






엔비디아·AMD GPU 대비 가격 대비 성능을 극대화한 인텔 AI GPU 워크스테이션 '프로젝트 배틀매트릭스'(Project Battlematrix)가 최근 리눅스용 소프트웨어 정식 버전(1.0)을 공개하고 지속적인 업데이트를 예고했다.
프로젝트 배틀매트릭스는 최대 1만 달러(약 1천383만원) 가격에 1천500억 개 매개변수로 구성된 거대언어모델(LLM)을 처리할 수 있는 AI 추론 특화 워크스테이션이다.

비용 대비 효율을 중시하는 중/소규모 기업과 개발자 대상으로 클라우드 의존도가 높은 현 AI 워크로드 운영 방식을 온프레미스 중심으로 일부 전환할 수 있는 가능성을 제공한다는 점에서 의미가 크다.
5월 아크 프로 GPU 기반 '배틀매트릭스' 공개
프로젝트 배틀매트릭스는 인텔이 지난 5월 워크스테이션 GPU인 아크 프로 B시리즈와 함께 공개한 AI 워크스테이션 플랫폼이다.

Xe2 코어 20개와 24GB 메모리를 탑재한 아크 프로 B60 GPU 최대 8개를 결합해 INT8(정수, 8비트) 기준 1,576 TOPS(1초당 1조 번 연산)급 연산 성능을 구현했다. GPU가 활용하는 메모리 용량은 192GB로 1천500억 개 매개변수로 구성된 거대언어모델(LLM)을 구동할 수 있다.
운영체제 구동에는 워크스테이션급 제온 프로세서를 활용하고 운영체제는 리눅스를 활용하다. 가격대는 5천 달러(약 691만원)에서 1만 달러(약 1천383만원)로 AI 추론 인프라에 대한 진입 장벽을 낮추는 것을 목표로 한다.
LLM 스케일러 1.0 공개... 추론 속도 최대 4배 향상
인텔은 배틀매트릭스용 소프트웨어 구축에 CPU와 GPU, NPU와 가속기 등 연산 자원을 모두 활용하는 원API(OneAPI)를 활용하고 이를 지속적으로 개선하고 있다.
이달 초순 공개된 LLM 스케일러 1.0 버전은 초기 버전 대비 LLM 처리 속도 향상에 중점을 뒀다. 매개변수 320억 개 규모 모델 기준 처리 속도는 1.8배, 700억 개급 모델 처리 성능은 4.2배 높아졌다.
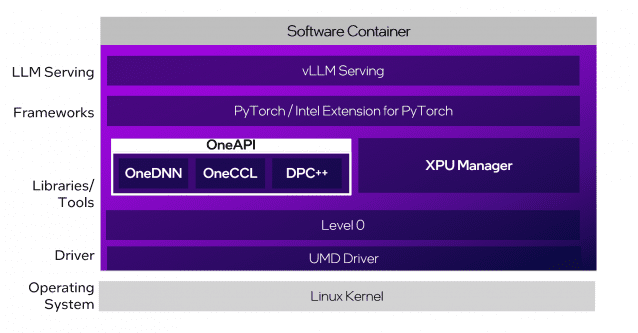
레이어별 온라인 양자화를 통해 GPU 메모리 요구량을 줄였고, vLLM 기반 파이프라인 병렬 처리를 실험적으로 도입해 대규모 모델 추론의 병목을 완화했다.
임베딩·재순위 모델 지원, 멀티모달 입력 처리 강화, 최대 길이 자동 감지, 데이터 병렬 처리 최적화 기능도 새롭게 추가됐다.
원격 관리가 필요한 기업 환경에서 GPU 전력 관리와 펌웨어 업데이트, 메모리 대역폭 모니터링 등 기능을 갖춘 XPU 매니저를 추가했다. GPU 1개를 여러 가상화 인스턴스가 활용할 수 있는 SR-IOV 기능도 추가했다.
중소기업·개인 개발자 위한 온프레미스 추론 인프라 제공
현재 GPU 시장은 엔비디아와 AMD가 성능 중심의 서버 시장을 양분하다시피 하는 상황이다. 반면 인텔이 하바나랩스 인수 후 출시하고 있는 AI 가속기인 가우디3는 제한적인 시장 점유율을 확보하고 있다.
관련기사
- 키사이트 EDA, 인텔 파운드리와 'EMIB-T' 실리콘 브리지 기술 협력2025.08.13
- 트럼프, '물러나라' 요구했던 인텔 립부 탄 CEO 만나2025.08.12
- 인텔 감원, 리눅스용 드라이버 지원에도 타격2025.08.10
- 엔비디아 윈도 PC용 'N1X' 칩, 벤치마크서 포착2025.08.04

배틀매트릭스는 정체된 서버 시장 대신 합리적인 가격·멀티 GPU 확장성·관리 편의성을 무기로 중소기업과 개인 개발자층을 직접 공략하기 위한 제품이다.
향후 로드맵도 공격적이다. 인텔은 이달 LLM 스케일러 공개에 이어 오는 SR-IOV 고도화, VDI 지원, 관리 소프트웨어 배포 기능 등 모든 기능을 구현한 완전판을 공개 예정이다.





