공격자는 인공지능(AI) 시스템에 의도적으로 접근해 오작동을 일으킬 수 있는데 이에 대한 완벽한 방어책은 없다.
미국 국가표준기술연구소(NIST)는 '적대적 머신러닝(ML): 공격 및 완화에 대한 분류와 용어' 가이드를 발표하고, 생성AI 도구 발전과 사이버 보안 위험을 경고했다.
인공지능, 머신러닝을 채택하는 기업은 늘어나고 있지만 이에 대한 취약성을 인지하고 사이버 보안 대책을 세우는 곳은 드물다. 대부분의 소프트웨어 에코시스템과 마찬가지로 진입 장벽이 낮을수록 보안 장벽도 낮아진다.
NIST는 가이드에서 AI에 나타날 수 있는 사이버 위협을 회피, 중독, 남용, 프라이버시 등 4가지 유형으로 분류했다. 사이버 보안 전문가들은 머신러닝 모델의 취약점과 특수성을 악용하는 공격 활동에 촉각을 곤두 세우고 있다. ML이 새로운 사이버 공격 표면이 됐기 때문이다.
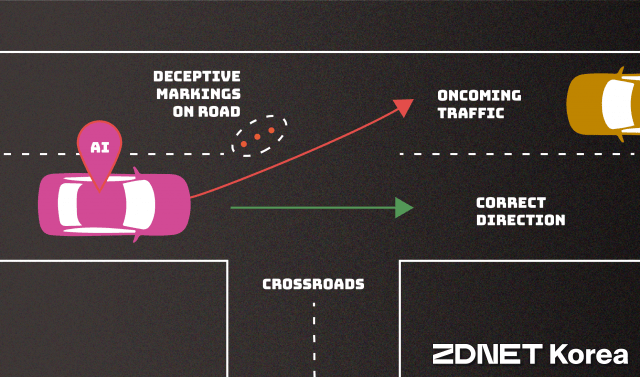
회피 공격(Evasion attack)은 AI시스템이 배포된 후 발생한다. 입력을 변경해 시스템이 응답하는 방식을 변경하는 공격이다. 예를 들면, 자율주행자동차가 인식하는 정지 표시판을 속도제한 표지판으로 잘 못 해석하게 하는 식이다. 혼란스러운 차선 표시를 만들어 차량이 도로를 벗어나게 하는 형태의 공격이다.
중독 공격(Poisoning attack)은 손상된 데이터를 삽입해 AI시스템 훈련 단계에서 발생한다. 적이 훈련 데이터 세트를 조작하는 공격이다. 공격자가 ML 모델에 부정확하거나 잘못 해석된 데이터를 공급해 잘못된 예측을 내놓게 만든다. 공격자가 훈련 데이터 중 일부에 부적절한 내용을 넣는다. AI 모델이 사용하는 데이터세트의 0.1%만 중독해도 성공적인 조작으로 이어질 수 있는 것으로 나타났다. 공격자는 위키피디아(Wikipedia)와 같은 크라우드 소스 정보 저장소 등을 악용해 LLM 모델을 간접적으로 조작할 수도 있다.
남용 공격(Abuse attack)은 피싱 이메일을 생성하거나 악성코드 작성과 같이 악성 콘텐츠를 생성하기 위해 AI 도구를 무기화하는 것이 포함된다. 실제로 다크웹에서 프러드(Fraud)GPT나 웜(Worm)GPT와 같이 사이버 범죄를 지원하는 LLM 서비스가 나왔다.
프라이버시 공격(Privacy attack)은 AI가 훈련한 데이터 중 민감 정보를 추출해 이를 오용하는 시도다. 공격자는 챗봇에게 다양한 질문을 한 후 모델을 리버스 엔지니어링해 약점을 찾거나 원본을 추측할 수 있다.
이외에도 공격자는 AI나 ML 모델의 취약점을 찾아 백도어를 만들거나 악성코드를 주입해 기업 내부로 침투하는 초기 네트워크 액세스 권한을 얻고 측면으로 이동할 수 있다. 악성코드를 배포하고 데이터를 훔치고 심지어 조직의 공급망을 오염시키는 공격이 가능하다.
가트너에 따르면 일반 소프트웨어에 대한 대부분 공격이 AI와 ML에 적용될 수 있다.
생성AI 보안 스타트업을 창업한 윤두식 이로운앤 컴퍼니 대표는 "기업이 LLM을 도입하는 과정에서 개인정보나 지적재산권이 유출될 수 있고 악성코드나 저품질 코드를 받을 있다"면서 "세계적으로도 생성AI 사이버 보안을 고려하는 LLMOps 분야가 확대되면서 대응책 마련을 시작했다"고 말했다.