







수학·코드 넘어선 AI 추론력 강화의 새 길 제시
딥시크AI(DeepSeek-AI)의 연구에 따르면, 대규모 언어모델(LLM)의 추론 능력을 향상시키기 위한 새로운 접근법 'CODEI/O'가 개발되었다. 기존의 연구들이 수학이나 코드 생성과 같은 특정 영역에 집중했던 것과 달리, CODEI/O는 다양한 추론 패턴을 코드를 통해 학습하는 방식을 제시했다. 특히 논리적 추론, 과학적 추론, 상징적 추론 등 다양한 영역의 추론 과제에서 데이터가 부족하고 분산되어 있는 문제를 해결하고자 했다. (☞ 논문 바로가기)
81만 개 코드 파일에서 추출한 45만 개 함수로 구축한 학습 데이터
CODEI/O는 코드믹스(CodeMix)와 파이에듀-R(PyEdu-R) 등 다양한 소스에서 총 81만 개의 코드 파일을 수집했다. 코드믹스에서는 딥시크 코더 V2 라이트 모델의 함수 완성 작업 성공률이 10%에서 90% 사이인 42.7만 개의 파일을 선별했고, 파이에듀-R에서는 36.9만 개의 파일을 확보했다. 이 외에도 알고리즘 저장소, 수학 문제 컬렉션, 유명 코딩 플랫폼 등에서 1.45만 개의 고품질 코드 파일을 추가로 수집했다.
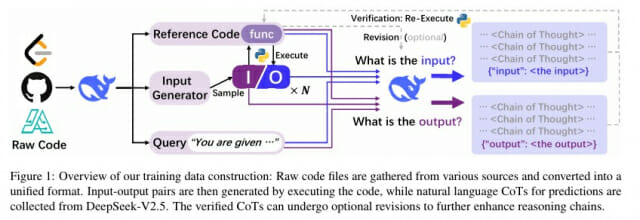
코드 실행 결과로 검증하는 입출력 예측 학습 방식
CODEI/O는 수집된 코드를 단순 학습하는 대신, 실행 가능한 함수로 변환하고 이를 입력-출력 예측 작업으로 재구성했다. 각 함수마다 최대 10개의 입출력 쌍을 생성했으며, 모든 입력과 출력은 자연어 형태의 Chain-of-Thought(CoT) 추론 과정으로 표현했다. 실행 시간은 샘플당 5초로 제한했고, 입출력 객체의 복잡도도 제한을 두어 일반 LLM이 생성할 수 있는 수준을 유지했다.
검증된 데이터로 재학습시킨 CODEI/O++, 더 높은 성능 달성
개선된 버전인 CODEI/O++는 DeepSeek-V2.5 모델을 활용해 잘못된 예측을 수정하는 다중 턴 방식을 도입했다. 첫 시도에서 약 50%의 정확도를 보였고, 부정확한 응답 중 약 10%가 두 번째 시도에서 수정되었다. 특히 출력 예측의 경우 51.8%가 첫 시도에서 정확했고, 나머지 중 5.2%가 두 번째 시도에서 정확도를 개선했다.
14개 벤치마크에서 입증된 뛰어난 범용 성능
연구팀은 Qwen 2.5 7B Coder, Deepseek v2 Lite Coder, LLaMA 3.1 8B, Gemma 2 27B 등 다양한 모델에서 실험을 진행했다. 그 결과 CODEI/O는 DROP(자연어 추론), WinoGrande(상식 추론), GSM8K(수학), MATH(수학), MMLU-STEM(과학/기술), BBH(논리), GPQA(과학), Cruxeval(코드), ZebraGrid(논리) 등 14개 벤치마크에서 일관된 성능 향상을 보였다. 특히 Qwen 2.5 7B Coder 모델의 경우 기본 성능 54.8에서 CODEI/O 적용 후 57.2, CODEI/O++ 적용 후 57.7로 꾸준한 성능 향상을 보였다.
두 단계 학습이 성능 향상의 핵심...기존 단일 단계 대비 최대 3.4포인트 향상
연구팀은 CODEI/O 학습을 일반 지시학습 이전 단계에 별도로 진행하는 두 단계 학습법을 채택했다. Qwen 2.5 Coder 7B 모델에서 단일 단계 학습 시 54.8점이었던 성능이 CODEI/O 선행 학습 후 57.2점으로 향상되었다. LLaMA 3.1 8B 모델에서도 49.3점에서 52.7점으로 성능이 개선되었다. 특히 연구팀은 약 118만 개의 다국어 지시학습 데이터셋을 사용했는데, 이는 CODEI/O 데이터보다 크기가 작아 두 데이터셋을 단순 혼합할 경우 학습이 균형적으로 이루어지지 않는다는 점을 발견했다.
참조 코드와 추론 과정 배치가 성능 좌우...쿼리-코드 함께 제시할 때 최고 성능
연구팀은 쿼리, 참조 코드, Chain-of-Thought(CoT) 추론 과정의 최적 배치 방식도 실험했다. 쿼리와 참조 코드를 프롬프트에 함께 제시하고 CoT를 응답으로 두는 방식이 가장 높은 57.2점을 기록했다. 반면 쿼리만 프롬프트에 제시하고 참조 코드를 응답에 포함시키는 방식은 54.9점으로 가장 낮은 성능을 보였다. 이는 코드 생성 작업과 유사한 형태지만 훈련 샘플이 더 적어 성능이 제한된 것으로 분석됐다.
데이터 규모 확장에 따른 성능 향상 입증
관련기사
- 미국인 'AI 의존' 심하네…어느 정도인지 봤더니2025.02.15
- 코드 한 줄당 44만원 손실... 생성형 AI가 레거시 앱 비용 잡는다2025.02.15
- 챗GPT가 쓴 글, 사람 글과 어떤 점이 다를까2025.02.15
- 로봇 도입 경계하는 현대차 노조…BMW·벤츠는 어떻게?2026.07.18
연구팀은 훈련 샘플 수와 입출력 쌍 수에 따른 성능 변화도 분석했다. 훈련 샘플을 0.32M에서 3.52M까지 늘렸을 때 성능이 지속적으로 향상되었고, 각 함수당 입출력 쌍을 1/6에서 6/6까지 늘렸을 때도 성능이 개선되었다. 이는 CODEI/O가 더 큰 규모의 데이터셋으로 확장될 수 있는 가능성을 보여준다.
■ 이 기사는 AI 전문 매체 ‘AI 매터스’와 제휴를 통해 제공됩니다. 기사는 클로드 3.5 소네트와 챗GPT를 활용해 작성되었습니다. (☞ 기사 원문 바로가기)





