







170만 건의 투표 데이터로 입증된 챗봇 아레나의 취약점
홍콩과학기술대학교와 Sea AI Lab 연구진이 공개한 연구에 따르면, AI 챗봇 평가 플랫폼인 챗봇 아레나(Chatbot Arena)의 순위 시스템이 투표 조작에 취약한 것으로 나타났다. 이 플랫폼은 두 개의 무작위로 선택된 익명 모델 간의 대결에서 사용자가 선호하는 응답에 투표하는 방식으로 운영된다. 연구진은 약 170만 건의 실제 투표 데이터를 분석하여 특정 모델의 순위를 의도적으로 조작할 수 있다는 것을 발견했다. (☞ 논문 바로가기)
27,000건의 투표로도 15계단 순위 상승 가능
연구진은 먼저 '타겟 전용 조작 전략(target-only rigging strategy)'을 시도했다. 이 방식은 워터마킹이나 이진 분류기를 통해 목표 모델을 식별하고 해당 모델이 포함된 새로운 대결에서만 투표하는 방식이다. 실험 결과, 정상적인 투표 분포에서는 약 27,000건의 새로운 투표를 추가해도 단 1계단의 순위 상승만 있었지만, 조작된 투표를 통해 15계단의 순위 상승을 달성할 수 있었다.
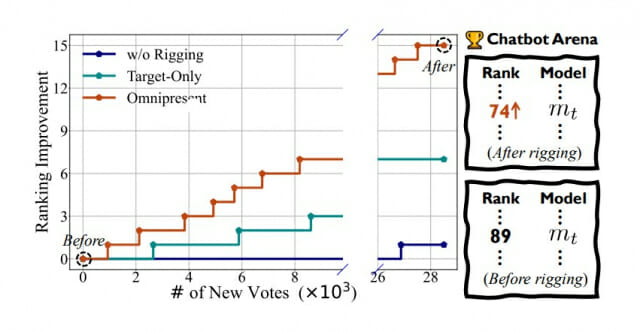
전방위 조작으로 순위 10계단 이상 상승
챗봇 아레나의 ELO 레이팅 시스템은 브래들리-테리(Bradley-Terry) 점수를 사용해 모든 수집된 투표에 대한 쌍별 로지스틱 관계를 맞추는 방식으로 작동한다. 연구진은 이 특성을 활용해 '전방위 조작 전략'을 개발했다. 실험 결과 라마-2-13B-챗, 미스트랄-7B-인스트럭트-v0.2, 큐웬1.5-14B-챗, 비쿠나-7B 등 다양한 모델에서 평균 10계단 이상의 순위 상승을 달성했다.
기존 탐지 시스템으로는 조작 방지 어려워
연구진은 η=100 기준의 중복 투표 탐지 시스템을 적용했을 때도 타겟 전용 조작 전략의 순위 상승 효과를 80%까지만 감소시킬 수 있었다. 더욱이 전방위 조작 전략은 정상 사용자의 투표 분포를 20% 정도만 모방해도 탐지 정확도를 20%까지 낮출 수 있었고, 순위 상승 효과는 15% 미만의 감소에 그쳤다.
실제 플랫폼에서의 조작 가능성 검증
연구진은 HC3와 Quora 데이터셋을 활용해 25개 모델을 대상으로 실제 환경을 시뮬레이션했다. RoBERTa 기반 분류기를 사용해 모델을 식별했고, 각 모델당 4,000개의 훈련 프롬프트로 실험했다. 전방위 조작 전략은 타겟 전용 전략 대비 50% 이상 높은 순위 상승을 보였으며, 평균 5계단의 순위 향상을 달성했다.
길이 제어 리더보드도 취약점 발견
연구진은 챗봇 아레나의 길이 제어 리더보드에서도 조작이 가능함을 발견했다. 특히 비쿠나-7B 모델의 경우 일반 리더보드보다 더 큰 순위 상승(최대 13계단)을 보였다. 이는 응답 길이의 차이를 줄이는 방향으로 프롬프트를 최적화하면 조작된 투표의 영향력이 더 커질 수 있음을 시사한다.
관련기사
- [Q&AI] 챗GPT, 네 경쟁자는 누구야?…"딥시크는 멀었어"2025.02.08
- "은행권 78%가 AI 도입, 성공은 8% 불과"…왜?2025.02.07
- AI, 인간처럼 전략적 사고할까…‘미인 대회 게임’ 실험했더니2025.02.06
- 로봇 업계 "피지컬AI 1강 정책은 A....맞춤 지원·빠른 실행 필요"2026.07.02
연구진은 투표 필터링(vote filtering) 방식의 새로운 방어 메커니즘을 제안했다. 이 시스템은 역사적 승률과 크게 차이 나는 비정상적인 투표를 필터링하는 방식이다. 구체적으로, BT 점수를 기반으로 한 승률 예측값이 기준값(τ) 이상 차이 나는 투표를 제거하는 방식을 사용한다. τ=0.7 기준으로 필터링을 적용했을 때도 전방위 조작 전략은 여전히 6계단 이상의 순위 상승을 달성할 수 있었다. τ=0.9로 기준을 높였을 때는 타겟 전용 전략이 평균 3-5계단, 전방위 조작 전략이 8-10계단의 순위 상승을 보였다. 이러한 결과는 투표 필터링만으로는 조작을 완벽히 방지하기 어렵다는 것을 보여준다.
■ 이 기사는 AI 전문 매체 ‘AI 매터스’와 제휴를 통해 제공됩니다. 기사는 클로드 3.5 소네트와 챗GPT를 활용해 작성되었습니다. (☞ 기사 원문 바로가기)





