






이세돌 9단이 알파고에게 패한 뒤 바둑계, 처음엔 정말 패닉이었다. 무려 '바둑의 신' 운운하며 공포에 시달렸다. 조바심에 떠밀려 인공지능(AI)이 펼치는, 뭔지 제대로 파악도 못한 신수신형을 열심히 따라하기도 했지만, 정작 AI의 무기인 살벌한 형세 판단과 수읽기 역량은 없으니 '뒤가 없는' 속수가 난무한 시기도 있었다. 하지만 이젠 거의 안정된 듯하다. AI 바둑 연구도 꽤 깊어져 인간은 기계 아닌 인간으로서 포기할 지점이 어딘지 조금은 알게 된 듯도 하다.
AI 덕분에, 초일류와 초격차 개념은 옅어져 평준화된 일류들이 호각을 다툰다. 자타공인 초일류인 중국의 커제마저 '힘들어졌다'고 말한다. '누구의 치세'라며 1인자를 영웅시하는 관전 재미는 흐릿해졌지만, 완전한 난전을 보는 다른 재미가 생겼다. 게임의 성질이 달라졌을 뿐 바둑은 여전히 아주 재밌는 그리고 훌륭한 게임이다. 바둑과 함께 최고의 추상전략 게임 양대산맥 중 하나인 체스는 이미 옛날에 겪은 일이다. 그럼에도 체스는 여전히 아주 훌륭한 지적 유희이며 여전히 아주 많은 사람들이 즐긴다. 기계와 더불어 산다는 게 뭐 그리 깜짝 놀랄 일은 아닌 것이다.
그렇게 AI와 머신러닝이라는 도구는 우리 일상 가까이 다가왔다. 충격이 컸지만 도구는 도구일 뿐, 잘 쓰면 될 일이다. 오늘은 보안을 위해 쓸 방법에 대해 알아보자. 보안 이야기지만 거의 일반론이므로 분야 가리지 않고 적용할 만한 영감을 얻을 수 있으리라 기대한다.
■ 보안이란
보안은 정상과 비정상을 구별하는 일이다. '정상'은 안전한 선의의 접근과 이용 즉 '화이트'다. '비정상'은 위험한 악의적 침입과 악용 즉 '블랙'이다. 이를 구별하기 위해 보안전문가는 전문가적 직관으로 '비정상이란 무엇인가' 특징을 정의한다. 다시 말해 정상이란 '비정상이 아닌 것'이다.
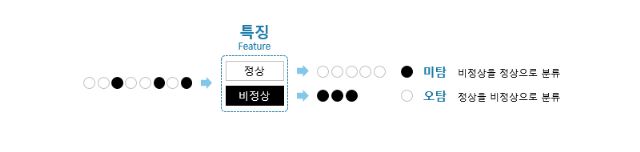
직관이라 해도 오직 감각에 의존하는 건 물론 아니고 근거는 있다. IBM X-Force, Abuse IP DB 등의 평판 자료와 애플리케이션 문법 오류 및 허점 분석 자료 그리고 이상행동 등을 연구한 결과다. 지나치게 넓은 범위 접근을 시도할수록, 영업일과 업무시간 등 접근 시간대가 불분명하고 불규칙할수록, 접근 시도 폭증 등 행동의 강도가 급증할수록 이상행동, 비정상일 가능성이 높다고 판단한다. 그 모두를 종합해 "비정상은 이렇다, 이렇다, 이렇다, ..." 식으로 특징(Feature)를 정의하고 그 특징에 해당하는 것들을 비정상으로 분류한다.
그러나 문제는, 이쯤은 해커들도 다 안다는 사실이다. 해커란 것은 보안전문가의 거울 이미지라, 그들도 웬만한 비정상의 특징쯤은 다 알고 있다. 보안 프로그램의 가장 열정적 사용자가 해커라는 말도 농담이 아니다. 어차피 다 걸려들 시도를 하는 건 바보짓 그리고 낭비니까 이것저것 다 돌려 본 뒤 침입을 시도한다. 그리고 보안전문가라고 늘 완벽할 수는 없으니 보안 실패는 늘 발생한다. 비정상을 정상으로 분류한 '미탐'과 정상을 비정상으로 분류한 '오탐'을 줄이기 위한 끊임없는 노력일 뿐이다. 결국 보안이란 미탐과 오탐을 최소화하는 최선의 특징을 정의하는 일이다. 아주 치열한 공방전이다.
■ 보안의 (인간적) 한계
그렇잖아도 아주 힘들었던 일이 더 힘들어졌다. 먼저, 데이터 양이 너무 많아졌다. 분류를 위해 특징을 분석하는 일도 그렇게 추출한 특징으로 정상/비정상을 분류하는 일도 힘들어졌다. 기존과 형태가 아예 다른 비정형 데이터가 많아짐에 따라 기존 정형적 방법론이 무색해지기도 했다. 양도 많고 교묘히 변화한 변종들도 많아져 보안은 점점 더 어려워지고 있다. 인력의 한계에 이르렀다 해도 과언이 아닐 지경이다.
그런데, 너무 비정상에만 집중하는 것 아닌가 근본적 의문도 든다. 정상의 정의를 '비정상이 아닌 것'이라 하니, 그 비정상의 양상이 복잡해질수록 구별이 어려워지는 건 당연한 일이다. 그렇다면 발상을 바꿔, 정상의 특징을 찾아내고 비정상의 정의를 '정상이 아닌 것'이라 하면 되지 않을까. 비정상이 얼마나 교묘히 모습을 바꾸고 정체를 감춰 정상인 척 침입을 시도하더라도 그건 어쨌든 정상은 아닐 테니까. 앞뒤 순서만 바꾼 말장난 같지만 이는 상당히 보안의 핵심에 근접한 의문일 수도 있다. 확실히 이상한 비정상에 비해 딱히 정상의 특징이란 걸 찾는 일이 어려웠을 뿐.
특징 추출과 정상/비정상 분류에 있어 인력의 한계, 정상의 특징 분석의 어려움, 그 두 가지가 머신러닝에 대해 기대할 만한 기계의 역할이다. 이에 대해 살펴보자. 주의할 점은, 아래 내용은 상식적 이해를 위해 추상화, 일반화한 것이라 기술적 엄격성은 낮다. 기술적 이해를 바란다면 다른 자료를 찾아볼 일이다. 다행히 아주 많다.
■ 분류와 군집
보안에 유용한 머신러닝의 기능은 '분류(Classification)'와 '군집(Clustering)' 두 가지다.
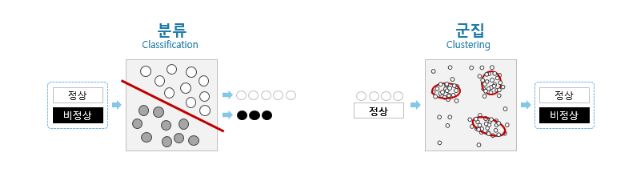
분류란 학습 전에 교육한 군집별 특징 정의에 따라 데이터를 학습하고 이후 입력되는 데이터에 대해 그 소속을 예측하는 일이다. 데이터 항목화에 최적화된 일이라 보안에 적용한다면 정상/비정상 구별에 용이해 멀웨어 식별과 스팸 탐지 등의 일에 적합하다. 하지만 학습 전에 정상/비정상 특징을 교육하는 '교사학습(Supervised learning)'인 까닭에 가르치지 않은 그리고 아직 알려지지 않은 이상행동에 대응이 어려워 기존 업무의 자동화 정도로 그치고 만다.
군집은 유사 데이터의 특징을 분석해 데이터를 복수의 배타적 군집으로 분류하는 일로서, 로그 데이터 등 데이터 분석에 적합하다. 하지만 학습 전에 가치와 정오를 판단하는 기준을 가르치지 않는 '비교사학습(Unsupervised learning)'이기 때문에 스스로 분석한 특징에 따라 군집을 나눌 뿐 정상/비정상 구별 작업에는 미흡하다. 응용한다면 분류를 위한 군집의 특징을 추출할 수 있는 가능성은 있지만 아직까지 실용화 단계의 연구는 없었다.
■ 교사학습과 비교사학습
그럼 '군집'을 통해 추출한 특징으로 '분류'를 하면 끝날 일 아닌가. 가능한 일이다. 구체적 방법론 모색에 앞서 중요한 차이점인 교사학습과 비교사학습에 대해 알아보자.
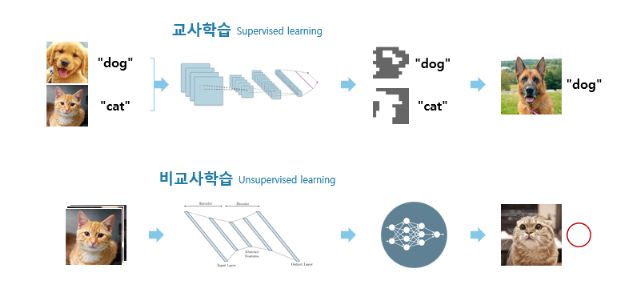
'교사학습'은 분류하려는 각 데이터 군집의 특징 정답(Label data)을 지도한 후에 학습을 시킨다. 위 그림을 보면, "이건 개" "이건 고양이" 특징을 지도한 뒤 각각의 차이를 학습하고 이후 입력되는 데이터를 개와 고양이로 분류하는 일을 한다. 보안에 적용한다면 정상/비정상 분류에 적합하고 그 결과의 정오 판정은 용이하겠지만, 학습 전에 정상/비정상 특징을 지도해야 한다는 점이 크게 아쉽다.
'비교사학습'은 유사한 데이터를 계속 학습함으로써 해당 데이터 군집의 공통된 특징을 도출하는 일이다. 위 그림을 보면, 고양이 데이터를 반복 학습해 고양이의 공통된 특징을 도출하고 이후 입력된 데이터가 고양이 군집에 속하는지 여부를 판단한다. 학습 전 지도 없이도 군집의 특징을 추출한다는 점에서 보안의 정상/비정상 특징 정의를 자동화할 가능성이 있다고 볼 수 있다.
그런데 기계는 어떻게 어떤 군집의 특징을 찾는 걸까.
■ 기계가 추출하는 특징
비교사학습으로 데이터 군집의 특징을 추출하는 일을 수행하는 신경망 '오토인코더(Autoencoder)'의 예를 통해 알아보자.
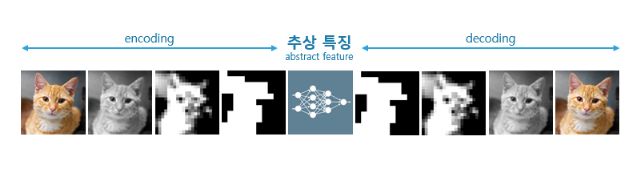
오토인코더는 어떤 이미지의 특징을 유지한 채 추상화하며 축소한다. 이를 다시 확장했을 때도 원 이미지 복구가 가능하도록 최적의 '특징 표현(Abstract feature)'을 찾는다. 특징 유지 없이 그냥 축소만 한다면 확장했을 때 완전히 다른 이미지가 되고 말겠지만 특징에 따라 축소하기 때문에 다시 확장하더라도 원래 이미지의 특징이 유지된다.
그리고 계속해서 같은 '고양이' 군집에 속하는 여러 이미지를 학습, 즉 인코딩과 디코딩을 반복해 고양이에 대한 특징 정의를 계속 교정하면서 "고양이는 이렇다, 이렇다, 이렇다, ..." 식의 추상 특징 정확도를 점차 높인다. 충분한 학습을 마치고 나면 '고양이란 무엇인가' 질문에 대한 거의 확실한 기계 나름의 대답을 갖게 된다.
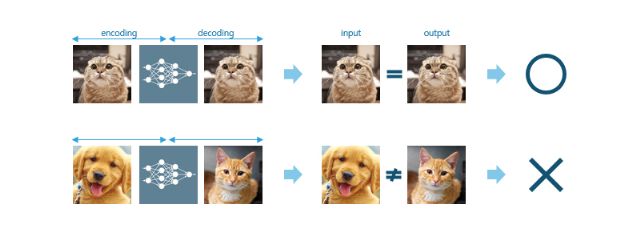
이후에 '고양이'에 해당하는 이미지를 입력하면 이는 고양이의 특징에 부합하므로 축소하고 확장한 뒤에도 원본 이미지가 유지된다. 즉, "이것은 고양이다"란 뜻이다. 반면 고양이가 아닌 이미지를 입력하더라도 이미 학습한 '고양이'의 특징에 따라 축소하고 확장해버리므로 입력한 이미지와 출력된 이미지가 달라진다. 즉, "이것은 고양이가 아니다"란 뜻이다.
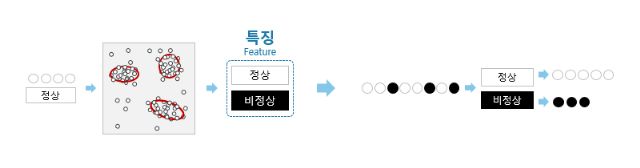
이러한 성질을 보안에 적용해 본다면, 정상 데이터를 반복 학습해 '정상' 군집의 공통된 특징을 추출할 수 있을 것이다. 그리고 그 특징에 따라 정상/비정상을 분류할 수도 있을 것이다.
■ 머신러닝과 보안
보안을 위한 최적의 머신러닝 방법은 비교사학습으로 도출한 특징으로 정상/비정상을 분류하는 일이다. 아주 간단해 보이지만 몇 가지 문제가 있다.
첫째, 머신러닝 특히 비교사학습은 이미지 분석엔 용이하지만 텍스트 분석이 어렵다. 텍스트 분석은 언어 사전(dictionary)의 학습과 전체 맥락(context) 분석이 필요하므로 기계적 이해에는 텍스트보다 사전과 맥락이 불필요한 이미지 분석이 용이한 것이다. 그런데 보안이 다루는 데이터는 거의 대부분이 텍스트다.
둘째, 교사학습을 이용한 정상/비정상 분류는 유용하지만 기계에게 가르칠 특징 도출이 어렵다. 앞서 보안의 인간적 한계에 해당하는 일이다. 인력으로는 감당을 못해서 기계를 쓰려는 건데 기계를 쓰려면 인력이 필요한, 모순이다. 따라서 데이터의 복잡도가 높아질수록 인간적 이해에 한정되는 교사학습은 한계에 이른다. 이때 비교사학습을 이용한 특징 도출이 해법이 될 수 있겠지만, 역시나 텍스트 분석의 어려움 때문에 활용이 제한된다.
셋째, 정상과 얼마나 달라야 비정상인가? 기준의 문제다. 이는 머신러닝 기술 외 전문가적 판단이 필요한 일이다. 머신러닝을 동원하더라도 보안전문가의 전문성은 여전히 필수적이다. 머신러닝 기술과 보안 기술이 적절한 지점에서 만나야 풀릴 일이다.
그러나 늘 그랬듯 문제는 해결된다.
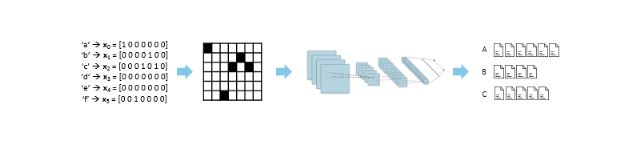
먼저 텍스트 분석 어려움의 문제. 2015년, 뉴욕대 얀 르쿤(Yann LeCun) 교수 연구팀은 텍스트 데이터의 알파벳을 이미지로 변환하고 교사학습 머신러닝으로 학습함으로써 문서를 서지학적으로 분류하는 일에 성공했다. 허무하다 싶을 정도로 간단해 보이기도 하지만 발상의 문제겠다. 그런데 보안의 대상인 HTTP 데이터도 텍스트, 그렇다면 유사한 방법으로 머신러닝을 이용할 수 있지 않을까.
2017년, 정보보안 전문기업 '펜타시큐리티'와 '클라우드브릭'은 공동으로 HTTP 트래픽을 이미지로 변환하고 교사학습 머신러닝으로 학습해 정상/비정상으로 분류하는 일에 성공했다. 위 첫째 문제가 해결되었다.
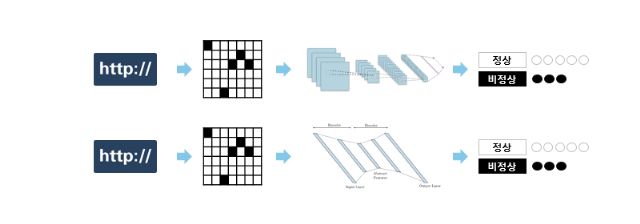
이어서 2018년에는 이미지로 변환한 HTTP 트래픽을 비교사학습 신경망 오토인코더를 이용해 정상 특징을 도출해 정상/비정상 분류하는 일에 성공했다. 위 둘째 문제도 해결되었다.
그리고 같은 해, 보안전문가로서 정상/비정상 기준을 수식화함으로써 셋째 '정상과 얼마나 달라야 비정상인가' 문제까지 모두 해결해 이 방법을 완전히 실용화했다.
관련기사
- 스마트 모빌리티와 미래사회2019.08.13
- 블록체인의 이해, 지갑의 오해2019.08.13
- '제로 트러스트'의 구체적 방법2019.08.13
- 5G의 위험과 불만…보안과 공정2019.08.13
비교실험 결과, 인간이 추출한 정상/비정상 특징을 적용한 탐지에 비해 오토인코더를 이용해 기계가 특징을 추출한 방식이 월등히 높은 보안 성공률과 효율을 보였다. 위 내용은 'IEEE (Institute of Electrical and Electronics Engineers)'에 등재된 'Anomaly Detection for HTTP Using Convolutional Autoencoders' 논문을 통해 확인할 수 있다.
안개가 걷히고, 길이 보인다.
*본 칼럼 내용은 본지 편집방향과 다를 수 있습니다.






