마인즈랩이 개발해 온 다국어 인공지능(AI) 휴먼 관련 논문이 컴퓨터 비전과 패턴 인식 컨퍼런스 2022(CVPR 2022) 데모 트랙에 채택되었다고 27일 밝혔다.
CVPR는 컴퓨터 비전 및 머신러닝/딥러닝 분야 세계 최대 국제학술대회다.
이번 논문을 통해 공개된 ‘다국어 AI 휴먼’ 기술은 타사 기술과 달리 특정 인물의 발화 특성, 얼굴 움직임 등을 그대로 유지한 채 음성 생성과 영상 생성을 동시에 진행하며, 특히 2시간의 한국어 데이터만으로 4개 국어를 발화하도록 하는 기술은 세계 최초다.
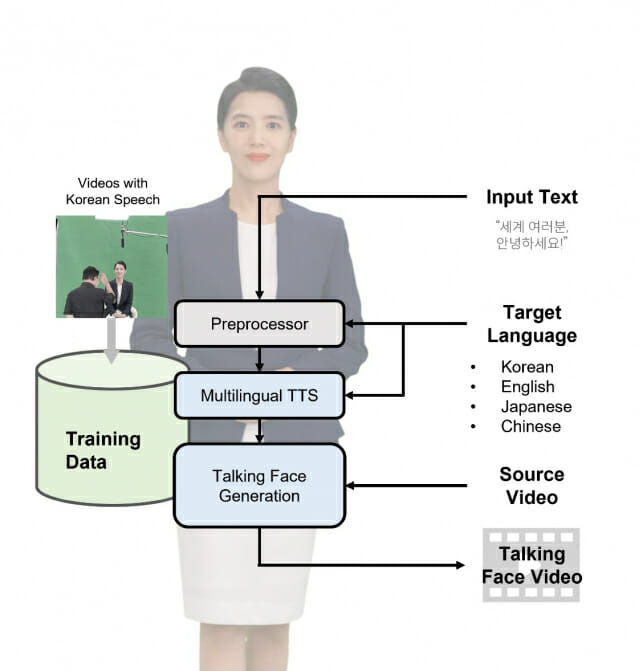
논문에서는 특정 인물의 발화적 특성을 유지한 채 다국어 음성을 생성할 수 있는 다국어 음성생성(TTS) 기술과 다국어 음성을 발화하는 인물 영상을 생성(Talking Face Generation)하는 기술을 기반으로 다국어 발화 영상 생성 데모를 보여준다.
이를 통해 사용자는 한국어, 영어, 중국어, 일어 4개 국어 중 하나의 언어로 된 텍스트를 입력하기만 하면, 해당 텍스트를 발화하는 영상을 손쉽게 얻을 수 있다.
특히, 이번에 공개한 시스템은 고성능 GPU를 탑재한 데스크톱 환경에서 초당 30장의 이미지를 생성하는 성능을 보여준다.
또한 데모 논문으로 선정된 다국어 AI Human 관련 논문과는 별도로 마인즈랩 소속 연구원이 참여한 트랜스포머(Transformer) 기반 이미지 생성 모델 연구 논문 역시 CVPR 논문으로 채택되었다.
이 연구는 기존의 적대적 신경 생성망 중 대표적인 StyleGAN 모델과 최근 컴퓨터 비전 쪽에서 활발히 연구되고 있는 트랜스포머(Transformer) 모델의 장점을 결합하여 스타일포머라는 모델을 새롭게 제시한 것으로, 기존 다른 딥러닝 모델들로 생성한 이미지보다 프레쳇 인셉션 거리(FID) 를 기준으로 더 좋은 성능을 보여주었다.
마인즈랩은 2020년부터 음성, 이미지, 영상과 관련된 논문이 인터스피치, 뉴립스 등 머신러닝/딥러닝 분야 국제학술대회 및 위성학회에 지속적으로 채택되는 등 인공지능 분야의 연구 성과를 지속적으로 이어가고 있다.
2022년에 들어서는 CVPR 학회뿐만 아니라 신호처리 학회인 ICASSP에 음성변환(Voice Conversion)과 관련된 독자 연구가 채택되었고, 최근 PR 등 저널에도 이미지 인식 관련 논문이 채택되었다.
마인즈랩 연구팀 송형규 수석연구원은 "이번 연구를 시작으로 앞으로도 고품질의 이미지 생성 연구를 통해 더욱 더 사람 같은 AI 휴먼을 만들어 나갈 것"이라고 밝혔다.
CVPR은 오는 6월 19일부터 24일(금)까지 미국 루이지애나주 뉴올리언스에서 개최된다.