스플렁크는 지난달말 하둡분산파일시스템(HDFS)의 데이터를 쉽게 검색해 활용하게 해주는 기술 ‘헝크(Hunk)'의 베타버전을 공개했다. 개발과정이 까다롭다는 하둡조차 복잡한 과정을 없애주겠다는 상용소프트웨어의 야심이다.
장경운 스플렁크코리아 부장은 “헝크는 수집, 스키마 인덱싱 등의 DB 개발과정을 생략하고, 검색, 모니터링, 분석, 시각화까지 한번에 할 수 있는 스플렁크의 기본 성격을 하둡에도 적용하도록 한 것”이라며 “하둡 인덱싱이나, 커넥터 연결이 아닌 새로운 방식”이라고 설명했다.
헝크는 하둡에 저장된 데이터의 탐색, 분석 및 시각화 등을 지원하는 기능을 갖춘 독립 플랫폼이다. 시스템통합(SI)이나 강제적인 데이터 마이그레이션, 복잡한 프로그래밍 과정없이 하둡에 저장된 데이터와 상호 작용할 수 있는 기술이라고 회사 측은 설명했다.
헝크의 핵심은 스플렁크 버추얼 인덱스이란 기술이다. 스플렁크 서치 프로세싱 랭귀지(SPL)를 통해 데이터가 스플렁크 인덱스로 저장된 것처럼 저장된 위치에 상관없이 원하는 데이터를 검색할 수 있다.
장경운 부장은 “버추얼 인덱스는 데이터의 실제 존재 위치는 외부지만, 그를 마음대로 끌어다 조작하고 시각화해주는 추상적인 계층이다”라며 “하둡에 스플렁크 맵리듀스 라이브러리를 심어 데이터에 접속하는 통로를 열어주게 되며, 요청시 버추얼 인덱스로 바로 끄집어낸다”라고 말했다.
그는 “하둡은 많은 데이터를 저장할 수 있지만, 텍스트 테이블 기반이어서 시각화에선 부족하다”라며 “헝크는 시각화 테이블로 데이터를 보여주며, 검색한 하둡 내 데이터를 시각화하거나, 곧바로 대시보드로 구성해 활용할 수 있게 해준다”라고 강조했다.
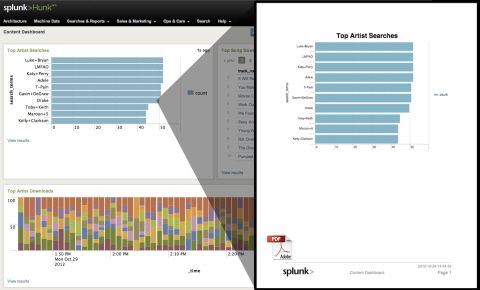
버추얼 인덱스를 통해 HDFS의 데이터를 바로 끄집어 내는 방식은 검색 시 스플렁크가 별도 맵리듀스 작업을 수행하는 형태다. 하둡은 사용자가 검색어를 던지면 맵리듀스 작업을 거쳐 보여주게 되는데, 헝크는 SPL로 맵리듀스 작업을 요청하는 것이다.
그는 하둡을 대화형 분석으로 활용하도록 해준다고 강조했다. 예외 항목을 찾아내고, 데이터를 상호 연계시켜 트렌드를 파악해 관련 패턴을 식별하는 작업이 대화형 분석으로 이뤄진다는 설명이다.
엔터프라이즈 앱 프레임워크를 통해 자바, 자바스크립트, 파이썬, PHP, C# 및 루비 등으로 작성된 API와 소프트웨어 개발자도구 등으로 여러 애플리케이션을 개발할 수 있다.
그동안 스플렁크가 하둡의 데이터를 연계하는 방식은 3종류였다. 하둡을 스플렁크의 백업 용도로 쓰는 방식, 커넥터를 통해 하둡 데이터를 인덱싱한 뒤 스플렁크로 가져와 처리하는 방식, 스플렁크를 데이터레벨에서 하둡으로 밀어내는 방식 등이었다. 이들은 기본적으로 하둡과 스플렁크가 병렬로 존재하는 구조다.
헝크는 하둡을 하위에 두는 상위 플랫폼이다. 즉, 스플렁크가 관계형데이터베이스(RDB), 하둡, NoSQL 등을 통할하는 구조가 스플렁크의 장기적인 비전인 것이다.

장 부장은 “버추얼인덱스란 핵심 기술을 바탕으로 RDB, 하둡, NOSQL 등을 스플렁크로 다 모아서, 기존 스플렁크 데이터까지 합쳐서 SPL로 액세스하게 열어주겠다는 게 궁극적 목표”라며 “헝크는 여기서 하둡과 관련된 부분일 뿐”이라고 말했다.
관련기사
- 스플렁크, 하둡 분석·시각화툴 '헝크' 발표2013.07.23
- IBM, 빅데이터SW 스플렁크 인수하나2013.07.23
- 스플렁크 "하둡 대항마? 더 잘 쓰게 보완"2013.07.23
- 급한 불 끈 홈플러스...경영 정상화는 ‘산 넘어 산’2026.07.16
스플렁크는 이를 위해 세계 3대 하둡 배포판 업체와 협력을 공고히 했다. 클라우데라, 호튼웍스, 맵R 등이 스플렁크 헝크를 자사의 플랫폼에서 지원하겠다고 나선 상황이다. 이들은 각각 클라우데라하둡배포판(CDH), 호튼웍스데이터플랫폼(HDP), 맵R네트워크파일시스템 등에서 헝크를 검증하고 있다고 밝혔다.
헝크는 아직 비공개베타버전이다. 신청과 허가의 절차를 거쳐 사용할 수 있다. 상용 버전이 아닌 만큼 라이선스 체계도 공개되지 않은 상황이다. 데이터를 스프렁크에 저장하는 게 아닌 만큼 기존의 일일 용량 기반 과금 방식을 그대로 적용하진 않을 것으로 보인다.