






국내 대학과 기업이 챗GPT나 딥시크 등 초거대형 AI 모델 학습 비용을 5%정도 줄일 시뮬레이션 프레임워크를 개발하고, 이를 '깃허브'에 공개했다.
KAIST(총장 이광형)는 전기및전자공학부 유민수 교수 연구팀이 삼성전자 삼성종합기술원과 공동으로 대규모 분산 시스템에서 대형 언어 모델(LLM)의 학습 시간을 예측하고 최적화할 수 있는 시뮬레이션 프레임워크(이하 vTrain)를 개발했다고 13일 밝혔다.
최근 챗GPT나 딥시크등과 같은 초거대 언어 모델(LLM)이 주목받으면서 대규모 GPU 클러스터 운영과 최적화가 현안으로 떠올랐다.

그러나 이 같은 LLM은 수천에서 수만 개의 GPU를 활용한 학습이 필요하다. 특히, 학습 과정을 어떻게 병렬화하고 분산시키느냐에 따라 학습 시간과 비용이 크게 달라진다.
KAIST와 삼성이 개발한 시뮬레이션이 이 같은 학습효율과 비용 문제를 개선했다.
연구팀은 병렬화 기법에 따른 통신 패턴을 효과적으로 표현하는 실행 그래프 생성 방법과 프로파일링 오버헤드를 최소화하는 연산 선별 기법을 개발했다.
이를 연구팀이 다중 GPU 환경에서 다양한 대형 언어 모델 학습 시간 실측값과 '브이트레인' 예측값을 비교한 결과, 단일 노드에서 평균 절대 오차(MAPE) 8.37%, 다중 노드에서 14.73%의 정확도로 학습 시간을 예측했다.
유민수 교수는 "기존 경험적 방식 대비 GPU 사용률을 10% 이상 향상시키면서도 학습 비용은 5% 이상 절감하는 것을 확인했다"고 말했다.
연구팀은 또 클라우드 환경에서 다중 테넌트 GPU 클러스터 운영 최적화와 주어진 컴퓨팅 자원 내에서 최적의 LLM 크기와 학습 토큰 수를 결정하는 문제와 같은 사례에서도 이 시물레이션 활용이 가능하다고 부연설명했다.
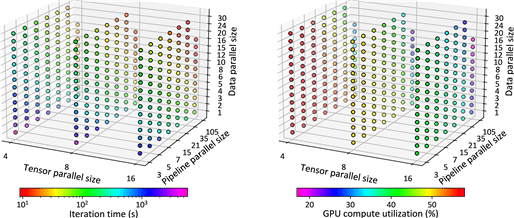
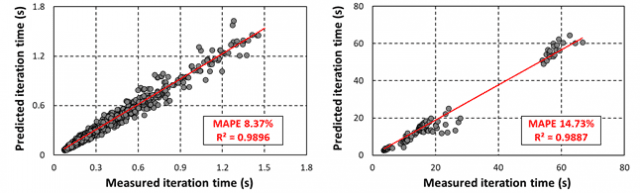
연구팀은 이 프레임워크와 1천500개 이상의 실제 학습 시간 측정 데이터를 오픈소스로 '깃허브'에 공개, AI 연구자와 기업이 이를 자유롭게 활용할 수 있도록 했다.
관련기사
- ETRI, AI모델 이용 상수도 디지털 관제시스템 개발2025.03.11
- KAIST, 변환 라벨없이 스스로 학습가능한 AI 모델 개발2024.12.13
- 투비유니콘, 의료분야 AI진료 상담사 '닥터챗' 첫 공개2024.11.08
- 작게, 더 작게…AI 모델 크기 줄인다2024.07.08
유민수 교수는 “프로파일링 기반 시뮬레이션 기법으로 기존 경험적 방식 대비 GPU 사용률을 높이고 학습 비용을 절감할 수 있는 학습 전략"이라고 덧붙였다.
연구 결과는 방제현 박사과정이 제 1저자로 참여했다. 과학기술정보통신부와 삼성전자가 지원했다.





