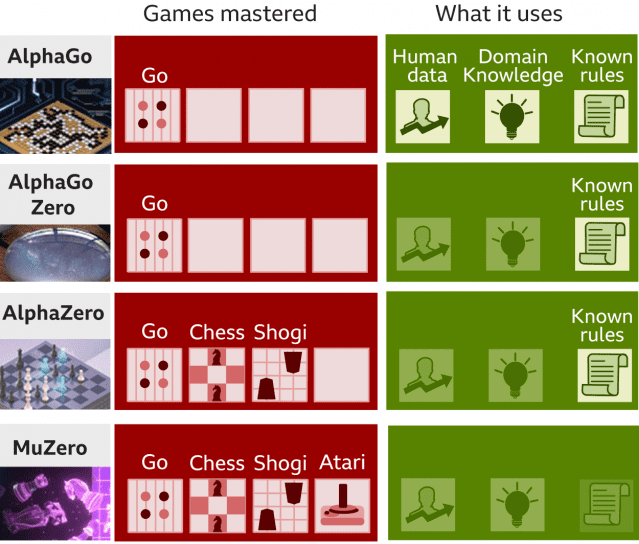
딥마인드가 알파고(AlphaGo), 알파고제로(AlphaGo Zero), 알파제로(AlphaZero)에 이어 '뮤제로(MuZero)'라는 또 다른 걸출한 인공지능(AI) 알고리즘을 세상에 내놨다.
인공지능(AI)의 한 분야인 강화학습 발전에 신기원을 이뤘고, 범용AI(일반지능AI)에 한발 더 다가섰다는 평가다. 특히 '뮤제로'는 이전 알파고들과 달리 게임 규칙을 모르는 상태(사전에 규칙을 알려주지 않은)에서 강화학습을 사용해 바둑과 체스, 쇼기(일본 장기)를 정복(마스터)했을 뿐 아니라 한발 더 나아가 알파제로가 하지 못한 아타리게임까지 마스터했다. '뮤(Mu)는 라틴어로 산이라는 뜻이다. '뮤제로'가 또 하나의 산을 넘었다는 의미로 보인다. BBC 등 외신에 따르면 딥마인드는 '뮤제로'를 지난 23일(현지시각) 국제학술지 ‘네이처’에 발표했다.
■뮤제로는 어떤 AI?
'뮤제로'는 딥마인드가 작년말 예비 논문에 처음 소개했고, 이번에 네이처에 전격 공개했다. 이전 알파고들과 달리 규칙이 주어지지 않았는데도(without rule) 바둑, 체스 쇼기는 물론 아타리 비디오 게임까지 정복(마스터)했다. 규칙이 없는 상태에서도 이전 알파고들 보다 나은 성과를 낸 것이다.
이전 알파고들은 바둑, 체스, 쇼기에서 사람을 이기는 놀라운 성과를 냈지만 모두 규칙을 줬었다. 반면 '뮤제로'는 사전에 게임 규칙을 입력해주지 않았음에도 바둑, 체스, 쇼기에서 보여줬던 알파고제로의 능력은 물론 알파고제로가 보여주지 못한 아타리 게임까지 정복했다.
경희대 이경전 교수는 "지난번 알파제로는 보드게임에만 적용된 건데 뮤제로는 복잡한 2D 그래픽이 있는 게임에서 57개 아타리 게임을 다 할 수 있는 학습 방법을 찾았다"면서 "어떤 문제를 해결하는 지능을 개발하려 할때 그 문제의 규칙(도메인 지식)을 몰라도 학습할 가능성을 보여줬다는 점에서 의미가 크다"고 설명했다. 이어 이 교수는 "뮤제로는 해상도가 96*96 정도인 2차원 게임 아타리 57개를 포함해 총 60종 게임을 정복했다"면서 "딥마인드 성과가 놀랍다"고 덧붙였다.
'뮤제로'에 대해 답마인드는 "알려지지 않은 환경(규칙을 제시하지 않은 환경)에서도 이기는 전략을 기획(planning)할 수 있는 능력을 갖췄다"고 설명했다. '뮤제로'를 개발한 이유에 대해 딥마인드 수석연구과학자 데이비드 실버(David Silve)는 BBC와의 인터뷰에서 "실제 사람 세계는 매우 복잡하고 혼란스럽다. 어떻게 돌아가는 지 누구도 룰북(rulebook)을 주지 않는다. 그럼에도 사람은 다음에 무얼 해야 할지 플랜과 전략을 세울 수 있다"고 설명했다. 즉, 사람처럼 규칙 없이도 플랜과 전략을 세울 수 있게 '뮤제로'를 개발했다는 것이다.
실버는 "세계가 어떻게 돌아가는 지 이해하는 걸 스스로 구축할 수 있고, 이 이해를 미리보기 기획에 적용한 시스템을 처음으로 개발했다"면서 "뮤제로는 무에서 출발했지만 시행착오를 거쳐 세상의 규칙은 물론 슈퍼맨과 같은 성능을 낼 수 있는 규칙들을 동시에 발견했다"고 강조했다.
'뮤제로'의 독특성은 학습 방법에 있다. 기존 AI처럼 모든 환경을 학습하지 않는다. 대신 환경의 가장 중요한 것만 학습한다. 이것을 가능케 하는 것이 플래닝이고, '뮤제로'는 이 플래닝 때문에 비범한 능력을 갖췄다. 이를 딥마인드는 이렇게 설명했다. 사람은 보통 먹구름이 몰려오면 비가 올까봐 우산을 갖고 가는데 이것이 플래닝이고 플래닝은 인간 지성의 중요한 부분으로 "우리 AI도 이런 플래닝 능력을 갖길 원했다"고 설명했다.
딥마인드는 이 모델을 '알파제로'가 갖고 있던 미리보기(lookahead) 트리 서치와 결합해 '뮤제로'라는 새로운 명물을 만들어 냈다. 보통 인공지능 연구자들은 문제를 해결하는 데 두 전략을 사용한다. 하나는 게임 규칙이나 지식에 기반한 의사결정 트리 검색, 즉 미리보기 검색이고 다른 하나는 모델 기반 학습이다. 게임 환경을 정확하게 모델링한 뒤 이를 기반으로 전략을 짜서 문제를 해결하는 방법이다. 하지만 가능한 모든 요소들을 모델에 넣으려면 매우 복잡한 계산이 필요하다. 특히 시각적 요소가 많은 비디오 게임은 이런 방식이 불가능하다. 이를 해결하기 위해 '뮤제로'는 게임의 전체 환경을 모델링하는 대신 각 의사결정 단계에서 가장 중요한 것만 모델링하는 방식을 취했다.
즉, 이전 인공지능에 비해 데이터를 매우 경제적으로 사용했다. 딥마인드는 "미즈 팩맨(Ms. Pac-Man) 같은 아타리 비디오 게임에서 '뮤제로'는 하나의 무브당 6~7가지 경우의 수밖에 고려하지 못하는 경우에도 게임을 훌륭히 치러냈다"고 설명했다. 훈련량이 많지 않았음에도 좋은 결과를 낸 것이다. 딥마인드는 아타리 게임을 훈련하는 데 단일 GPU로 2~3주 걸렸다고 말했다. 각 의사결정 단계에서 중요한 측면만 고려했기 때문이다.
실제, 그동안은 환경의 모든 면을 모델링하는 복잡성 때문에 아타리 같은 동영상이 풍부한 도메인과는 경쟁할 수 없었고, 현재까지 아타리와 경쟁한 가장 좋은 결과는 DQN, R2D2, 에이전트57 같은 모델프리시스템이다. 이들 모델프리시스템은 이름처럼 학습 모델을 사용하지 않고 대신 다음에 취할 가장 나은(베스트) 행동을 추정할 뿐이다.
■어디에 사용하나...동영상 압축 등에 유용
이전 알파제로는 화학, 양자물리학 등에 미적용되고 있다. 딥마인드는 "뮤제로의 파워풀한 러닝과 플래닝 알고리즘은 로보틱스, 산업 시스템, 게임의 룰이 알려지지 않은 다른 복잡한 현실 환경 문제를 해결하는데 신기원을 열 것"이라고 설명했다.
특히 딥마인드는 유튜브의 동영상 압축에 뮤제로를 적용하는 방법을 꾀하고 있다. 동영상 압축 효율을 높이면 유튜브 운영에 들어가는 비용을 줄일 수 있기 때문이다. 뮤제로는 지난해 11월 외부에 처음 공개됐는데 이후 미 공군이 뮤제로의 공개 버전을 응용해 적군의 미사일 발사체를 찾아내는 인공지능 알고리즘(ARTUMu)을 개발하기도 했다. 이 때문에 일각에서는 '뮤제로'의 악용 가능성에 대한 우려도 나왔다. 컴퓨터 과학자와 무기 전문가, 인권 단체들이 참여한 단체인 '스톱 킬러 로봇(Stop Killer Robots)'이 대표적인데 이 단체는 'ARTUMu'에 대해 "미 공군이 치명적인 자동 무기를 만드는데 한발 더 나아갔다"고 지적했다.
한편 딥마인드는 2016년 3월 이세돌과 바둑 대결로 '알파고'를 세계에 알린데 이어 2017년 10월 네이처(Nature)에 '알파고 제로'를, 1년 뒤인 2018년 12월 과학 학술지 '사이언스'에 '알파 제로'를 각각 공개했다.
'알파고'는 중앙처리장치(CPU) 1202개, 그래픽처리장치(GPU) 176개를 탑재했고, 1000대의 서버를 활용한 시스템으로 구성됐다. CPU 한 대당 1초에 1000회 이상 시뮬레이션이 가능하고, 인간의 뇌를 본뜬 인공 신경망인 정책망(policy network)과 가치망(value network)을 결합해 바둑돌을 놓을 위치를 결정했다. 정책망은 다음 바둑돌을 어디에 둘지 결정하는 알고리즘이고, 가치망은 착점이 놓인 후 승리 가능성을 예측하는 알고리즘이다.
관련기사
- '알파고' 딥마인드, AI로 단백질 비밀도 풀었다2020.12.01
- [김익현의 미디어 읽기] 알파고 4년…AI에 봄이 오는 신호였다2020.01.29
- 알파고 쇼크 4년...AI강국으로 선진국가 도약해야2020.01.03
- 삼성·SK, 서남권 반도체 등에 895조원 투자…정부 "파격 지원" 약속2026.06.30
'알파고 제로'는 알파고와 달리 독학으로 지식을 습득한 인공지능(AI)이다. 바둑 규칙 이외에 아무 사전 지식이 없는 상태에서 인공신경망 기술을 활용해 스스로 대국하며 바둑 이치를 터득했다. 기보를 학습하지 않고도 알파고(AlphaGo)를 상대로 전승을 거뒀다.
'알파제로'는 바둑에 이어 체스, 쇼기(일본 장기)도 스스로 독파한 인공지능이다. 알파고 제로의 일종의 범용 버전이다. 명칭에서도 바둑을 뜻하는 고(GO)를 뺐다. 규칙만 알면 모든 보드게임을 익힐 수 있어 바둑에 특화된 알파고를 압도했다. 알파제로는 2016년 체스 AI 챔피언 스톡피시를 4시간 만에, 2017년 쇼기 AI 챔피언 엘모를 2시간 만에 꺾었다. 스톡피시와 엘모는 입력된 빅데이터를 기반으로 최적의 수를 검색하는 반면, 알파 제로는 인간의 두뇌처럼 심층신경망 기술을 통해 데이터를 스스로 학습하고 승률을 높이는 좋은 수를 찾아냈다.





