






메타가 연구전용 인공지능(AI) 모델을 전 세계 커뮤니티에 오픈소스로 공개했다. 이를 통해 개방형 AI 모델 발전과 연구 활성화를 도울 방침이다.
18일(현지시간) 메타는 자사 기초AI연구팀(FAIR)이 텍스트와 이미지 음악 생성이 가능하고, 다중 토큰 예측과 음성을 감지할 수 있는 모델을 출시했다고 공식 블로그를 통해 밝혔다.
이번에 소개된 '카멜레온'은 이미지와 텍스트를 이해하고 처리할 수 있는 멀티모달 모델이다. 사람처럼 이미지와 텍스트를 동시에 처리할 수 있는 게 특장점이다.
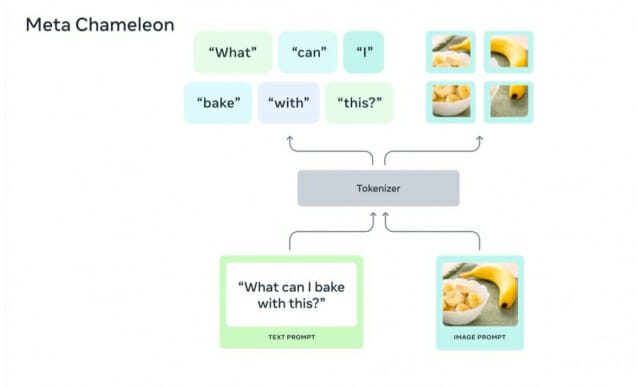
보통 AI 모델은 텍스트를 이미지로 변환하거나, 이미지를 텍스트로 바꿀 수는 있어도 이를 동시에 진행할 수는 없다. FAIR는 "카멜레온은 이미지에 대한 창의적 캡션을 생성하거나, 프롬프트와 이미지를 혼합해 새로운 장면을 만들 수 있는 모델"이라고 설명했다.
텍스트를 음악으로 바꿔주는 모델 '제스코'도 소개됐다. 문자뿐 아니라 코드나 비트 등 다양한 입력으로 음악을 생성할 수도 있다. 기존 음악 생성 모델 '뮤직 젠'처럼 텍스트에만 의존하는 것을 넘어선 셈이다.
AI의 음성을 탐지하는 모델 '오디오씰'도 나왔다. 첫 오디오 워터마킹 기술이기도 하다. 사용자는 이 모델로 오디오 스니펫 내에서 AI가 생성한 부분을 정확히 찾아낼 수 있다. FAIR는 기존 방식보다 탐지 속도를 최대 485배 올렸다고 밝혔다. 대규모 및 실시간 앱에 적용할 수 있다. 현재 연구용뿐 아니라 상업용으로도 이용 가능하다.
관련기사
- [ZD SW투데이] KISA, '플러스2024 보안 컨퍼런스' 개최 外2024.06.18
- [현장] "시간·돈 한없이 드는 설계 작업, 3DX로 한 번에 OK"2024.06.18
- 메타, 부사장 50명 줄인다…"AI와 기술력이 우선"2024.06.14
- 이재용, 메타∙아마존∙퀄컴 CEO 만나 'AI 협력 논의'2024.06.13
FAIR는 AI 모델이 전 세계 모든 사람들에게 잘 활용돼야 한다고 주장했다. 이에 모델 사용의 지리적 불균형을 자동으로 알려주는 지표를 내놨다고 밝혔다. 지역별로 지리적 표현에 대한 차이점을 분석한 결과도 공개했다. 이를 통해 AI로 만든 텍스트와 이미지 다양성과 표현력을 올리기 위해서다.
연구소 측은 "전 세계 커뮤니티가 AI 모델 전반의 다양성을 개선하는 데 도움 되길 바란다"고 블로그에서 강조했다.





