



인공지능(AI)챗봇 발전이 3년 안에 정체될 수 있다는 연구 결과가 나왔다. AI 모델 훈련에 사용하는 고품질 언어 데이터 생산이 수요를 따라잡지 못해서다.
미국 AI 연구자 커뮤니티 '에포크'에서 활동하는 파블로 빌랄로보스 박사팀은 AI 챗봇에 필요한 고품질 언어 데이터 생성 속도와, 챗봇 훈련에 필요한 데이터량을 분석한 결과를 뉴사이언티스트가 7일(현지시간) 보도했다.

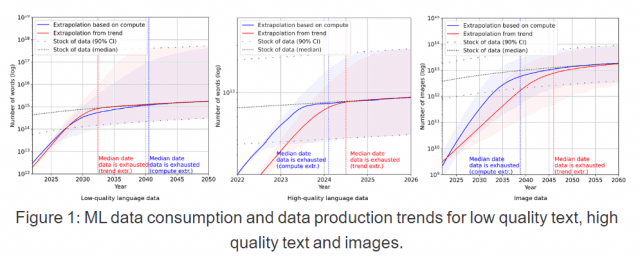
AI 챗봇 훈련에 필요한 언어 데이터셋 크기는 매년 약 50%씩 증가했다. 이대로 AI 챗봇이 꾸준히 발전하려면 새 언어 데이터량을 매해 50% 이상 늘려야 한다는 의미다. 그러나 훈련을 위해 사람이 만든 데이터 규모 증가율은 7%에 그친 것으로 나타났다.
연구팀은 "이 속도로는 챗GPT 같은 모델을 훈련시키는 데 사용되는 품질 높은 언어 데이터가 2026년에 고갈될 것이다"며 "언어 관련한 AI 기술 발전이 정체될 수 있다"고 경고했다. 반면 달리-2, 미드저니와 같은 이미지 생성AI에 필요한 이미지 데이터 고갈 확률은 낮게 봤다.
빌랄로보스 박사는 "품질 높은 언어 데이터 생성은 보통 책이나 과학 논문 등에서 인간이 직접 가져온다"며 "이때 드는 비용적·시간적 효율성이 크게 떨어져 지금과 같은 결과를 낳았다"고 강조했다.
반면 블로그나 웹사이트에서 가져온 텍스트에 기반한 데이터는 충분할 것이라고 덧붙였다. 상대적으로 품질이 낮을 경우 언어 데이터 생성 속도가 빠르기 때문이라는 이유에서다.
그러나 저품질 언어 데이터는 챗봇 모델 발전 속도를 더디게 할 수 있다. 연구팀은 "낮은 품질 데이터는 챗GPT 등 모델 발전 속도를 늦추고 오류, 윤리적 문제 등을 더 낳을 수 있다"고 지적했다.
이에 가브리엘 페레이라 런던정경대 객원교수는 "지금까지 고품질 데이터를 집중적으로 수집해 챗봇이나 생성AI 등 분야에 긍정적 결과를 얻은 것"이라며 "현대 AI 발전의 관건은 고품질 데이터 규모에 있다"고 강조했다.
빌랄로보스는 "AI 연구자들은 이러한 언어 데이터 생성 이슈를 해결해야 한다"며"그렇지 않으면 당장 3년 후 데이터 고갈을 맞이할 것이다"고 전했다.
해결법은

해결법이 아예 없지는 않다. 이론적으로 인간이 아닌 AI가 자체 생성한 언어 데이터를 모델에 넣어 데이터셋을 늘릴 수 있다.
예를 들어, AI 챗봇에 있는 언어 데이터를 다른 언어로 번역한 후 다시 기존 의미로 되돌리거나, 원본에 있는 단어를 동의어로 대체해 새로운 데이터셋으로 생성하는 식이다.
이에 대해 빌랄로보스는 "지금으로서는 유일한 해결책일 수 있다"고 말했다. 앤드류 헌트 AI독립연구원도 "현재 머신러닝, 딥러닝 등은 기존 데이터에서 새로운 데이터를 얻기 위해 지속적인 수정 작업을 거치고 있어 가능성 있는 해결법이다"고 뉴사이언티스트를 통해 입장을 밝혔다.
관련기사
- AI 챗봇 챗GPT, 악성코드 작성에도 쓰인다2023.01.10
- "회의 때 이런 말 하세요" 추천해주는 AI 챗봇 등장2022.12.24
- AI챗봇으로 숙제를...학계 "학문 발전 저해" 우려2022.12.19
- 세계가 '챗GPT'에 열광하는 이유는2022.12.27
그러나 연구팀을 비롯한 전문가들은 "AI가 직접 생성·수정한 데이터셋을 사용하는 건 위험하다"고 입을 모았다. 언어 수정 중 발생할 수 있는 의미 왜곡, 오류, 편향이 복합적으로 생길 수 있다는 이유에서다.
앤드류 헌트는 "데이터 부족 현상은 현재 고품질 언어 데이터에만 한정된 상태다"며 "지금부터라도 해결책을 찾아 향후 AI 발전에 미치는 영향을 줄여야 한다"고 전했다.





