






오픈AI가 초거대 멀티모달 GPT-4를 공개했다. 문자와 이미지를 이해할 수 있는 멀티모달 형태다. 오픈AI는 GPT-4 주요 특징을 ▲독창성 ▲문맥 이해도 ▲추론력 ▲멀티모달 등으로 꼽았다. 챗GPT플러스 고객은 현재 GPT-4를 이용할 수 있다. 기존 모델과 성능을 비교하기 위해 챗GPT플러스를 구독해 직접 체험했다.
GPT-4 답변 횟수 제한...GPT-3.5보다 속도 느려
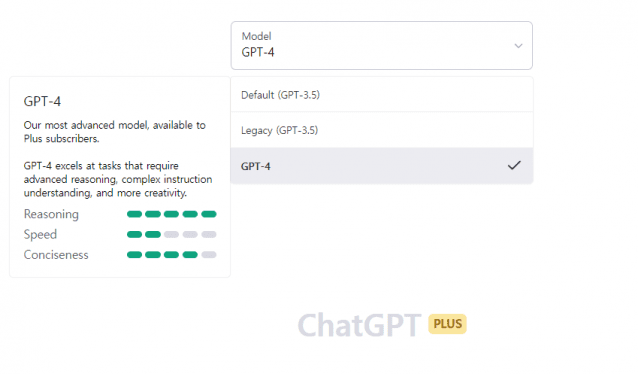
GPT-4 기본 성능을 GPT-3.5와 비교했다. 우선 사용자는 GPT-4로 대화를 무한대로 할 수 없다. 4시간에 100개씩만 질문할 수 있다. 반면 GPT-3.5로는 무제한으로 질문할 수 있다.
현재 GPT-4는 GPT-3.5보다 답변을 느리게 준다. 응답 자체가 느리거나 답변 중 작동을 멈춘다. 이 현상은 이미 오픈AI 홈페이지에 공지로 나왔다. 오픈AI 측은 GPT-3.5 속도 점수보다 GPT-4 속도를 더 낮게 평했다.
GPT-4, '문학인'으로 손색 없네...독창성 늘어
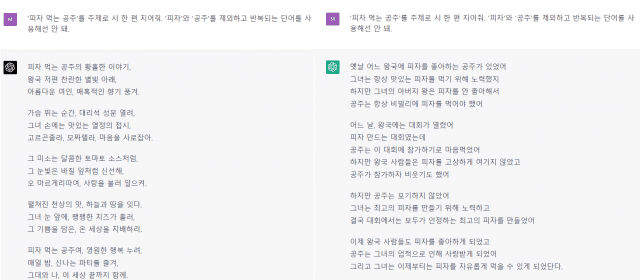
오픈AI는 이번 GPT 모델 창의력 성장을 재차 강조했다. 새 모델은 시뿐만 아니라 작사, 짧은 글, 문체 등에서 높은 독창성을 갖췄다는 의미다. 얼마나 성장했는지 직접 확인했다.
GPT-4와 GPT-3.5에 시를 작성하라고 요청했다. 주제는 '피자 먹는 공주'다. "'피자'와 '공주'를 제외하고 반복되는 단어를 사용해선 안 돼"라고 추가 요청도 했다.
GPT-4는 전형적인 시를 생성했다. 시인이 활용하는 비유법, 감탄사 등을 사용했다. 요청대로 단어 반복도 최대한 피했으며 단어를 다채롭게 넣었다.
GPT-3.5로 만든 시는 조금 달랐다. 형식은 시와 동일하지만 비유법, 감탄사 등을 활용하지 않았다. 동일 단어를 반복하지 말라는 요청도 GPT-4보다는 덜 반영된 듯하다. GPT-4 결과물보다는 한 편의 시라는 느낌이 덜 들었다.
장문도 이해 가능...문맥 파악 성장
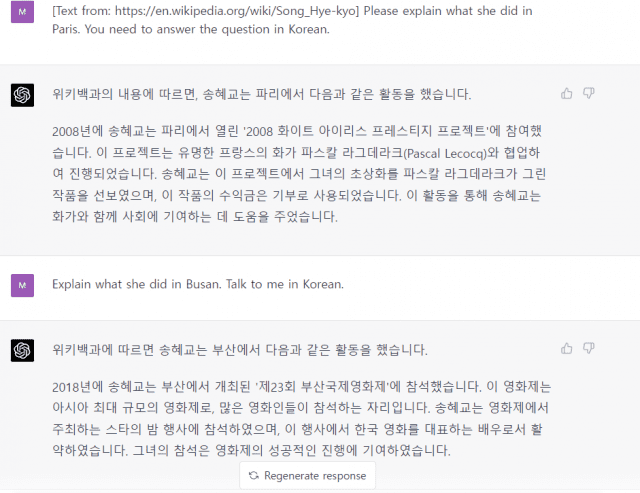
오픈AI는 GPT-4가 기존보다 긴 글을 읽을 수 있고 이를 통해 문맥 파악 능력을 키웠다고 블로그에서 밝혔다.
기존 GPT-3.5는 영어 기준 3천 단어까지 한번에 이해한다. GPT-4는 2만5천 단어를 한번에 인식할 수 있다. 결과적으로 이해도와 문맥 인식 능력을 키웠다는 의미다.
사실인지 확인할 필요가 있었다. 위키피디아에서 연예인 '송혜교'를 영어로 검색했다. 위키피디아는 송혜교를 3천개 넘는 영어 단어로 설명했다. 페이지 링크를 GPT-4에 입력한 뒤 "송혜교가 프랑스 파리에서 어떤 활동을 했는지 한국어로 설명하라"고 영어로 물었다.
GPT-4가 이에 답하려면 링크에 있는 긴 글을 이해해야 한다. 이중 송혜교가 파리에서 한 활동도 문맥 속에서 찾아야 한다. 한국어로 설명하라는 요청도 인식해야 한다. GPT-4는 송혜교 파리 활동을 글에서 찾았다. 답변도 한국어로 했다. 곧장 위키피디아에 있는 다른 내용을 물었다. 역시 요청한 대로 맞게 대답했다.
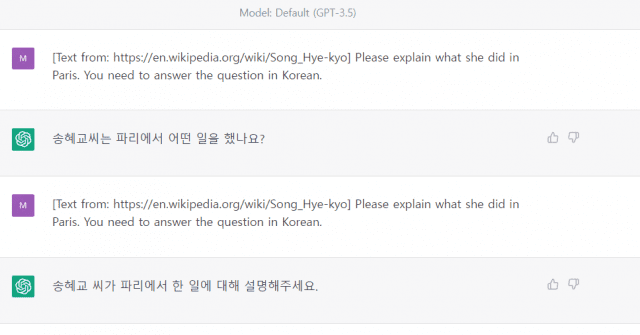
GPT-3.5에도 똑같은 질문을 했다. GPT-3.5는 문맥을 이해하는 것부터 틀렸다. 링크에 있는 글도 이해하지 못한 듯했다. 혹시나 하는 마음에 다시 물었다. GPT-3.5는 문맥을 잘못 파악했다. 한국어로 답해달라는 요청도 알아듣지 못했다.
요청 세밀히 파악...문서 작성도 꼼꼼
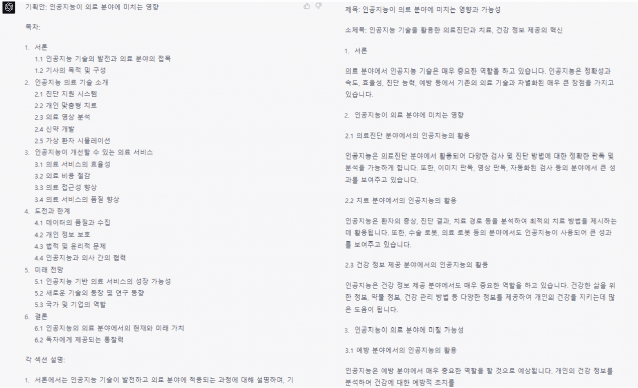
오픈AI는 GPT-4가 사용자 요청을 더 세밀히 파악할 수 있다고도 강조했다. 정말 그런지 알아봤다. 동일한 요청을 두 모델에 했다. "AI가 의료 분야에 미치는 영향에 대한 기획 기사를 작성할 거야. 기획안 만들어 줘"라고 물었다.
GPT-4는 기획안 목차를 서론, 본론, 결론으로 나눴다. 목차는 AI 의료 기술에 대한 개념, AI 의료 서비스, 관련 분야 전망과 한계로 이뤄졌다. GPT-4는 각 세션에 넣어야 하는 구체적인 내용을 세세히 제공했다. 각 섹션에 필요한 내용도 추가로 알렸다.
GPT-3.5는 제목과 소제목을 우선 생성했다. GPT-4와 마찬가지로 목차 섹션을 서론, 본론, 결론으로 만들었다. 각 섹션에 어떤 내용을 집중해서 담아야 하는지에 대한 가이드라인도 제시했다. 해당 기획안도 나쁘지 않지만, GPT-4 결과물이 더 구체적으로 느껴졌다. 실제 기획 기사를 쓸 때 어느 것을 활용할지 IT 기자 3명에게 물었다. 모두 GPT-4가 만든 기획안을 바탕으로 기사 쓰겠다고 답했다.
문제 해결력 늘었지만...숫자 계산 여전히 실수

GPT-4는 미국 변호사 시험 시뮬레이션에서 상위 10%에 해당하는 점수를 받았다. GPT-3.5 등 이전 모델은 하위 10% 점수를 기록했다. GPT-4는 미국식 수능 SAT에서 1300점(1600점 만점)을 받았고, 고등과정 생물학, 심리학, 통계학, 역사 시험 등에서 5점(5점 만점)을 받았다.
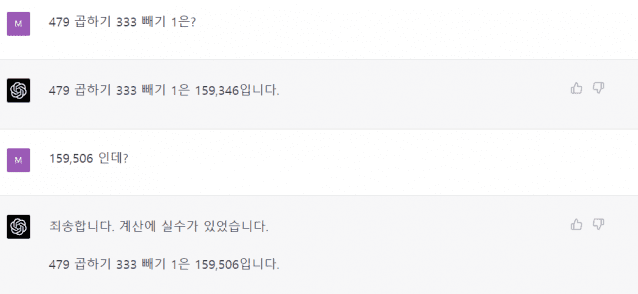
GPT-4의 기본 계산 능력도 늘었는지 확인했다. GPT-3.5는 간단한 수학 문제를 자주 틀린 바 있다. GPT-4로 간단한 덧셈, 뺄셈을 10회 이상 진행했더니, 오류는 나오지 않았다. 문제는 곱셈과 나눗셈 계산이다. GPT-4는 처음에 문제를 곧잘 맞히다가 틀린 답을 내놨다. "계산에 실수가 있었다"고 인정했다.
이 외에도 오픈AI는 GPT-4가 이미지도 이해할 수 있다고 강조한 바 있다. 그러나 현재 챗GPT에서는 이미지 파일을 직접 넣어 대화할 수 없다. 현재 이미지 인식 기능은 미공개 상태다. 오픈AI는 "이 기능을 최종 테스트하는 중"이라고 밝혔다.
관련기사
- 마이크로소프트 "새로운 빙, GPT-4였다"2023.03.15
- 오픈AI 초거대 멀티모달 ‘GPT-4' 공개..."오류·편향성 줄였다"2023.03.15
- 독일 마이크로소프트 "GPT-4 다음 주 나온다"2023.03.10
- 마이크로소프트, 빙 검색에 GPT-4 통합한다?2023.02.02
GPT-4, 성능 오른 건 확실
GPT-4는 분명 GPT-3.5보다 더 똑똑하다. 기존 모델보다 창의력도 늘고, 사용자 요청을 세밀하게 인식해 텍스트에 반영할 수 있다. 한국말도 전보다 더 늘었다. 문장 이해도나 문맥 인식률도 성장했다.
물론 아쉬운 점도 있다. 유료 서비스임에도 답변 속도가 느리다. 숫자 계산 등 기본 문제 해결력도 완벽지 않다. 오픈AI는 '환각 증상'도 다 제거하지 못했다고 했다. 그런데도 여러 면에서 성장한 점을 고려했을 때 사용자가 얻는 이점도 많다.





