



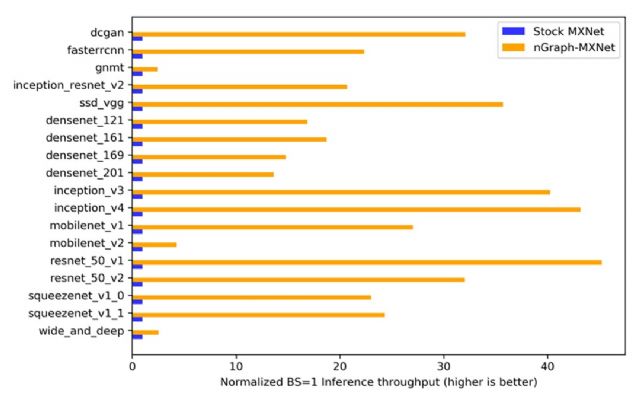
인텔이 하드웨어 업그레이드 없이 소프트웨어만으로 인공지능(AI) 딥러닝 효과를 높이기 위한 방안을 제시했다. 인텔이 공개한 바에 따르면 최대 45배 높은 효율을 보이는 것으로 나타났다.
인텔은 오라일리와 함께 미국 뉴욕에서 개최한 AI 컨퍼런스에서 엔그래프를 활용한 딥러닝을 지난 18일(현지시간) 발표했다.
인텔은 “최근 딥러닝의 급속한 성장으로 인해 고성능 교육 및 추론 솔루션에 대한 수요가 증가하면서 주요 하드웨어 제조사의 투자가 늘어나고 있다”며 “하지만 하드웨어만으로는 딥러닝 성능이 충분히 상상되는 것을 기대하기 어려워지면서 소프트웨어 영역에서 딥러닝 성능을 극대화하기 위해 새로운 수준의 딥러닝 학습 컴파일러가 등장하고 있다”며 엔그래프를 소개했다.
엔그래프는 딥러닝 시스템을 위한 인텔의 오픈소스 신경망 컴파일러다. 심층신경망(DNN) 모델을 다른 장치에서 효율적으로 학습하고 실행할 수 있으며 텐서플로, MX넷, 네온 등의 딥러닝 프레임 워크를 지원하며 인텔 아키텍처, GPU, NNP 등 하드웨어를 활용해 성능을 높일 수 있는 것이 장점이다.
인텔은 제온 스케일러블 프로세서에서 엔그래프와 MX넷(MXNet) 사용한 결과 그렇지 않은 시스템과 비교해 같은 하드웨어 상에서 정규화된 추론 처리량이 45배 늘어났다고 밝혔다.
엔그래프가 딥러닝에서 높은 효율을 보일 수 있었던 것은 여러 프레임 워크 및 대상 하드웨어 플랫폼에서 공유할 수 있는 그래프 수준 최적화를 지원하기 때문이다. 이를 통해 커널 라이브러리에서 발생하던 비효율적인 중복 연산을 최소화했다.
관련기사
- 이베이코리아, ‘앰플리파이’ 개발자 행사서 기술성과 공유2019.04.23
- 카카오, 산학협력으로 딥러닝 연구 41건 성과 거둬2019.04.23
- [기고] 딥러닝은 어떻게 똑똑한 마케팅에 기여할까2019.04.23
- "올해 세계 IT 시장 1.1% 성장…한국은 4%"2019.04.23
또한 설치된 하드웨어에 따라 칩 설계, 데이터 유형, 연산 및 매개 변수에 맞게 각 커널을 수정해야 하던 부담을 줄여 다양한 딥러닝 프레임 워크 및 CPU, GPU에 대한 높은 이식성과 유연성을 제공한다고 인텔 측은 설명했다.
다만 인텔 측은 이번 성능 테스트에 사용된 컴퓨터 시스템과 소프트웨어 및 작업 부하는 인텔 마이크로 프로세서에서만 성능을 위해 최적화되었을 수 있어 요인 중 하나라도 변경되면 결과가 달라질 수 있다고 주의 사항을 밝혔다.





