






과학 연구를 위한 맞춤형 AI 시스템의 등장
코넬 대학교 연구진이 과학 연구에서 AI의 신뢰성과 해석 가능성을 높인 새로운 프레임워크 'AISciVision'을 개발했다. 최근 OpenAI의 GPT, Google의 Gemini, Meta의 Llama 등 대규모 멀티모달 모델(Large Multimodal Models, LMMs)의 등장으로 AI와의 의미 있는 대화가 일상이 되었지만, 의학, 법률, 과학 연구와 같은 전문 분야에서는 더 깊은 도메인 특화 추론이 필요했다. LMM에 내장된 일반 지식만으로는 이러한 전문 분야의 세밀한 전문성을 충족시키기 어렵다는 한계가 있었다.
맥락 학습을 통한 전문성 확보
AISciVision은 LMM의 넓은 맥락 창(context window)을 활용해 인-콘텍스트 학습을 통한 유연한 특화가 가능하다. 풍부한 프롬프트와 특정 작업 관련 맥락을 제공함으로써 LMM이 도메인별 요구사항에 적응할 수 있게 했다. 이는 검색 증강 생성(RAG) 분야의 흥미로운 연구 발전을 이끌고 있다. RAG 기술은 작업별 예시를 검색하여 LMM의 예측을 향상시키고, 맥락을 기반으로 모델의 응답을 세분화함으로써 해당 작업에 특화시킨다.
전문가의 작업 방식을 모사한 혁신적 구조
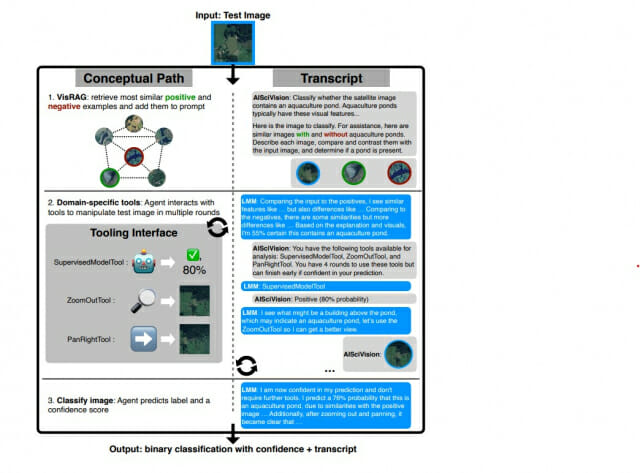
AISciVision은 시각적 검색 기반 생성(Visual Retrieval-Augmented Generation, VisRAG)과 도메인별 특화 도구를 결합했다. 사용자가 제공한 학습 데이터는 특징 공간에 임베딩되어 긍정 및 부정 클래스 예시가 별도로 구성된다. 분류 도구는 기본적인 이미지 조정부터 위성 이미지 확대와 같은 도메인별 작업까지 포함한다. 추론 시에는 코사인 유사도를 기반으로 훈련 세트에서 가장 유사한 긍정 및 부정 이미지 예시를 검색하여 LMM의 분석 맥락으로 활용한다.
AISciVision은 4단계의 추론 과정을 거친다. 먼저 입력 이미지가 주어지면 VisRAG가 유사한 이미지들을 검색한다. 이후 LMM이 최대 4라운드에 걸쳐 도구들을 선택하고 적용하며 분석을 수행한다. 각 라운드마다 신뢰도 점수를 함께 제공하여 예측의 확실성을 평가할 수 있게 했다. 예를 들어 {Yes:80,No:20}와 같은 형식으로 결과를 표현하여 판단의 근거를 명확히 한다.
실제 데이터셋에서 입증된 우수한 성능
연구팀은 세 가지 실제 과학 이미지 분류 데이터셋에서 AISciVision의 성능을 검증했다. 첫째로 론도니아 브라질의 양식장 탐지를 위한 799개의 이미지(640×640), 둘째로 워싱턴 주의 잘피 질병 탐지를 위한 9,887개의 이미지(128×128), 마지막으로 태양광 패널 탐지를 위한 11,814개의 이미지(320×320) 데이터셋을 활용했다. 테스트 결과 저표지 데이터 환경(20%)과 전체 레이블 데이터 환경(100%) 모두에서 기존의 완전 감독 학습 모델들과 제로샷 방식을 능가하는 성능을 보였다.
AISciVision은 k-NN, CLIP-ZeroShot, CLIP+MLP 등 여러 베이스라인 모델과 비교 실험을 진행했다. 양식장 데이터셋의 경우 20% 데이터 환경에서 AISciVision이 정확도 0.90, F1 스코어 0.78, AUC 0.95를 기록하며 가장 높은 성능을 보였다. 특히 CLIP-ZeroShot이 양식장 데이터셋에서 F1 스코어 0.0을 기록한 것과 대조적으로, AISciVision은 저표지 환경에서도 안정적인 성능을 보여주었다. 이는 도메인 특화 구조의 효과성을 입증하는 결과다.
도구 활용 분석 결과
연구팀은 각 데이터셋별로 도구 사용 빈도와 정확도에 대한 분석을 실시했다. 모든 데이터셋에서 'MLToolPredict' 도구가 가장 자주 사용되었지만, 단순히 이 도구의 결과에만 의존하지 않는다는 점이 흥미롭다. 양식장 데이터셋의 경우 지리공간 도구들이 높은 빈도로 사용되었으며, 이는 주변 지역의 추가 정보를 얻는 데 도움을 주었다. AdjustBrightness 도구는 거의 사용되지 않았고, HistogramEqualization은 제한적으로 사용되는 등 도구별 활용도의 차이도 관찰되었다.
전문가와 상호작용하는 웹 애플리케이션 구현
AISciVision은 양식업 연구를 위한 웹 애플리케이션으로 실제 배포되었다. 전문가들은 ChatGPT 스타일의 인터페이스를 통해 추론 트랜스크립트와 상호작용하고, 명확한 질문을 하거나 수정/피드백을 제공할 수 있다. 향후 연구에서는 이러한 피드백을 VisRAG에 통합하여 전문가들이 대화하면서 지속적으로 모델을 개선할 수 있도록 할 예정이다.
프레임워크는 각 데이터셋의 특성에 맞는 도구들을 제공한다. 위성 이미지를 다루는 양식장 데이터셋의 경우 확대/축소와 이동 도구를 제공하며, 잘피와 태양광 패널 데이터셋의 경우 대비 조정과 선명도 향상 등 이미지 향상 도구를 제공한다. 이러한 도구들은 도메인 전문가들의 이미지 분석 과정을 모사하여 설계되었으며, 각 추론마다 예측과 함께 자연어 트랜스크립트를 통해 추론 과정의 투명성을 보장한다.
연구의 한계와 향후 과제
관련기사
- "대학생들, AI 잘 활용하면 자신감 높아진다"2025.01.13
- "AI 챗봇, 쓰면 쓸수록 불안감 줄어든다"...대학생 연구 결과2025.01.13
- "저작권? 상관없다"...저커버그, 라마 AI에 불법 데이터로 학습 지시2025.01.13
- AI도 기억 헷갈린다…'지식 충돌' 왜 생기나2025.01.10
LMM을 활용한 추론의 높은 비용은 이 프레임워크의 주요 한계점이다. 연구팀은 실험 비용을 고려해 각 데이터셋당 100개의 테스트 샘플만을 사용했다. 향후 연구에서는 도구 선택을 최적화하고 다른 과학 분야로의 확장 가능성을 탐구할 예정이다. 또한 전문가들의 피드백을 시스템 개선에 효과적으로 활용하는 방안도 연구 중이다.
■ 이 기사는 AI 전문 매체 ‘AI 매터스’와 제휴를 통해 제공됩니다. 기사는 클로드 3.5 소네트와 챗GPT-4o를 활용해 작성되었습니다. (☞ 논문 바로가기)





