






사진기반 SNS 핀터레스트가 매일 20테라바이트씩 생산되는 사용자 데이터 처리 비법을 공개했다. 클라우드 기반의 서비스로 하둡을 활용하고 오픈소스 자동화도구인 퍼펫으로 불시의 장애에 대응하는 내용이다.
24일(현지시간) 미국 지디넷에 따르면, 핀터레스트는 공식 엔지니어링 블로그를 통해 자신들의 빅데이터 기술 활용법을 소개했다.
핀터레스트는 매일 20TB씩 새로운 데이터를 만들어내고 있으며, 현재 아마존웹서비스(AWS) S3에 저장된 전체 용량은 10페타바이트에 달한다.

핀터레스트의 핵심은 개인화된 게시판의 핀이란 콘텐츠다. 사용자가 웹 어딘가서 본 이미지를 스크랩하고, 게시하는데, 핀터레스트는 모든 사용자의 활동을 분석함으로써 관련된 핀을 추천하고, 검색결과를 개인화해 보여준다.
핀터레스트 엔지니어링팀은 하둡을 사용해 매일 생성되는 데이터를 적절히 저장하고 사용자에게 개인화된 콘텐츠를 노출하고 있다.
모하마드 샤한지안 핀터레스트 데이터엔지니어는 빅데이터 애플리케이션을 빠르게 구축하기 위해 우리는 싱글 클러스터 하둡 인프라를 유비쿼터스 셀프서비스 플랫폼으로 진화시켰다고 묘사했다.
그는 하둡은 강력한 저장 및 스토리지 시스템이지만 플러그앤드플레이 기술은 아니다고 밝힌 뒤 운좋게 많은 하둡 라이브러리와 애플리케이션 서비스 제공자들이 셀프서비스플랫폼로써 제한을 채워주는 솔루션을 제공한다라고 적었다.

사용자가 올리는 수많은 이미지 파일은 S3 상의 하둡파일시스템(HDFS)에 저장된다. 핀터레스트는 데이터 처리를 더 빠르게 하기 위해 맵리듀스를 컴퓨팅과 저장을 분리하는 수단으로 사용했다. 맵리듀스로 핀터레스트의 하둡 클러스터는 S3와 동기화될 수 있게 됐고, 아마존 클라우드에 저장된 모든 데이터를 한꺼번에 처리할 수 있게 됐다.
만약 하나의 HDFS 클러스터가 장애를 일으킨다고 해도 데이터는 아마존 S3에 유지되므로 손실되지 않으며, 전체 클러스터의 작업에 영향을 미치지 않는다.

이와 함께 메타데이터 관리는 하이브를 활용했다. 각 하둡 잡에서 오는 모든 데이터 카탈로그를 담는다. 하이브는 또한 유사 SQL언어를 지원해 엔지니어링 팀 내부에서 세부정보와 테이블을 목록화하게 도와줬다고 한다.
컨피규레이션 관리툴은 퍼펫랩스에서 개발하는 오픈소스툴 '퍼펫'을 사용했다. 이는 맘춤화된 시스템을 최적 상태로 유지하게끔 해줬다.
그는 퍼펫은 우리의 사례에서 중요한 제한을 갖는다며 우리가 새 노드를 프로덕션시스템에 추가하려 할 때, 동시에 퍼펫 마스터가 새 배열을 풀다운시키고 마스터노드를 압도해 장애 시나리오를 야기했다고 설명했다. 하둡에서 많이 언급되는 '싱글포인트오브페일류어(SPOF)다.
그는 SPOF를 위해 퍼펫 클라이언트를 마스터없이 만들었다'며 S3로부터 구성을 끌어와 퍼펫 마스터와 동기화된 S3 구성을 유지해주는 서비스를 설정한다고 설명했다.

하둡 잡 관리엔 서비스형 하둡(Hadoop as a Service) 스타트업인 큐볼(Qubole)을 활용했다. 아마존의 일래스틱맵리듀스(EMR)가 200노드 이상으로 급증할 때 성능에 문제가 생기기 때문이었다고 한다.
그는 큐볼은 하이브 창조에 도움을 줬던 두명의 전직 페이스북 엔지니어가 세운 회사라며 한 클러스터 안에서 수천노드를 수평으로 펼쳐도 문제가 없게 하며, EMR을 사용할 때보다 30~60% 스루풋 증가를 보여줬다고 밝혔다.
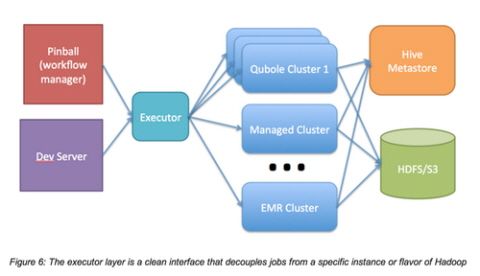
핀터레스트는 현재 3천노드 이상으로 구성된 6개의 하둡 클러스터를 운영하고 있다. 개발자들은 200억개 이상의 로그 메시지를 발생시키며 매일 하둡에서 수페타바이트를 처리하고 있다.
관련기사
- 구글, 하둡 맵리듀스 대체용 '데이터플로' 공개2014.07.25
- 클라우드 기반 하둡, 메가트렌드 되나2014.07.25
- 하둡 진영, 아마존 어깨에서 구글 노린다2014.07.25
- 하둡, 제대로 쓰고 싶으면 링크드인 보라2014.07.25
핀터레스트는 하둡2.0을 채택할 계획이다. 하둡2의 클러스터 리소스 관리 요소인 얀에 대한 필요성 때문이다.
핀터레스트의 전체 사용자 수는 알려지지 않은 상태. 다만, 샤한지안은 매일 300억건 이상의 핀이 사이트에 올라온다고 밝혔다.





