







기존 딥페이크 음성 탐지의 한계: 사후 대응에서 사전 예방으로
중국 란저우대학교 연구진이 발표한 논문에 따르면, AI 음성 복제 기술의 발전이 텍스트 음성 변환(TTS)과 음성 변환(VC) 분야에서 괄목할만한 성과를 보이고 있다. 하지만 이러한 발전은 동시에 심각한 보안 위험을 초래하고 있다. 기존의 수동적 탐지 기술들은 워터마킹이나 패시브 탐지 기술에 의존해 공격이 발생한 후에야 대응이 가능했으며, 특정 공격 패턴에만 과적합되는 한계를 보였다. (☞ 논문 바로가기)
AI 음성 복제의 핵심 기술: 음성 변환과 TTS의 작동 원리
음성 복제 기술은 크게 음성 변환(Voice Conversion)과 텍스트 음성 변환(TTS) 두 가지 방식으로 구현된다. 음성 변환은 임의의 화자 음성을 목표 화자의 음성으로 변환하면서 언어적 내용은 유지하는 기술이다. 반면 TTS는 더 유연한 방식으로, 원본 화자의 음성 없이도 텍스트만으로 원하는 음성을 생성할 수 있다.
이러한 기술의 핵심에는 타코트론(Tacotron)과 패스트스피치(FastSpeech)와 같은 딥러닝 기반 음향 모델이 있다. 특히 타코트론2는 위치 인식 어텐션 모듈을 도입해 합성 품질을 크게 개선했으며, 패스트스피치2는 음향 사전 정보를 활용해 더욱 향상된 결과를 제공한다. 음성의 최종 합성 단계에서는 하이파이-GAN(HiFi-GAN)과 같은 보코더가 사용되어 더욱 자연스러운 음성을 생성한다.
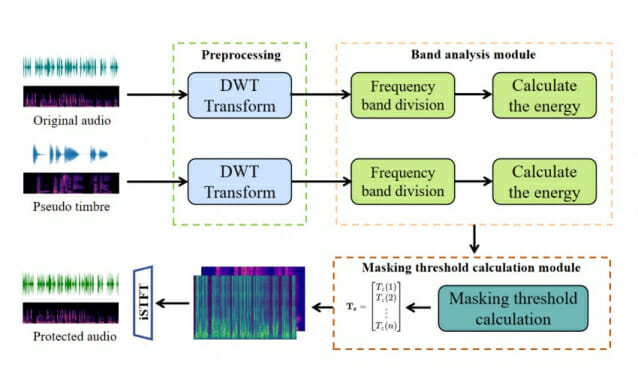
청각 마스킹 효과로 AI 음성 복제 차단: 음성 신호의 최대 60%까지 위장 가능
연구팀이 개발한 '보컬크립트(VocalCrypt)'는 인간의 청각 시스템의 특성을 활용한 혁신적인 방어 기법이다. 이 기술은 복잡한 음성 신호에서 30-60%가 마스킹 효과로 인해 인간의 귀로는 감지할 수 없다는 원리를 활용한다. 구체적으로 20Hz에서 22.05kHz 범위를 25개의 임계 대역으로 나누어 처리하며, 특히 저주파 영역(17번 밴드, 20~770Hz)에 중점을 둔다.
마스킹 임계값 기반의 적응형 강도 제어: NMR -5dB 이하 유지
보컬크립트는 소리의 각 주파수 대역별로 '마스킹 임계값'이라는 기준을 설정하여 위장 음색의 세기를 정밀하게 조절한다. 이는 마치 큰 소리가 작은 소리를 가리는 현상을 과학적으로 활용하는 것이다. 연구팀은 우리 귀가 어떤 소리는 잘 듣고 어떤 소리는 잘 듣지 못하는 특성을 철저히 분석했다.
이들은 소리의 특성을 순수한 음(예: 단일 피아노 음)부터 복잡한 소음까지 단계별로 구분했다. 실제 사람의 목소리는 대개 이 둘의 중간 어딘가에 위치한다. 연구진은 이런 특성을 고려해 각 소리 구간마다 최적의 위장 음색 강도를 결정했다.
특히 위장 음색의 세기를 특정 수준(기술적으로는 -5dB) 이하로 유지하여 사람의 귀로는 전혀 감지할 수 없게 만들었다. 이는 마치 큰 소리 속에 작은 소리를 숨기는 것과 같은 원리다. 결과적으로 우리가 들을 때는 원본 음성과 차이를 느끼지 못하지만, AI 음성 복제 시스템이 이 음성을 학습하거나 복제하려고 할 때는 심각한 방해를 받게 된다.
이러한 정교한 조절 덕분에 보컬크립트는 음성의 자연스러움은 그대로 유지하면서도 AI의 음성 도용 시도를 효과적으로 차단할 수 있게 되었다. 이는 마치 사람의 눈에는 보이지 않는 보안 워터마크를 음성에 삽입하는 것과 비슷한 효과를 낸다고 볼 수 있다.
음성의 언어, 화자의 성별에 관계없이 일관된 방어 효과 입증
연구팀은 상용 모델인 일레븐랩스(ElevenLabs)와 오픈소스 모델 GPT-SoVITS, XTTSv2, SEED-VC, StyleTTS2를 대상으로 광범위한 성능 검증을 실시했다. 실험은 CSTR VCTK 데이터셋의 영어 음성과 Zhvoice 데이터셋의 중국어 음성을 활용했다. VCTK 데이터셋은 109명의 영어 화자가 각각 약 400문장을 녹음한 데이터이며, Zhvoice 데이터셋은 약 3,200명의 화자, 900시간 분량의 오디오, 113만 줄의 텍스트로 구성된 대규모 데이터셋이다.
테스트의 공정성을 위해 데이터를 중국어 남성, 중국어 여성, 영어 남성, 영어 여성 등 4개 카테고리로 나누고 각 카테고리별로 100개 문장을 계층적 무작위 추출 방식으로 선정했다. 자동 화자 인증(ASV) 시스템을 통한 평가에서, 두 음성의 유사도 점수가 0.8을 넘으면 동일 화자로 판단하는데, 보컬크립트로 보호된 음성은 대부분 이 기준치 아래의 점수를 기록했다.
구체적인 실험 결과를 보면, 일레븐랩스에 대해 중국어 여성 화자는 0.627, 영어 여성 화자는 0.442의 유사도 점수를 보였다. GPT-SoVITS에 대해서는 각각 0.661과 0.465를 기록했으며, 다른 모델들에 대해서도 대부분 0.6 이하의 낮은 유사도를 유지했다. 특히 주목할 만한 점은 이러한 방어 효과가 음성의 언어나 화자의 성별에 관계없이 일관되게 나타났다는 것이다.
실제 공격 시나리오를 고려해 아마추어 공격자와 전문 공격자의 두 가지 유형으로 나누어 테스트도 진행했다. 아마추어 공격자는 readily available한 온라인 상용 제품이나 간단한 사전 학습 모델을 사용하는 것으로 가정했고, 전문 공격자는 적대적 공격, 미세 조정 등 고급 기술을 사용하는 것으로 설정했다. 두 경우 모두에서 보컬크립트는 효과적인 방어 성능을 보여주었다.
500% 빠른 처리 속도와 0.942의 음질 점수 달성
관련기사
- '초거대 AI 모델' 3파전…한국, 미국·중국 이어 3위2025.02.17
- [Q&AI] 재직 중 출산 시 1억?…크래프톤의 출산 장려 정책, 뭐가 다르나 봤더니2025.02.17
- 미국인 'AI 의존' 심하네…어느 정도인지 봤더니2025.02.15
- 금메달리스트급 AI 등장... 구글 '알파지오메트리2' IMO 기하학 문제 84% 해결2025.02.17
기존 GAN 기반 방어 기술들과 비교해 처리 속도가 5배 향상되었으며, 음질 평가에서도 0.942라는 높은 점수를 기록했다. 이는 기존 기술들의 음질 점수인 0.984(Huang's)와 0.956(Dong's)에 근접한 수준이다. 연구팀은 이 기술의 실시간 처리 성능을 바탕으로 마이크나 사운드카드에 직접 통합하는 방안을 검토 중이다.
■ 이 기사는 AI 전문 매체 ‘AI 매터스’와 제휴를 통해 제공됩니다. 기사는 클로드 3.5 소네트와 챗GPT를 활용해 작성되었습니다. (☞ 기사 원문 바로가기)





