






IBM이 수백개 GPU를 연결한 분산 딥러닝 환경의 성능을 제대로 발휘할 수 있는 소프트웨어(SW)를 개발했다.
미국 지디넷은 지난 8일 IBM리서치가 GPU 수백개를 연결한 분산딥러닝 환경의 성능 효율을 이상적 수준에 가깝게 확장할 수 있는 SW를 개발하고 있다고 보도했다. [☞원문 바로가기]
연구소는 딥러닝 방법론의 난제를 풀고자 했다. 대규모 인공신경망과 대규모 데이터넷으로 딥러닝 방법론을 수행할수록 학습에 걸리는 시간이 늘어나는 게 문제였다. 규모에 따라선 딥러닝기반 인공지능(AI) 모델 학습이 며칠에서 몇주까지 걸릴 수 있다.

소요시간은 학습연산을 처리하는 컴퓨터의 성능을 높여 줄일 수 있긴 하다. 딥러닝의 주요 하드웨어인 GPU를 여러개 연결함으로써 대규모 분산컴퓨팅을 수행하면 이론적으로 학습시간을 적절히 끌어내릴 수 있다. 하지만 이론과 실제는 다른 법이다.
분산딥러닝 환경을 구성하더라도 기본적으로 개별 시스템의 GPU 성능이 높아야 한다. 그런데 개별 시스템의 GPU가 빠를수록, 분산딥러닝 환경에 연결된 GPU간의 통신효율이 떨어졌다. 그에 따라 전체 연산 성능이 충분히 나오지 않는 문제가 나타났다.
IBM 펠로 힐러리 헌터는 관련 블로그에 "기본적으로 더 똑똑하고 빠른 GPU일수록 더 좋은 통신 수단을 요구한다"며 "그렇지 않으면 그게 다른 GPU의 (연산) 결과를 기다리고 그와 동기화하는데 상당한 시간을 허비하게 된다"고 썼다. 이어 "더 빠른 GPU를 더 많이 쓰더라도 속도 향상이 없거나 오히려 쓸수록 성능이 떨어질 수도 있다"고 덧붙였다.
IBM이 개발한 새 분산딥러닝SW는 이 문제를 해결한 것으로 묘사됐다. 텐서플로, 카페, 토치, 체이너 등과 같은 대규모 인공신경망과 데이터셋 처리용 오픈소스 프레임워크를 사용하는 분산딥러닝 시스템이 더 나은 성능과 정확도를 얻도록 돕는다는 설명이다.
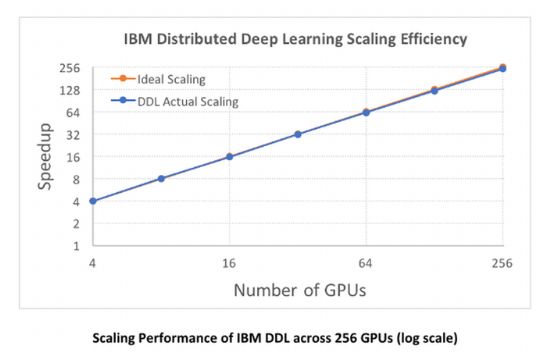
IBM리서치 측은 새 SW를 사용한 IBM 파워시스템 서버 64대에 장착된 GPU 256개 이상을 연결한 카페 프레임워크 기반 분산딥러닝 환경에서 통신 오버헤드를 측정한 결과 95% 가량의 성능확장 효율을 기록했다고 밝혔다. 이는 페이스북인공지능연구소(FAIR)가 앞서 카페2 기반 학습 과정에서 통신오버헤드를 측정한 결과 90% 가까운 성능확장 효율을 기록한 것보다도 나은 수준이다.
보도에 따르면 IBM리서치는 또 새 SW를 통해 이미지넷 데이터셋에서 가져온 750만장의 사진을 기반으로 인공신경망 학습을 수행했는데 7시간만에 이미지인식 정확도 33.8%를 달성했다. 앞서 마이크로소프트가 같은 데이터를 10일간 학습시켜 29.8% 정확도를 달성한 결과를 훨씬 뛰어넘는 수준이다. 1% 이내였던 기존 정확도 개선폭을 염두에 두면 4%포인트 향상은 '큰 도약'이라고 헌터는 강조했다.
관련기사
- ‘머신러닝-딥러닝’, 뭐가 다를까2017.08.10
- SAP "기업용 SW에 쉽게 AI 통합 가능"2017.08.10
- MS, 딥러닝 툴킷 새버전 오픈소스로 공개2017.08.10
- 가벼워진 '알파고'…구글 전용칩 1개로 작동2017.08.10
헌터는 이어 "대다수 딥러닝 프레임워크는 한 서버에 여러 GPU를 사용해 확장할뿐 GPU를 탑재한 여러 서버를 쓰지 않는다"면서 "우리 팀은 수십대 서버에 연결된 GPU 가속장치 수백개를 통한 크고 복잡한 컴퓨팅 작업의 병렬화를 자동화, 최적화하는 SW와 알고리즘을 만들었다"고 밝혔다.
IBM 전문가들은 이를 통해 향상된 딥러닝 학습 환경을 적용하면 다양한 AI 활용사례를 발전시킬 수 있을 것이라고 기대했다. 더 정확한 의료이미지분석이나 더 나은 음성언어인식 기술을 만들 수 있을 것이란 얘기다. IBM은 분산딥러닝SW 패키지 '파워AI' 버전 4를 통해 자신들의 새로운 SW 기술 시험판(technical preview)을 제공하고 있다.





